CompoST: A Benchmark for Analyzing the Ability of LLMs To Compositionally Interpret Questions in a QALD Setting
作者: David Maria Schmidt, Raoul Schubert, Philipp Cimiano
分类: cs.AI, cs.CL
发布日期: 2025-07-28 (更新: 2025-10-30)
备注: Research Track, 24th International Semantic Web Conference (ISWC 2025), November 2-6, 2025, Nara, Japan
DOI: 10.1007/978-3-032-09527-5_1
💡 一句话要点
CompoST:评估LLM在QALD环境中组合性理解问题的基准测试
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 组合性理解 问答系统 SPARQL查询 基准测试 自然语言处理 知识图谱
📋 核心要点
- 现有大型语言模型在将自然语言问题转换为SPARQL查询方面表现出色,但其组合性理解能力尚不明确。
- 论文提出CompoST基准,通过控制数据生成过程,评估LLM在已知原子组件的情况下,对复杂结构问题的组合性理解能力。
- 实验结果表明,LLM在组合性理解方面存在困难,即使提供所有必要信息,性能也难以达到理想水平。
📝 摘要(中文)
语言理解是一个组合过程,复杂语言结构的含义是从其组成部分的含义推断出来的。大型语言模型(LLM)具有卓越的语言理解能力,并已成功应用于通过将问题映射到SPARQL查询来解释问题。一个悬而未决的问题是这种解释过程的系统性如何。为了解决这个问题,本文提出了一个基准,用于研究LLM解释问题的能力在多大程度上是组合性的。为此,我们基于DBpedia中的图模式生成了三个不同难度的数据集,并依赖Lemon词汇进行口头表达。我们的数据集以非常受控的方式创建,以便在LLM已经见过原子构建块的情况下,测试LLM解释结构复杂问题的能力。这使我们能够评估LLM在多大程度上能够解释它们“理解”原子部分的复杂问题。我们使用各种提示和少样本优化技术以及微调,对不同规模的模型进行了实验。结果表明,随着与优化样本的偏差增加,宏观$F_1$值的性能从$0.45$降至$0.26$再降至$0.09$。即使在输入中向模型提供了所有必要信息,对于复杂度最低的数据集,$F_1$分数也不超过$0.57$。因此,我们得出结论,LLM难以系统地和组合性地解释问题并将它们映射到SPARQL查询。
🔬 方法详解
问题定义:论文旨在评估大型语言模型(LLM)在问答系统(QALD)中,对具有组合性结构的问题的理解能力。现有方法虽然在简单问题上表现良好,但缺乏对复杂、组合性问题的系统性评估,难以判断LLM是否真正理解了问题的结构和语义。
