JAM: A Tiny Flow-based Song Generator with Fine-grained Controllability and Aesthetic Alignment
作者: Renhang Liu, Chia-Yu Hung, Navonil Majumder, Taylor Gautreaux, Amir Ali Bagherzadeh, Chuan Li, Dorien Herremans, Soujanya Poria
分类: cs.SD, cs.AI
发布日期: 2025-07-28
备注: https://github.com/declare-lab/jamify
💡 一句话要点
JAM:一种基于Flow的小型歌曲生成器,具备细粒度可控性和美学对齐能力
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 歌词到歌曲生成 Flow-Matching模型 细粒度控制 美学对齐 直接偏好优化
📋 核心要点
- 现有歌词到歌曲生成模型缺乏细粒度的词级别控制,限制了音乐家在创作过程中的灵活度。
- JAM通过Flow-Matching模型,首次实现了歌曲生成中词级别的时间和持续时间控制,提升了声音控制的精细度。
- 通过直接偏好优化和合成数据集,JAM实现了美学对齐,无需手动标注数据,并优于现有模型。
📝 摘要(中文)
扩散模型和Flow-Matching模型彻底改变了近期的自动文本到音频生成领域。这些模型越来越能够生成高质量和逼真的音频输出,捕捉语音和声学事件。然而,在主要涉及音乐和歌曲的创意音频生成方面,仍有很大的改进空间。最近的开放式歌词到歌曲模型,如DiffRhythm、ACE-Step和LeVo,已经在娱乐用途的自动歌曲生成方面设定了一个可接受的标准。然而,这些模型缺乏音乐家在工作流程中经常需要的细粒度词级可控性。据我们所知,我们基于Flow-Matching的JAM是首次尝试在歌曲生成中赋予词级时间和持续时间控制,从而实现细粒度的声音控制。为了提高生成歌曲的质量,使其更好地与人类偏好对齐,我们通过直接偏好优化来实现美学对齐,该优化使用合成数据集迭代地改进模型,从而消除了手动数据注释的需要。此外,我们旨在通过我们的公共评估数据集JAME来标准化此类歌词到歌曲模型的评估。我们表明,JAM在特定于音乐的属性方面优于现有模型。
🔬 方法详解
问题定义:现有歌词到歌曲生成模型,例如DiffRhythm、ACE-Step和LeVo,虽然在生成质量上取得了一定的进展,但缺乏对生成歌曲的细粒度控制,特别是词级别的时间和持续时间控制。这使得音乐家难以精确控制歌曲的节奏和韵律,限制了创作的灵活性。现有方法主要关注整体音乐结构的生成,而忽略了对单个词语发音时长的控制。
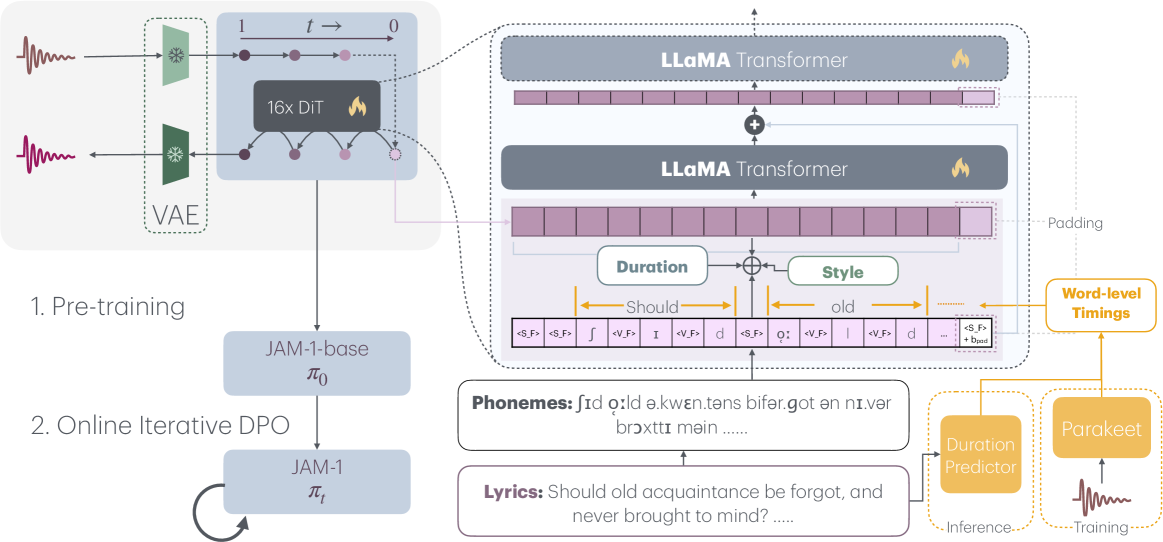
核心思路:JAM的核心思路是利用Flow-Matching模型,将歌词的文本信息映射到音频的声学特征,并在映射过程中引入对词级别时间和持续时间的控制。通过这种方式,模型可以根据用户指定的词语时长,生成具有相应节奏和韵律的歌曲。此外,为了使生成的歌曲更符合人类的审美偏好,JAM还采用了直接偏好优化(Direct Preference Optimization, DPO)方法,通过合成数据集来训练模型,使其能够生成更具吸引力的音乐。
技术框架:JAM的整体框架包含歌词输入模块、Flow-Matching生成模块和美学对齐模块。首先,歌词输入模块将歌词文本转换为模型可处理的向量表示。然后,Flow-Matching生成模块根据歌词向量和用户指定的词语时长信息,生成对应的音频声学特征。最后,美学对齐模块使用DPO方法,根据合成数据集对生成模块进行微调,使其生成的歌曲更符合人类的审美偏好。JAME数据集用于评估。
关键创新:JAM的关键创新在于首次在歌词到歌曲生成中实现了词级别的时间和持续时间控制。与现有方法相比,JAM能够让用户更精确地控制歌曲的节奏和韵律,从而实现更个性化的音乐创作。此外,JAM采用的DPO方法,通过合成数据集实现了美学对齐,避免了手动标注数据的繁琐过程,提高了模型的训练效率。
