The Impact of Fine-tuning Large Language Models on Automated Program Repair
作者: Roman Macháček, Anastasiia Grishina, Max Hort, Leon Moonen
分类: cs.SE, cs.AI, cs.CL, cs.LG
发布日期: 2025-07-26
备注: Accepted for publication in the research track of the 41th International Conference on Software Maintenance and Evolution (ICSME 2025)
💡 一句话要点
研究微调大型语言模型对自动化程序修复性能的影响,并提出参数高效微调策略。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 自动化程序修复 参数高效微调 代码生成 软件工程
📋 核心要点
- 现有APR工具中,直接应用大型语言模型训练成本高昂,且模型在特定任务上的适应性存在挑战。
- 论文探索了全量微调和参数高效微调(PEFT)策略,旨在降低计算成本的同时提升LLM在APR任务中的性能。
- 实验表明,全量微调可能因过拟合降低性能,而参数高效微调能有效提升模型在APR基准测试中的表现。
📝 摘要(中文)
本文实证研究了各种微调技术对用于自动化程序修复(APR)的大型语言模型(LLM)性能的影响。由于LLM在性能和灵活性方面的优势,它们在APR工具链中越来越受欢迎。然而,训练这些模型需要大量的资源。微调技术已被开发出来,用于将预训练的LLM适应于特定的任务,例如APR,并以远低于从头开始训练的计算成本来提高它们的性能。本文评估了六种不同参数规模的预训练代码LLM(CodeGen、CodeT5、StarCoder、DeepSeekCoder、Bloom和CodeLlama-2)在三个流行的APR基准(QuixBugs、Defects4J和HumanEval-Java)上的表现,并考虑了三种训练方案:不进行微调、完全微调以及使用LoRA和IA3的参数高效微调(PEFT)。研究表明,完全微调技术由于不同的数据分布和过拟合,降低了各种模型的基准测试性能。通过使用参数高效的微调方法,限制模型中可训练参数的数量,可以获得更好的结果。
🔬 方法详解
问题定义:论文旨在解决如何高效地将大型语言模型应用于自动化程序修复(APR)任务的问题。现有方法,特别是从头开始训练LLM,需要巨大的计算资源。直接使用预训练模型可能无法充分适应APR任务的特定数据分布和需求。全量微调虽然可以使模型适应特定任务,但容易过拟合,导致在基准测试中的性能下降。
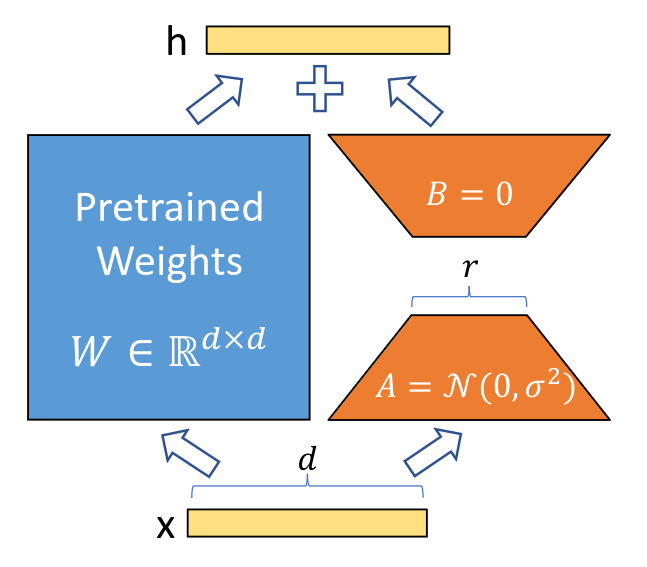
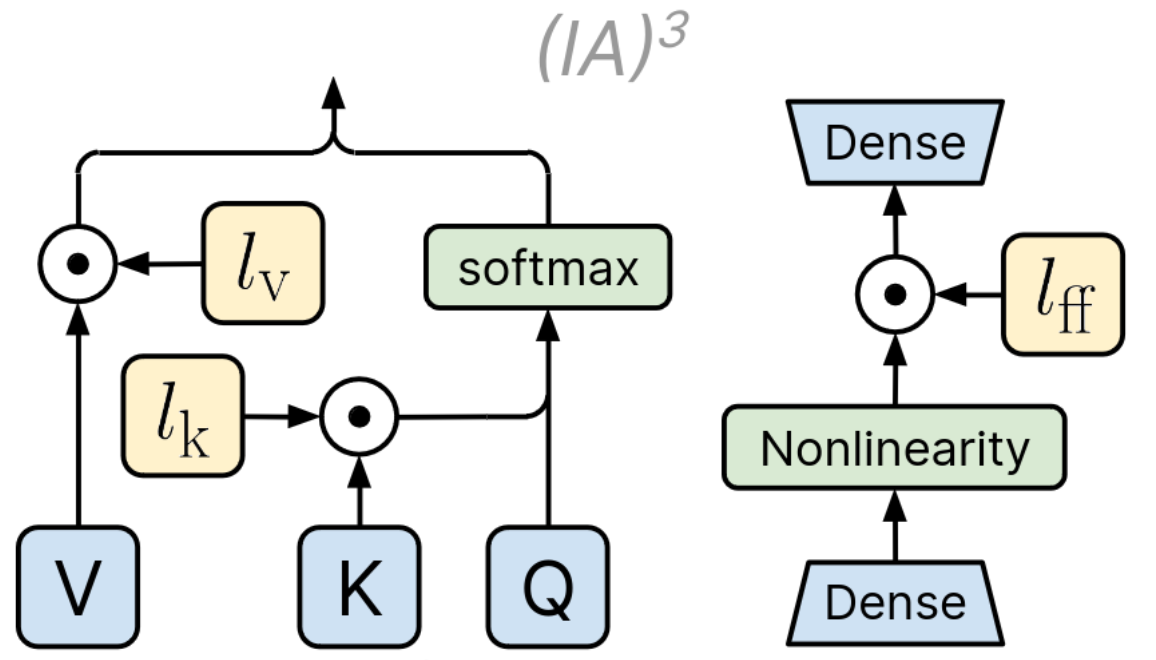
核心思路:论文的核心思路是探索参数高效微调(PEFT)技术,例如LoRA和IA3,以在计算资源有限的情况下,使LLM更好地适应APR任务。通过限制可训练参数的数量,PEFT方法可以降低过拟合的风险,并提高模型的泛化能力。
技术框架:论文的整体框架包括以下步骤:1)选择六种预训练的代码LLM(CodeGen、CodeT5、StarCoder、DeepSeekCoder、Bloom和CodeLlama-2);2)在三个APR基准数据集(QuixBugs、Defects4J和HumanEval-Java)上进行评估;3)采用三种训练方案:不进行微调、全量微调和使用LoRA/IA3的PEFT;4)比较不同训练方案下模型的性能,并分析结果。
关键创新:论文的关键创新在于系统性地研究了不同微调策略(包括全量微调和PEFT)对LLM在APR任务中的影响。通过实验,论文揭示了全量微调可能导致性能下降,而PEFT方法能够更有效地提升模型性能。此外,论文还比较了不同PEFT方法的性能差异。
关键设计:论文的关键设计包括:1)选择具有不同参数规模的LLM,以评估模型规模对微调效果的影响;2)采用LoRA和IA3作为PEFT的代表性方法,并比较它们的性能;3)使用三个广泛使用的APR基准数据集,以确保评估结果的可靠性和可比性;4)仔细控制实验参数,例如学习率、batch size等,以确保实验结果的有效性。
