Improving the Performance of Sequential Recommendation Systems with an Extended Large Language Model
作者: Sinnyum Choi, Woong Kim
分类: cs.IR, cs.AI, cs.CL
发布日期: 2025-07-26
💡 一句话要点
通过扩展大型语言模型Llama3,提升序列推荐系统性能
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 序列推荐 大型语言模型 Llama3 模型替换 推荐系统 性能提升 个性化推荐
📋 核心要点
- 现有基于LLM的推荐系统未能充分利用最新LLM的语言理解和推理能力。
- 通过在LlamaRec框架中直接替换LLM,探索最新LLM对推荐性能的提升。
- 实验表明,替换Llama3后,在多个数据集上性能显著提升,验证了该方法的有效性。
📝 摘要(中文)
近年来,各大科技公司在人工智能领域的竞争日益激烈,不断涌现出具备更强语言理解和基于上下文推理能力的大型语言模型(LLMs)。这些进步有望通过提高训练数据质量和架构设计,在基于LLM的推荐系统中实现更高效的个性化推荐。然而,许多研究尚未考虑这些最新进展。本研究旨在通过在LlamaRec框架中将Llama2替换为Llama3来改进基于LLM的推荐系统。为了确保公平比较,在预处理和训练过程中设置了随机种子值并提供了相同的输入数据。实验结果表明,ML-100K、Beauty和Games数据集的平均性能分别提高了38.65%、8.69%和8.19%,从而证实了该方法的实用性。值得注意的是,模型替换所取得的显著改进表明,无需对系统进行结构性更改即可经济高效地提高推荐质量。基于这些结果,我们认为所提出的方法是改进当前推荐系统的可行解决方案。
🔬 方法详解
问题定义:论文旨在解决序列推荐系统中,如何利用最新大型语言模型(LLM)提升推荐性能的问题。现有方法可能由于LLM版本较旧,未能充分利用LLM在语言理解和上下文推理方面的最新进展,导致推荐效果存在提升空间。
核心思路:论文的核心思路是直接将现有推荐系统框架(LlamaRec)中的LLM替换为更新、更强大的LLM(Llama3),从而在不改变系统结构的前提下,利用新LLM的优势提升推荐性能。这种方法简单直接,易于实施,且成本相对较低。
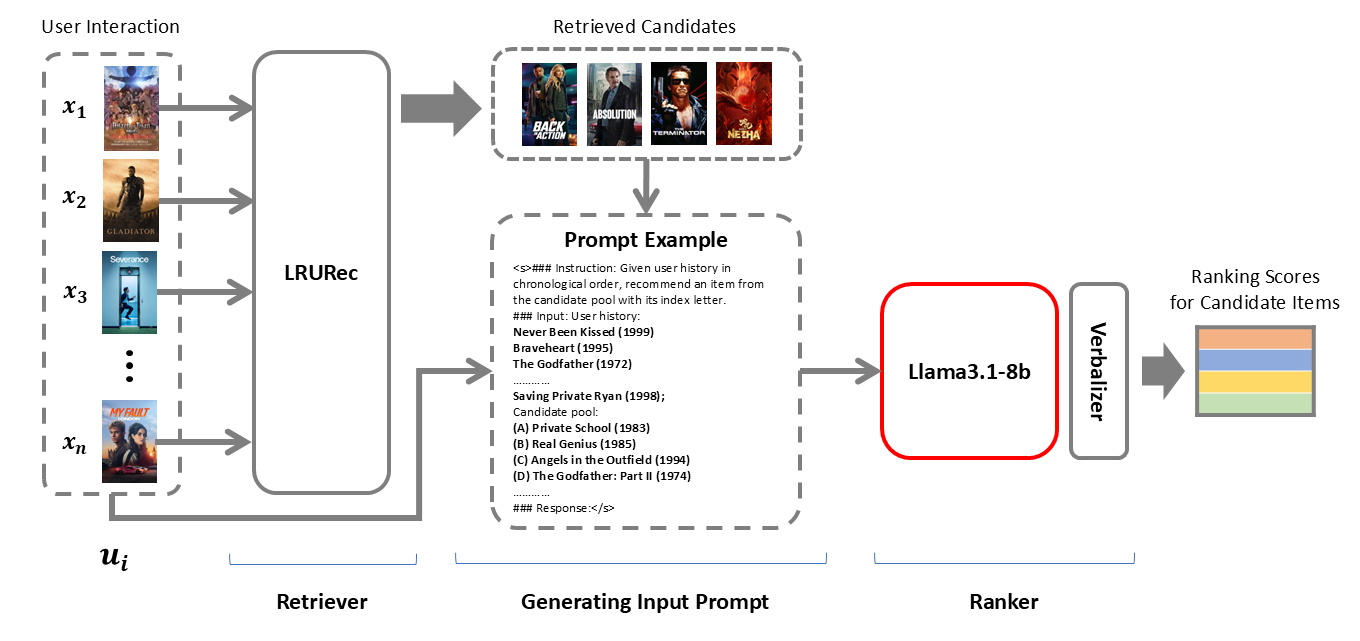
技术框架:论文采用LlamaRec框架,该框架基于LLM进行序列推荐。具体流程包括:数据预处理(将用户历史行为序列转换为LLM可理解的文本格式)、模型训练(使用替换后的LLM进行训练)和推荐生成。关键在于直接替换LlamaRec框架中的Llama2模型为Llama3模型。
关键创新:论文最重要的创新点在于验证了直接替换LLM在现有推荐系统中的有效性。与需要重新设计模型结构或引入复杂训练技巧的方法不同,该方法无需进行大规模的系统改造,即可获得显著的性能提升。这表明LLM本身的进步对推荐系统性能具有重要影响。
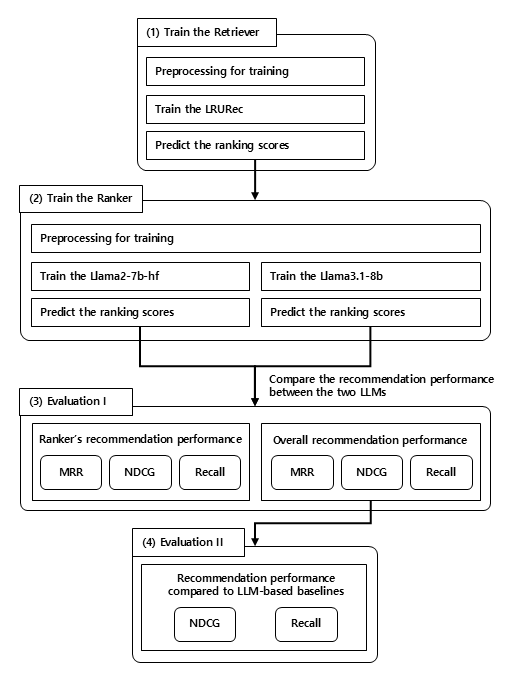
关键设计:为了保证实验的公平性,论文在预处理和训练过程中使用了相同的输入数据和随机种子。实验评估了在ML-100K、Beauty和Games等数据集上的推荐性能,并与使用Llama2的模型进行了对比。具体的损失函数和网络结构沿用了LlamaRec框架的设计,重点关注替换LLM带来的性能提升。
🖼️ 关键图片

📊 实验亮点