关键设计:JAM使用Flow-Matching模型作为其核心生成模块。Flow-Matching是一种生成模型,它通过学习数据分布之间的连续变换,实现从噪声到数据的生成过程。在JAM中,Flow-Matching模型学习从歌词向量和时长信息到音频声学特征的映射。DPO损失函数用于美学对齐,它鼓励模型生成更符合人类偏好的歌曲。合成数据集包含大量不同风格和节奏的歌曲,用于训练DPO模型。
🖼️ 关键图片
📊 实验亮点
实验结果表明,JAM在音乐特定属性方面优于现有模型。通过JAME数据集的评估,JAM在节奏准确性、旋律流畅性和整体音乐质量方面都取得了显著提升。与DiffRhythm、ACE-Step和LeVo等基线模型相比,JAM生成的歌曲更符合人类的审美偏好,并且具有更高的可控性。
🎯 应用场景
JAM可应用于音乐创作辅助、个性化歌曲生成、音乐教育等领域。音乐家可以使用JAM快速生成歌曲草稿,并进行细致的调整和修改。普通用户可以通过指定歌词和节奏,生成个性化的歌曲。音乐教育者可以使用JAM来教授学生关于歌曲结构和节奏的知识。未来,JAM有望成为音乐创作领域的重要工具。
📄 摘要(原文)
Diffusion and flow-matching models have revolutionized automatic text-to-audio generation in recent times. These models are increasingly capable of generating high quality and faithful audio outputs capturing to speech and acoustic events. However, there is still much room for improvement in creative audio generation that primarily involves music and songs. Recent open lyrics-to-song models, such as, DiffRhythm, ACE-Step, and LeVo, have set an acceptable standard in automatic song generation for recreational use. However, these models lack fine-grained word-level controllability often desired by musicians in their workflows. To the best of our knowledge, our flow-matching-based JAM is the first effort toward endowing word-level timing and duration control in song generation, allowing fine-grained vocal control. To enhance the quality of generated songs to better align with human preferences, we implement aesthetic alignment through Direct Preference Optimization, which iteratively refines the model using a synthetic dataset, eliminating the need or manual data annotations. Furthermore, we aim to standardize the evaluation of such lyrics-to-song models through our public evaluation dataset JAME. We show that JAM outperforms the existing models in terms of the music-specific attributes.