AccessGuru: Leveraging LLMs to Detect and Correct Web Accessibility Violations in HTML Code
作者: Nadeen Fathallah, Daniel Hernández, Steffen Staab
分类: cs.SE, cs.AI
发布日期: 2025-07-24
💡 一句话要点
AccessGuru:利用LLM检测并修正HTML代码中的Web可访问性违规
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: Web可访问性 大型语言模型 HTML代码 自动化修正 可访问性测试
📋 核心要点
- 现有方法在自动检测和纠正Web可访问性违规方面存在不足,无法有效解决所有类型的违规问题。
- AccessGuru结合可访问性测试工具和大型语言模型,利用分类法驱动的提示策略,实现对句法、语义和布局违规的检测与修正。
- 实验结果表明,AccessGuru在Web可访问性违规修正方面显著优于现有方法,平均违规分数降低高达84%。
📝 摘要(中文)
绝大多数网页未能遵守既定的Web可访问性指南,导致不同能力的用户无法与其内容交互。使网页对所有用户可访问需要专业知识和额外的手动工作。为了降低开发者的工作量并促进包容性,本文旨在自动检测和纠正HTML代码中的Web可访问性违规。虽然之前的工作在检测某些类型的可访问性违规方面取得了一些进展,但自动检测和纠正可访问性违规仍然是一个开放的挑战。