实验结果显示,在ML-100K数据集上,替换Llama3后,推荐性能平均提升了38.65%;在Beauty和Games数据集上,分别提升了8.69%和8.19%。这些显著的性能提升表明,通过简单地替换LLM,可以在不改变系统结构的前提下,有效地提高推荐系统的性能。
🎯 应用场景
该研究成果可应用于各种在线推荐系统,例如电商、视频平台、音乐应用等。通过简单地替换底层LLM,可以快速提升推荐系统的性能,从而提高用户满意度和平台收益。该方法也为后续研究提供了思路,即关注LLM本身的进步,而非过度依赖复杂的模型结构设计。
📄 摘要(原文)
Recently, competition in the field of artificial intelligence (AI) has intensified among major technological companies, resulting in the continuous release of new large-language models (LLMs) that exhibit improved language understanding and context-based reasoning capabilities. It is expected that these advances will enable more efficient personalized recommendations in LLM-based recommendation systems through improved quality of training data and architectural design. However, many studies have not considered these recent developments. In this study, it was proposed to improve LLM-based recommendation systems by replacing Llama2 with Llama3 in the LlamaRec framework. To ensure a fair comparison, random seed values were set and identical input data was provided during preprocessing and training. The experimental results show average performance improvements of 38.65\%, 8.69\%, and 8.19\% for the ML-100K, Beauty, and Games datasets, respectively, thus confirming the practicality of this method. Notably, the significant improvements achieved by model replacement indicate that the recommendation quality can be improved cost-effectively without the need to make structural changes to the system. Based on these results, it is our contention that the proposed approach is a viable solution for improving the performance of current recommendation systems.