Distilling a Small Utility-Based Passage Selector to Enhance Retrieval-Augmented Generation
作者: Hengran Zhang, Keping Bi, Jiafeng Guo, Jiaming Zhang, Shuaiqiang Wang, Dawei Yin, Xueqi Cheng
分类: cs.IR, cs.AI, cs.CL, cs.LG
发布日期: 2025-07-25 (更新: 2025-10-09)
备注: Accepted by SIGIR-AP25
💡 一句话要点
提出基于效用的知识选择蒸馏方法,提升检索增强生成效果
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 检索增强生成 效用判断 知识蒸馏 段落选择 大型语言模型
📋 核心要点
- 现有RAG方法依赖相关性检索,忽略了段落在生成答案时的实际效用,导致复杂问题效果不佳。
- 提出效用蒸馏方法,将大型语言模型的效用判断能力迁移到小型模型,实现高效的段落选择。
- 实验表明,基于效用的选择在降低计算成本的同时,显著提升了复杂问题上的答案生成质量。
📝 摘要(中文)
检索增强生成(RAG)通过整合检索到的信息来增强大型语言模型(LLM)的能力。标准的检索过程侧重于相关性,即查询和段落之间的主题对齐。相比之下,在RAG中,重点已转移到效用,即段落对于生成准确答案的有用性。尽管经验证据表明基于效用的检索在RAG中具有优势,但使用LLM进行效用判断的高计算成本限制了评估的段落数量。对于需要大量信息的复杂查询,这是一个问题。为了解决这个问题,我们提出了一种将LLM的效用判断能力提炼到更小、更高效的模型中的方法。我们的方法侧重于基于效用的选择而不是排序,从而能够根据特定查询动态选择有用的段落,而无需固定的阈值。我们训练学生模型从教师LLM学习伪答案生成和效用判断,使用滑动窗口方法动态选择有用的段落。实验表明,基于效用的选择为RAG提供了一种灵活且经济高效的解决方案,在显著降低计算成本的同时提高了答案质量。我们展示了使用Qwen3-32B作为教师模型进行相关性排序和基于效用的选择的蒸馏结果,分别蒸馏为RankQwen1.7B和UtilityQwen1.7B。我们的研究结果表明,对于复杂问题,基于效用的选择比相关性排序在提高答案生成性能方面更有效。我们将发布MS MARCO数据集的相关性排序和基于效用的选择标注,以支持该领域的进一步研究。
🔬 方法详解
问题定义:论文旨在解决检索增强生成(RAG)中,传统基于相关性的检索方法无法有效选择对生成答案真正有用的段落的问题。现有方法主要关注查询和段落之间的主题相关性,而忽略了段落的实际效用,尤其是在处理需要多方面信息的复杂问题时,容易检索到大量冗余或无用信息,影响最终生成答案的质量和效率。此外,直接使用大型语言模型(LLM)进行效用判断计算成本高昂,限制了可评估的段落数量。
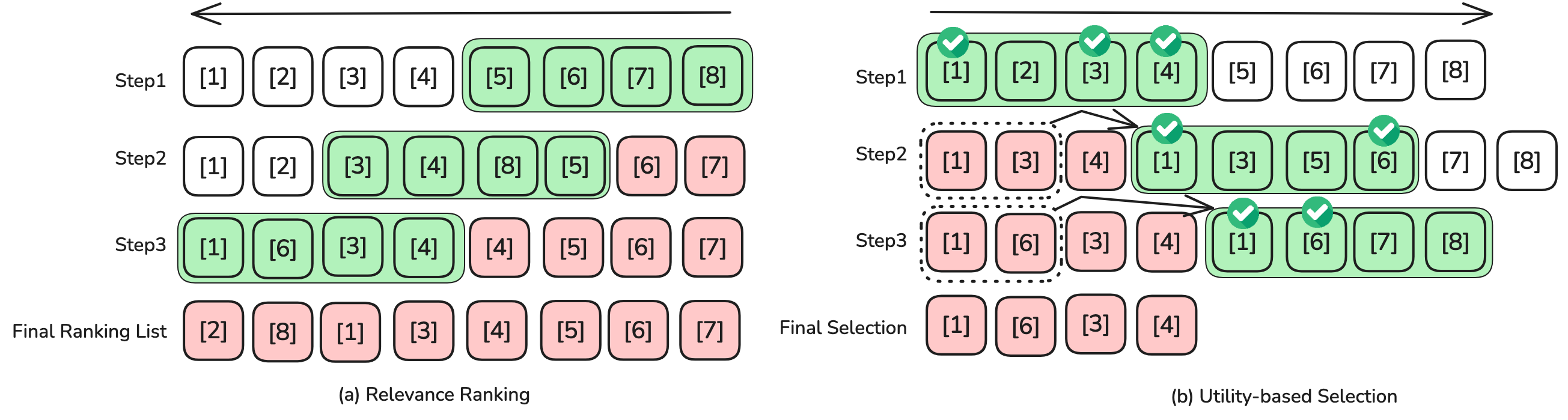
核心思路:论文的核心思路是将大型语言模型(LLM)的效用判断能力蒸馏到小型模型中,从而实现高效的基于效用的段落选择。通过训练小型模型学习LLM对段落效用的判断,可以在保证检索质量的同时,显著降低计算成本。这种方法侧重于段落的选择而非排序,允许根据特定查询动态地选择最有用的段落,避免了固定阈值带来的局限性。
技术框架:该方法主要包含以下几个阶段:1) 使用大型语言模型(教师模型)对候选段落进行效用评估,生成伪标签;2) 构建小型模型(学生模型),学习教师模型的效用判断能力;3) 采用滑动窗口方法,动态选择对生成答案最有用的段落;4) 使用选择的段落进行检索增强生成。整体流程是从LLM中提取知识,并将其转移到更小、更高效的模型中,从而优化RAG流程。
关键创新:该论文的关键创新在于提出了基于效用的段落选择蒸馏方法,将LLM的效用判断能力迁移到小型模型。与传统的基于相关性的检索方法相比,该方法更关注段落在生成答案时的实际效用,能够更有效地选择对生成答案有用的段落。此外,该方法采用动态选择策略,避免了固定阈值带来的局限性,能够根据特定查询灵活地选择段落。
关键设计:在训练学生模型时,采用了伪答案生成和效用判断相结合的训练方式。具体来说,学生模型需要学习生成伪答案,并判断每个段落对生成伪答案的贡献程度。损失函数的设计需要同时考虑伪答案生成的准确性和效用判断的准确性。滑动窗口的大小和步长是影响段落选择效果的关键参数,需要根据具体任务进行调整。此外,教师模型的选择也会影响蒸馏效果,论文中使用了Qwen3-32B作为教师模型。
🖼️ 关键图片


📊 实验亮点