🖼️ 关键图片

📊 实验亮点
实验结果表明,全量微调在某些情况下会降低LLM在APR基准测试中的性能,而参数高效微调(PEFT)方法,如LoRA和IA3,能够更有效地提升模型性能。具体而言,PEFT方法在多个基准测试中均取得了优于全量微调的结果,表明其在APR任务中具有更好的泛化能力和适应性。
🎯 应用场景
该研究成果可应用于自动化软件开发流程,提升代码质量和开发效率。通过参数高效微调,开发者可以更便捷地将大型语言模型应用于程序修复任务,降低开发成本,并加速软件迭代周期。未来,该技术有望集成到IDE和CI/CD系统中,实现智能化的代码修复和缺陷预防。
📄 摘要(原文)
Automated Program Repair (APR) uses various tools and techniques to help developers achieve functional and error-free code faster. In recent years, Large Language Models (LLMs) have gained popularity as components in APR tool chains because of their performance and flexibility. However, training such models requires a significant amount of resources. Fine-tuning techniques have been developed to adapt pre-trained LLMs to specific tasks, such as APR, and enhance their performance at far lower computational costs than training from scratch. In this study, we empirically investigate the impact of various fine-tuning techniques on the performance of LLMs used for APR. Our experiments provide insights into the performance of a selection of state-of-the-art LLMs pre-trained on code. The evaluation is done on three popular APR benchmarks (i.e., QuixBugs, Defects4J and HumanEval-Java) and considers six different LLMs with varying parameter sizes (resp. CodeGen, CodeT5, StarCoder, DeepSeekCoder, Bloom, and CodeLlama-2). We consider three training regimens: no fine-tuning, full fine-tuning, and parameter-efficient fine-tuning (PEFT) using LoRA and IA3. We observe that full fine-tuning techniques decrease the benchmarking performance of various models due to different data distributions and overfitting. By using parameter-efficient fine-tuning methods, we restrict models in the amount of trainable parameters and achieve better results. Keywords: large language models, automated program repair, parameter-efficient fine-tuning, AI4Code, AI4SE, ML4SE.