StepFun-Prover Preview: Let's Think and Verify Step by Step
作者: Shijie Shang, Ruosi Wan, Yue Peng, Yutong Wu, Xiong-hui Chen, Jie Yan, Xiangyu Zhang
分类: cs.AI
发布日期: 2025-07-27 (更新: 2025-08-13)
备注: Added links to GitHub and Hugging Face
💡 一句话要点
StepFun-Prover Preview:提出工具集成推理的大语言模型,用于形式化定理证明。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 形式化定理证明 大型语言模型 工具集成推理 强化学习 Lean 4
📋 核心要点
- 现有定理证明方法缺乏有效的工具集成,难以模拟人类专家利用外部工具进行验证和探索的过程。
- StepFun-Prover通过强化学习,结合工具反馈迭代优化证明过程,模仿人类逐步思考和验证的策略。
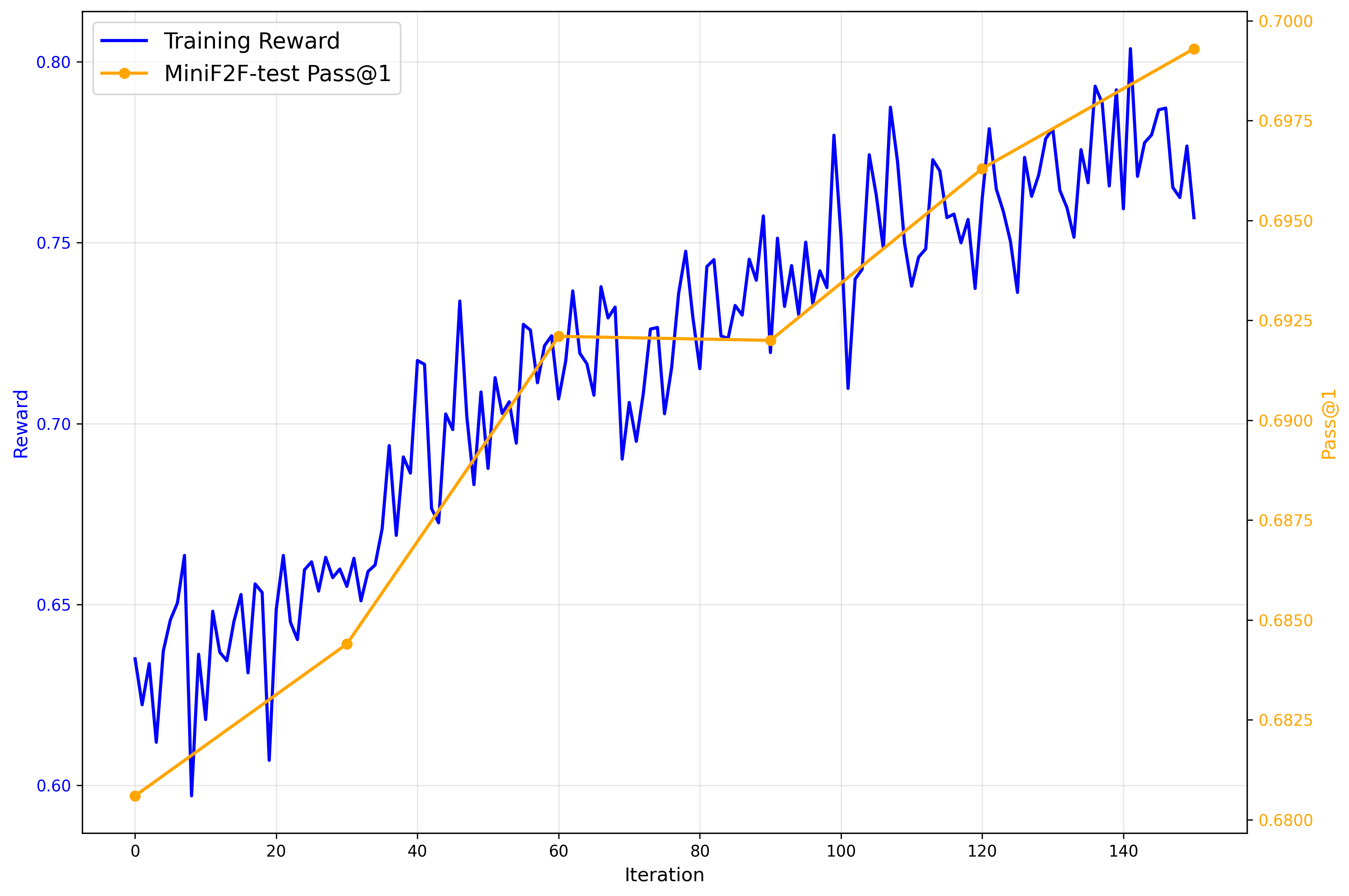
- 在miniF2F-test上,StepFun-Prover的pass@1成功率达到70.0%,展示了工具集成推理在定理证明中的潜力。
📝 摘要(中文)
本文介绍StepFun-Prover Preview,一个通过工具集成推理设计用于形式化定理证明的大语言模型。通过结合工具交互的强化学习流程,StepFun-Prover能够以最小的采样量在生成Lean 4证明方面取得优异的性能。该方法使模型能够通过基于实时环境反馈迭代地改进证明,从而模拟类人的问题解决策略。在miniF2F-test基准测试中,StepFun-Prover实现了70.0%的pass@1成功率。除了提升基准性能外,我们还引入了一个端到端的训练框架,用于开发工具集成推理模型,为自动化定理证明和数学AI助手提供了一个有希望的方向。
🔬 方法详解
问题定义:论文旨在解决形式化定理证明问题,特别是如何利用大型语言模型自动生成Lean 4证明。现有方法通常依赖于大量数据或复杂的模型结构,且缺乏与外部工具的有效集成,难以模拟人类专家在证明过程中使用工具进行验证和探索的习惯。这导致证明效率低下,且难以处理复杂问题。
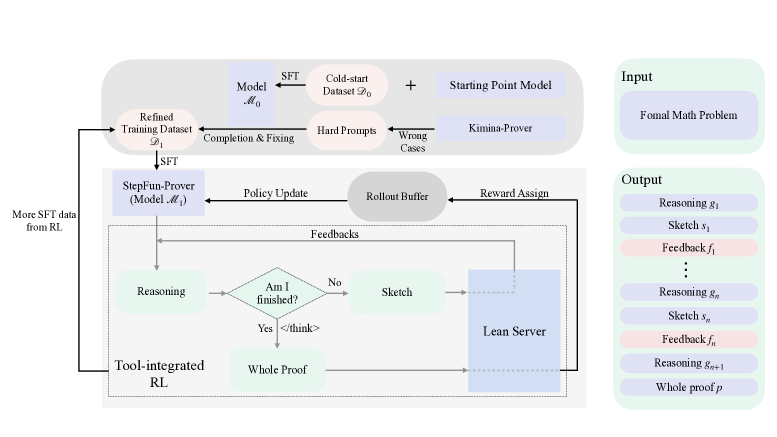
核心思路:StepFun-Prover的核心思路是利用强化学习,训练一个能够与Lean 4证明环境交互的大型语言模型。模型通过生成证明步骤,并从Lean 4环境获得反馈(例如,证明是否有效,当前状态等),从而迭代地改进证明策略。这种方法模仿了人类专家在证明过程中不断尝试、验证和修正的策略。
技术框架:StepFun-Prover采用一个端到端的训练框架,主要包括以下几个模块:1) 大型语言模型:作为证明步骤的生成器;2) Lean 4证明环境:提供实时的证明状态和反馈;3) 强化学习算法:根据环境反馈优化语言模型的策略。整个流程如下:模型生成证明步骤 -> Lean 4环境执行该步骤并返回反馈 -> 强化学习算法根据反馈更新模型参数 -> 模型生成新的证明步骤,循环往复直到证明完成或达到最大步数。