实验结果表明,使用Qwen3-32B作为教师模型,蒸馏得到的UtilityQwen1.7B在复杂问题上的答案生成性能优于RankQwen1.7B,表明基于效用的选择比基于相关性的排序更有效。该方法在显著降低计算成本的同时,提高了答案质量,为RAG提供了一种灵活且经济高效的解决方案。
🎯 应用场景
该研究成果可广泛应用于问答系统、智能客服、知识图谱构建等领域。通过提升检索增强生成的效果,可以提高问答系统的准确性和效率,改善用户体验。此外,该方法还可以应用于信息抽取、文本摘要等任务,具有重要的实际应用价值和广阔的应用前景。
📄 摘要(原文)
Retrieval-augmented generation (RAG) enhances large language models (LLMs) by incorporating retrieved information. Standard retrieval process prioritized relevance, focusing on topical alignment between queries and passages. In contrast, in RAG, the emphasis has shifted to utility, which considers the usefulness of passages for generating accurate answers. Despite empirical evidence showing the benefits of utility-based retrieval in RAG, the high computational cost of using LLMs for utility judgments limits the number of passages evaluated. This restriction is problematic for complex queries requiring extensive information. To address this, we propose a method to distill the utility judgment capabilities of LLMs into smaller, more efficient models. Our approach focuses on utility-based selection rather than ranking, enabling dynamic passage selection tailored to specific queries without the need for fixed thresholds. We train student models to learn pseudo-answer generation and utility judgments from teacher LLMs, using a sliding window method that dynamically selects useful passages. Our experiments demonstrate that utility-based selection provides a flexible and cost-effective solution for RAG, significantly reducing computational costs while improving answer quality. We present the distillation results using Qwen3-32B as the teacher model for both relevance ranking and utility-based selection, distilled into RankQwen1.7B and UtilityQwen1.7B. Our findings indicate that for complex questions, utility-based selection is more effective than relevance ranking in enhancing answer generation performance. We will release the relevance ranking and utility-based selection annotations for the MS MARCO dataset, supporting further research in this area.