Success in Humanoid Reinforcement Learning under Partial Observation
作者: Wuhao Wang, Zhiyong Chen
分类: cs.AI, cs.RO
发布日期: 2025-07-25
备注: 11 pages, 3 figures, and 4 tables. Not published anywhere else
💡 一句话要点
提出基于历史编码器的强化学习方法,首次在部分观测下成功训练Humanoid-v4环境中的人形机器人。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 强化学习 部分观测 人形机器人 历史编码器 机器人控制
📋 核心要点
- 在部分观测下,高维人形机器人控制面临挑战,现有方法难以在Humanoid-v4环境中稳定训练。
- 提出一种新颖的历史编码器,并行处理过去观测序列,重构上下文信息,提升决策鲁棒性。
- 实验表明,该方法在部分观测下达到与全观测基线相当的性能,并对机器人属性变化具有适应性。
📝 摘要(中文)
强化学习已广泛应用于机器人控制,但在部分可观测性下的有效策略学习仍然是一个主要挑战,尤其是在像人形机器人运动这样的高维任务中。目前,还没有工作能够在基准Gymnasium Humanoid-v4环境中,利用不完整的状态信息稳定地训练人形机器人策略。该环境的目标是在不摔倒的情况下尽可能快地向前行走,奖励包括保持直立和向前移动,惩罚包括过度动作和外部接触力。本研究首次成功地在该环境中实现了部分可观测性下的学习。所学习的策略在仅使用原始状态的三分之一到三分之二的情况下,实现了与完全状态访问的最先进结果相当的性能。此外,该策略还表现出对机器人属性的适应性,例如身体部件质量的变化。成功的关键是一种新颖的历史编码器,它可以并行处理固定长度的过去观测序列。该编码器集成到标准无模型算法中,使得性能与完全观测的基线相当。我们推测它从最近的观测中重建了重要的上下文信息,从而实现了鲁棒的决策。
🔬 方法详解
问题定义:论文旨在解决在部分可观测条件下,人形机器人在复杂环境(Gymnasium Humanoid-v4)中进行强化学习控制的问题。现有方法在状态信息不完整时,难以稳定训练出高性能的策略,导致机器人无法有效地完成行走任务。痛点在于如何从有限的历史观测中提取足够的上下文信息,以弥补当前状态信息的缺失。
核心思路:论文的核心思路是利用历史观测信息来弥补当前状态信息的不足。通过设计一个历史编码器,将过去一段时间内的观测序列进行编码,从而提取出包含时间信息的上下文表示。该上下文表示与当前观测结合,用于策略学习,使得机器人能够根据历史信息进行更准确的决策。
技术框架:整体框架采用标准的无模型强化学习算法(具体算法未知),并在此基础上添加了历史编码器模块。该模块接收固定长度的过去观测序列作为输入,经过编码后生成上下文向量,然后将该向量与当前观测向量拼接,作为策略网络的输入。策略网络输出动作,与环境交互,并根据环境反馈更新策略。
关键创新:最重要的技术创新点是历史编码器的设计。该编码器能够并行处理观测序列,从而高效地提取时间信息。具体实现方式未知,但强调了其并行处理的特性,这可能意味着使用了卷积神经网络或Transformer等结构。与现有方法相比,该编码器能够更有效地利用历史信息,从而提升在部分观测下的策略学习性能。
关键设计:关于历史编码器的具体结构、参数设置、损失函数等技术细节,论文摘要中没有明确说明。但是,可以推测其可能包含以下设计:1) 固定长度的观测序列作为输入;2) 并行处理结构,如卷积或Transformer;3) 损失函数可能包含重构损失或预测损失,以鼓励编码器学习到有用的上下文信息。此外,策略网络的结构和训练方式也可能需要进行调整,以适应历史编码器的输出。
🖼️ 关键图片
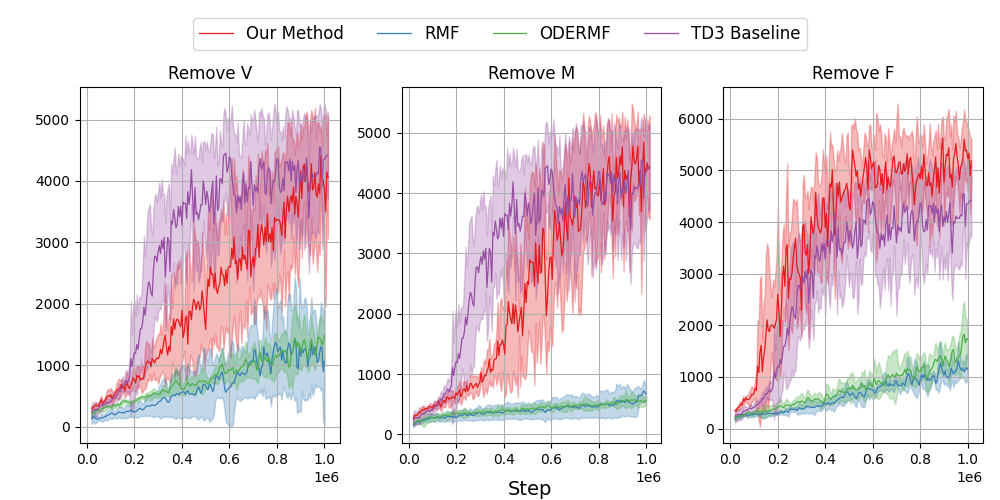
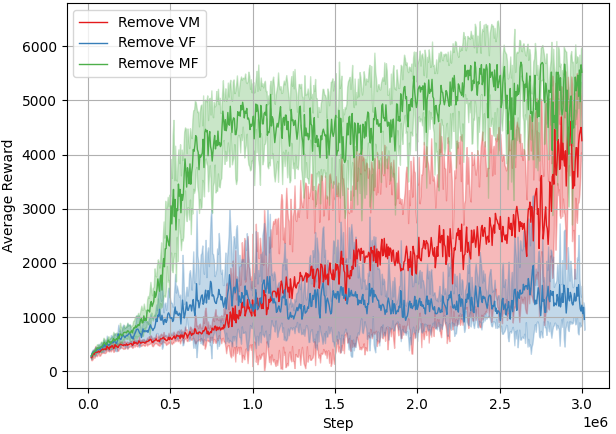