关键创新:StepFun-Prover的关键创新在于将大型语言模型与形式化证明工具紧密结合,通过强化学习实现工具集成推理。与以往方法相比,StepFun-Prover能够更好地利用外部工具的验证能力,从而提高证明效率和成功率。此外,该论文提出了一个端到端的训练框架,为开发工具集成推理模型提供了一个通用的解决方案。
关键设计:论文中强化学习算法的具体选择未知,但可以推测使用了某种策略梯度方法,例如PPO或REINFORCE,来优化语言模型的策略。损失函数的设计需要考虑证明的有效性、效率以及与环境的交互成本。具体的网络结构未知,但可以推测使用了Transformer架构,并针对形式化证明任务进行了微调。关键参数设置包括学习率、折扣因子、探索率等,这些参数需要根据具体实验进行调整。
🖼️ 关键图片

📊 实验亮点
StepFun-Prover在miniF2F-test基准测试中取得了显著的成果,pass@1成功率达到70.0%。这一结果表明,通过工具集成推理,大型语言模型在形式化定理证明方面具有巨大的潜力。该性能超越了现有方法,为自动化定理证明领域带来了新的突破。
🎯 应用场景
StepFun-Prover具有广泛的应用前景,包括自动化定理证明、数学AI助手、软件验证等领域。它可以帮助数学家和计算机科学家更高效地进行形式化验证,提高软件的可靠性和安全性。未来,该技术有望应用于教育领域,辅助学生学习数学和逻辑推理。
📄 摘要(原文)
We present StepFun-Prover Preview, a large language model designed for formal theorem proving through tool-integrated reasoning. Using a reinforcement learning pipeline that incorporates tool-based interactions, StepFun-Prover can achieve strong performance in generating Lean 4 proofs with minimal sampling. Our approach enables the model to emulate human-like problem-solving strategies by iteratively refining proofs based on real-time environment feedback. On the miniF2F-test benchmark, StepFun-Prover achieves a pass@1 success rate of $70.0\%$. Beyond advancing benchmark performance, we introduce an end-to-end training framework for developing tool-integrated reasoning models, offering a promising direction for automated theorem proving and Math AI assistant.