本文提出了一个新的分类法,将Web可访问性违规分为三个关键类别——句法、语义和布局。该分类法为开发检测和纠正方法以及重新定义评估指标提供了结构化的基础。本文提出了一种新方法AccessGuru,它结合了现有的可访问性测试工具和大型语言模型(LLM)来检测违规,并应用分类法驱动的提示策略来纠正所有三个类别。为了评估这些能力,本文开发了一个真实Web可访问性违规的基准。该基准量化了句法和布局合规性,并通过与人类专家修正的比较分析来判断语义准确性。针对该基准的评估表明,AccessGuru实现了高达84%的平均违规分数降低,显著优于之前最多达到50%的方法。
🔬 方法详解
问题定义:论文旨在解决Web页面中普遍存在的可访问性违规问题,这些违规使得残疾人士难以访问和使用Web内容。现有方法通常只能检测特定类型的违规,且修正效果有限,无法满足全面提升Web可访问性的需求。
核心思路:论文的核心思路是结合现有的可访问性测试工具和大型语言模型(LLM),利用LLM强大的理解和生成能力,自动检测并修正HTML代码中的可访问性违规。通过分类法驱动的提示策略,引导LLM针对不同类型的违规进行针对性的修正。
技术框架:AccessGuru的整体框架包含以下几个主要阶段:1) 使用现有的可访问性测试工具初步检测HTML代码中的违规;2) 根据提出的分类法(句法、语义、布局)对检测到的违规进行分类;3) 利用LLM,并根据违规类型设计相应的提示(prompt),生成修正后的HTML代码;4) 对修正后的代码进行评估,验证修正效果。