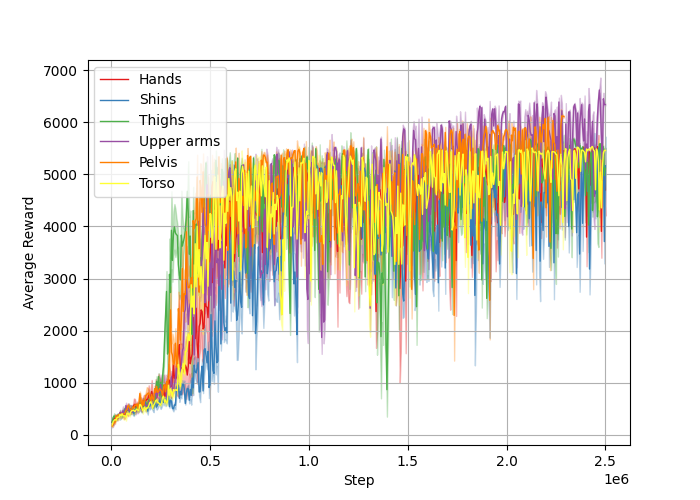
📊 实验亮点
该研究首次在Gymnasium Humanoid-v4环境中成功实现了部分观测下的强化学习。实验结果表明,所学习的策略在仅使用原始状态的三分之一到三分之二的情况下,实现了与完全状态访问的最先进结果相当的性能。此外,该策略还表现出对机器人属性的适应性,例如身体部件质量的变化。具体性能提升数据未知,但强调了与全观测基线相当的性能。
🎯 应用场景
该研究成果可应用于各种需要在部分观测下进行机器人控制的场景,例如在传感器故障、遮挡或成本限制等情况下。此外,该方法还可用于提高机器人对环境变化的鲁棒性,使其能够适应不同的机器人属性和环境条件。未来,该技术有望应用于更复杂的机器人任务,如自主导航、物体操作等。
📄 摘要(原文)
Reinforcement learning has been widely applied to robotic control, but effective policy learning under partial observability remains a major challenge, especially in high-dimensional tasks like humanoid locomotion. To date, no prior work has demonstrated stable training of humanoid policies with incomplete state information in the benchmark Gymnasium Humanoid-v4 environment. The objective in this environment is to walk forward as fast as possible without falling, with rewards provided for staying upright and moving forward, and penalties incurred for excessive actions and external contact forces. This research presents the first successful instance of learning under partial observability in this environment. The learned policy achieves performance comparable to state-of-the-art results with full state access, despite using only one-third to two-thirds of the original states. Moreover, the policy exhibits adaptability to robot properties, such as variations in body part masses. The key to this success is a novel history encoder that processes a fixed-length sequence of past observations in parallel. Integrated into a standard model-free algorithm, the encoder enables performance on par with fully observed baselines. We hypothesize that it reconstructs essential contextual information from recent observations, thereby enabling robust decision-making.