核心思路:核心思路是构建一个可控的基准数据集,其中问题的复杂性通过组合原子语义单元来逐步增加。通过观察LLM在不同复杂程度问题上的表现,可以评估其组合性理解能力。关键在于确保LLM已经“见过”所有原子单元,从而排除LLM缺乏基本知识的可能性。
技术框架:整体框架包括三个主要步骤:1) 基于DBpedia的图模式生成不同复杂度的SPARQL查询;2) 使用Lemon词汇将SPARQL查询转化为自然语言问题,形成数据集;3) 使用不同规模的LLM,结合不同的prompting和fine-tuning策略,在数据集上进行实验,评估其性能。
关键创新:关键创新在于数据集的构建方式。CompoST数据集通过控制图模式的组合方式,系统性地增加问题的复杂性,从而能够更精确地评估LLM的组合性理解能力。此外,数据集的构建过程保证了LLM已经见过所有原子语义单元,排除了知识缺失的影响。
关键设计:数据集包含三个难度级别,分别对应不同复杂度的图模式组合。实验中使用了不同规模的LLM,并尝试了多种prompting策略(如zero-shot、few-shot)和fine-tuning方法。评估指标主要采用宏观$F_1$值,以衡量模型在不同类别上的平均性能。
🖼️ 关键图片
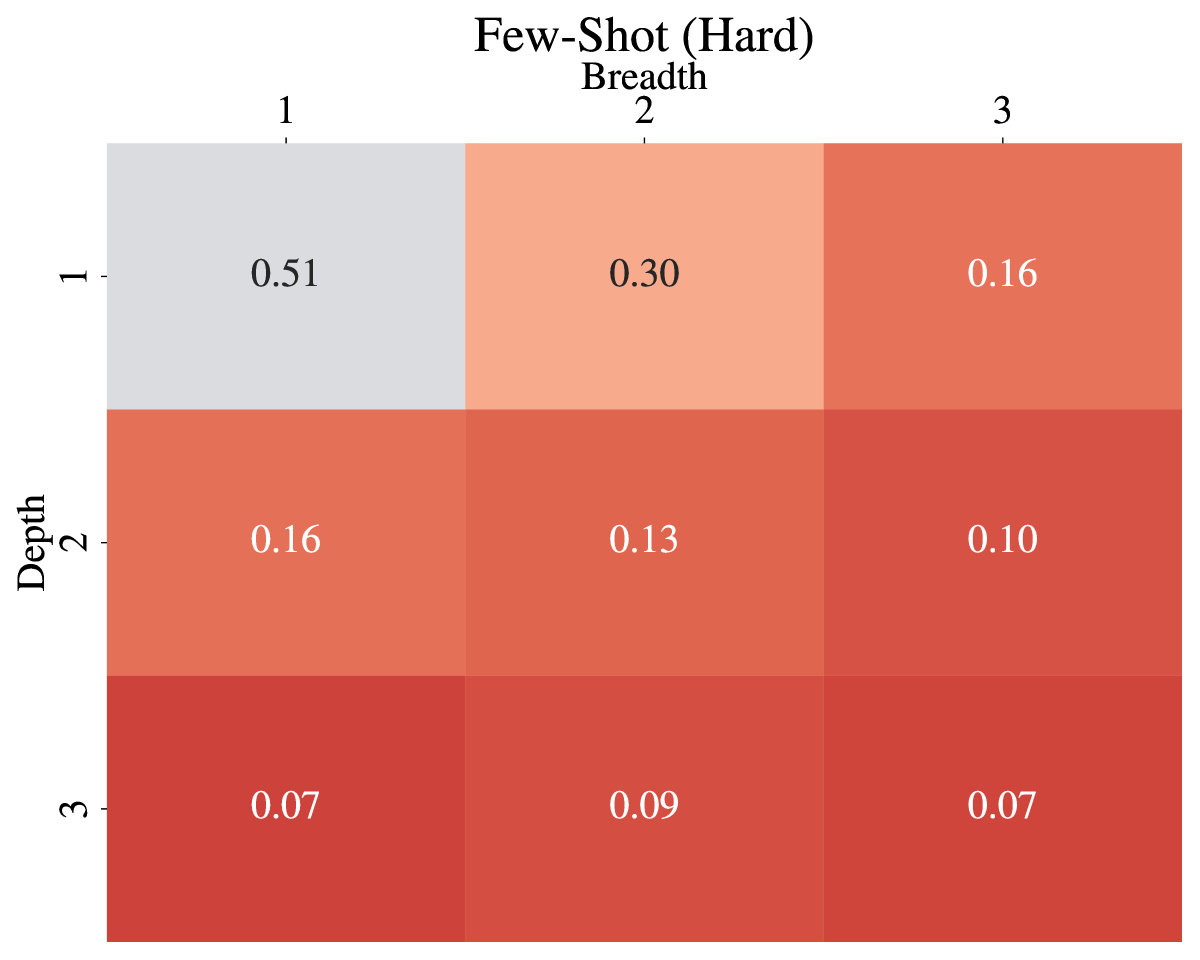
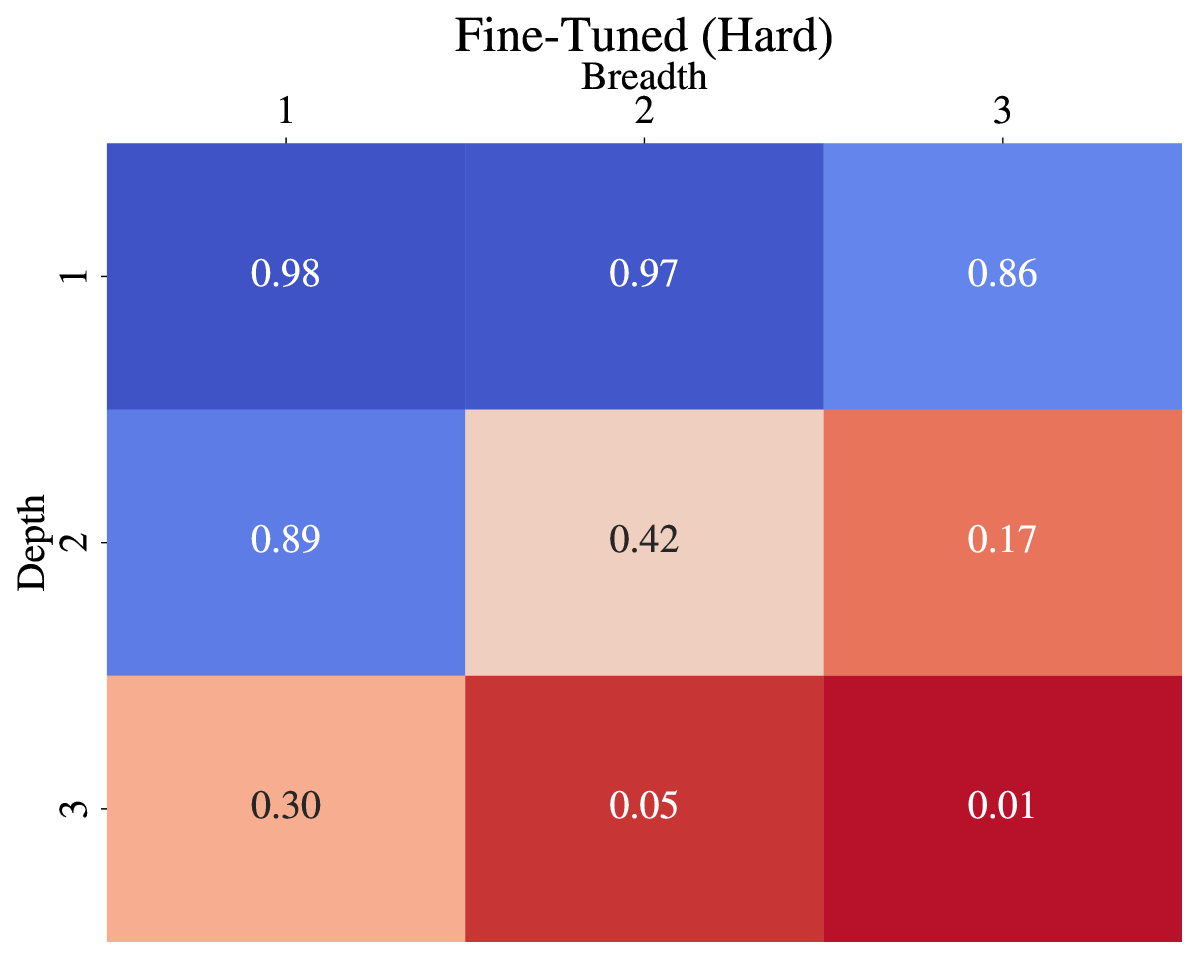

📊 实验亮点
实验结果表明,随着问题复杂度的增加,LLM的性能显著下降。即使在复杂度最低的数据集上,提供所有必要信息的情况下,$F_1$值也仅为$0.57$。在优化样本上训练的模型,随着与优化样本的偏差增加,宏观$F_1$值从$0.45$降至$0.09$,表明LLM在组合性理解方面存在显著的局限性。
🎯 应用场景
该研究成果可应用于提升问答系统、语义搜索等应用的性能。通过更准确地评估和提升LLM的组合性理解能力,可以构建更智能、更可靠的自然语言处理系统。未来,该研究方向有助于开发能够处理复杂逻辑推理和知识组合的应用,例如智能助手、知识图谱问答等。
📄 摘要(原文)
Language interpretation is a compositional process, in which the meaning of more complex linguistic structures is inferred from the meaning of their parts. Large language models possess remarkable language interpretation capabilities and have been successfully applied to interpret questions by mapping them to SPARQL queries. An open question is how systematic this interpretation process is. Toward this question, in this paper, we propose a benchmark for investigating to what extent the abilities of LLMs to interpret questions are actually compositional. For this, we generate three datasets of varying difficulty based on graph patterns in DBpedia, relying on Lemon lexica for verbalization. Our datasets are created in a very controlled fashion in order to test the ability of LLMs to interpret structurally complex questions, given that they have seen the atomic building blocks. This allows us to evaluate to what degree LLMs are able to interpret complex questions for which they "understand" the atomic parts. We conduct experiments with models of different sizes using both various prompt and few-shot optimization techniques as well as fine-tuning. Our results show that performance in terms of macro $F_1$ degrades from $0.45$ over $0.26$ down to $0.09$ with increasing deviation from the samples optimized on. Even when all necessary information was provided to the model in the input, the $F_1$ scores do not exceed $0.57$ for the dataset of lowest complexity. We thus conclude that LLMs struggle to systematically and compositionally interpret questions and map them into SPARQL queries.