关键创新:论文的关键创新在于:1) 提出了一个Web可访问性违规的分类法,为后续的检测和修正提供了结构化的基础;2) 结合了现有的可访问性测试工具和LLM,充分利用了两者的优势;3) 设计了分类法驱动的提示策略,使得LLM能够针对不同类型的违规进行针对性的修正。与现有方法相比,AccessGuru能够更全面、更有效地检测和修正Web可访问性违规。
关键设计:论文的关键设计包括:1) 违规分类法的具体类别和定义;2) 针对不同类别违规设计的提示策略,例如,对于语义违规,可能需要提供上下文信息以帮助LLM理解代码的含义;3) 评估指标的设计,用于量化修正效果,包括句法和布局的合规性以及语义的准确性。
🖼️ 关键图片
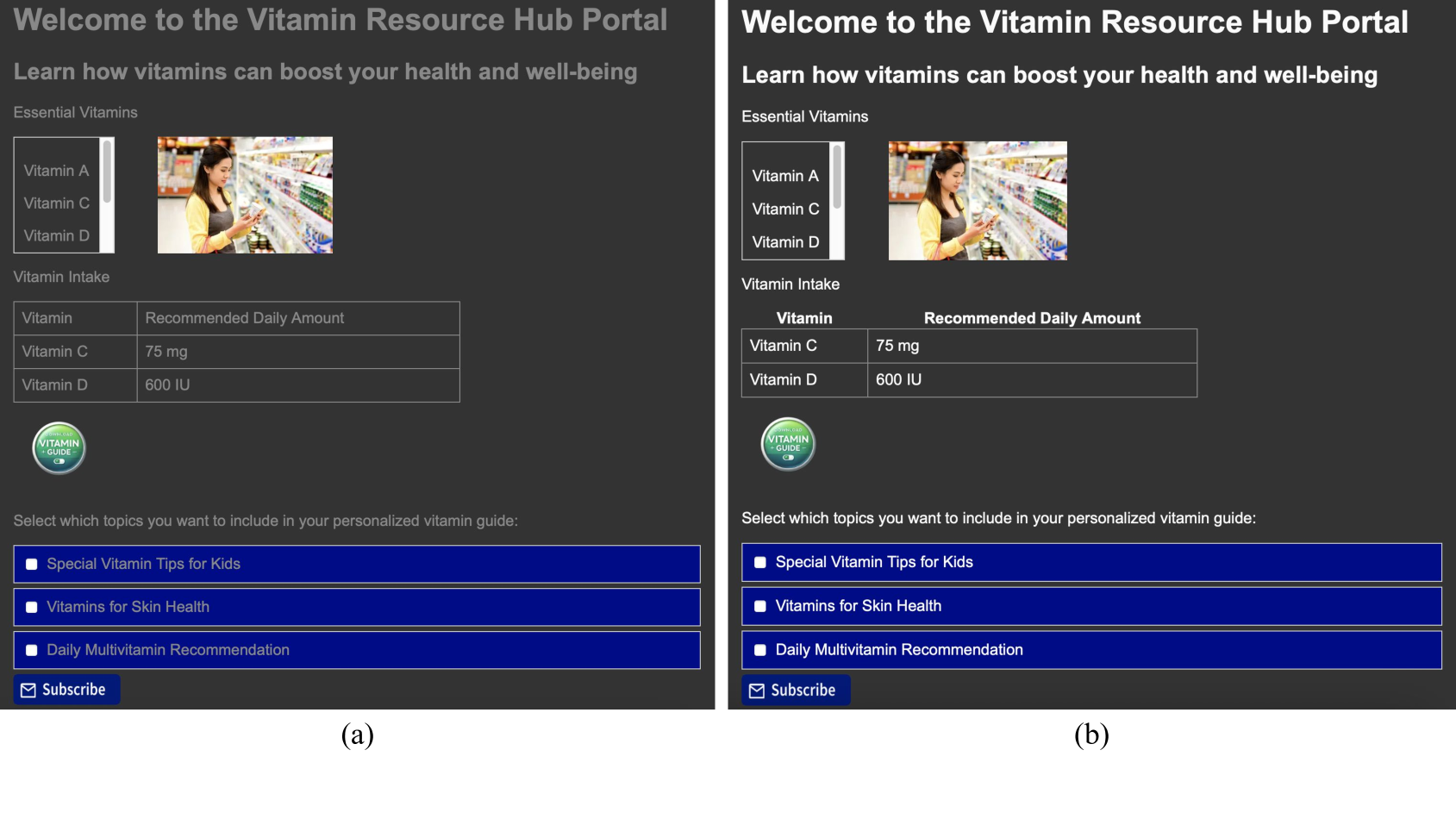
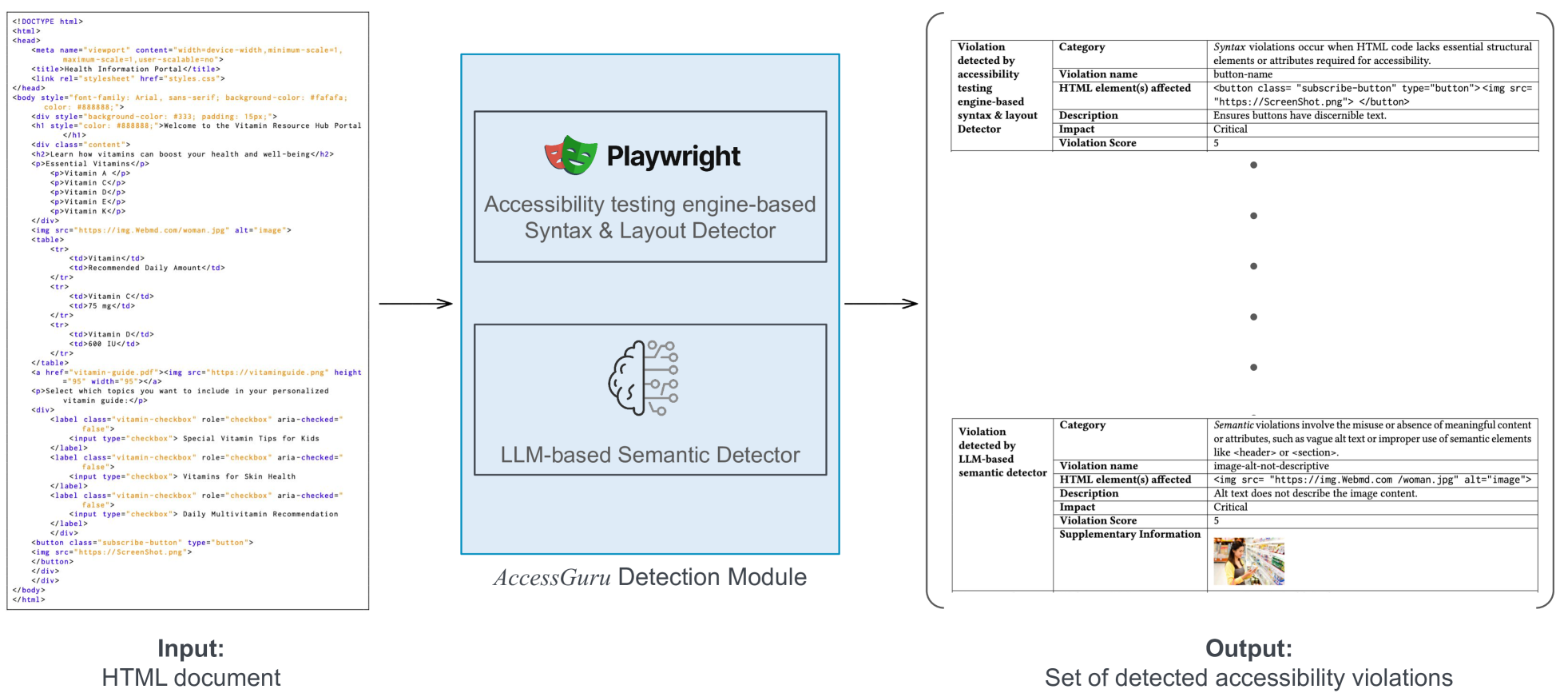
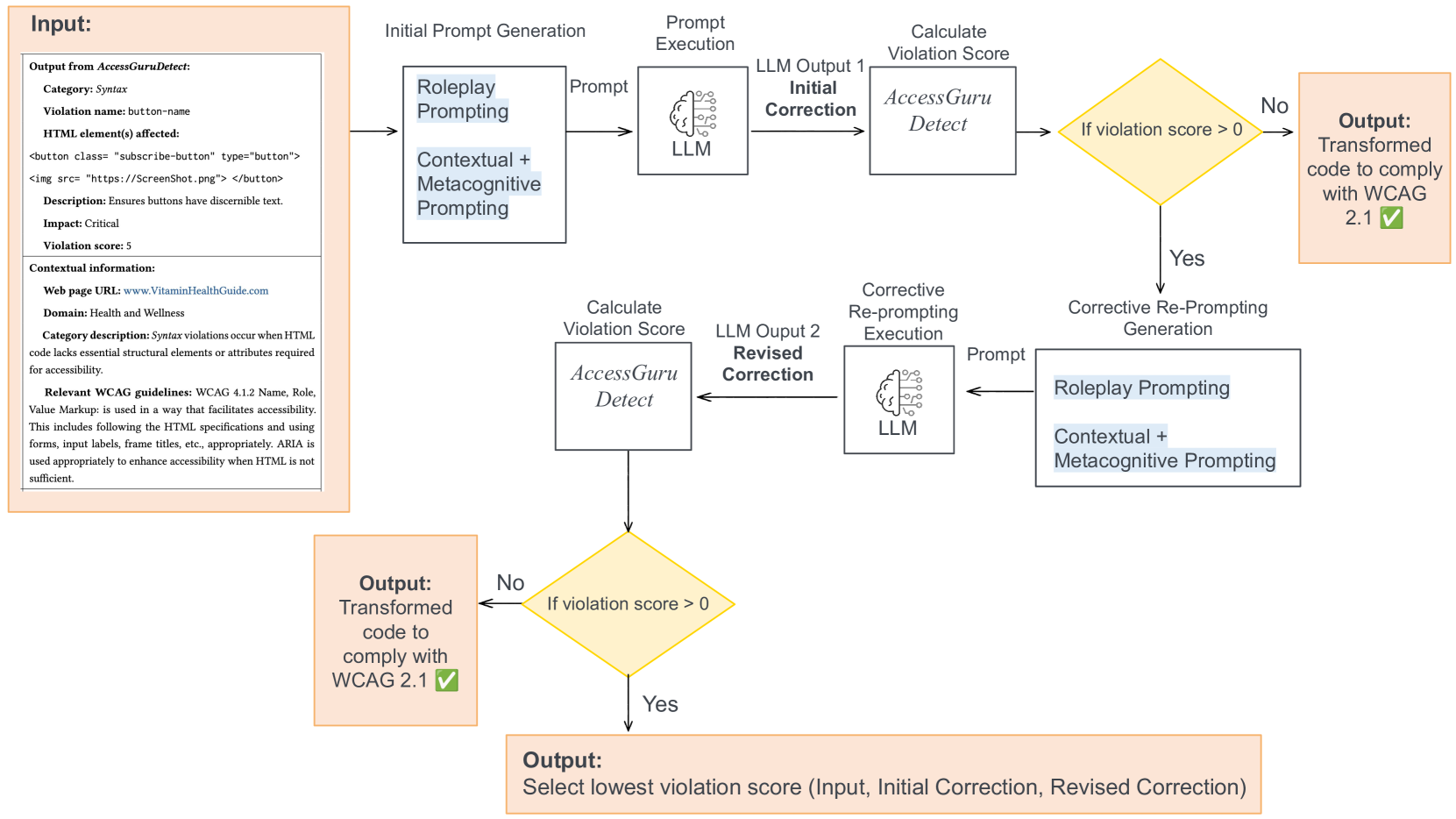
📊 实验亮点
AccessGuru在真实Web可访问性违规基准测试中表现出色,平均违规分数降低高达84%,显著优于现有方法(最高50%)。该结果表明,AccessGuru能够有效检测和修正HTML代码中的可访问性违规,提升Web内容的可访问性。
🎯 应用场景
AccessGuru具有广泛的应用前景,可用于自动提升现有网站的可访问性,降低Web开发人员在可访问性方面的投入,并促进Web内容的包容性。该研究成果可集成到Web开发工具和流程中,帮助开发者创建更易于访问的Web应用,从而惠及更广泛的用户群体。
📄 摘要(原文)
The vast majority of Web pages fail to comply with established Web accessibility guidelines, excluding a range of users with diverse abilities from interacting with their content. Making Web pages accessible to all users requires dedicated expertise and additional manual efforts from Web page providers. To lower their efforts and promote inclusiveness, we aim to automatically detect and correct Web accessibility violations in HTML code. While previous work has made progress in detecting certain types of accessibility violations, the problem of automatically detecting and correcting accessibility violations remains an open challenge that we address. We introduce a novel taxonomy classifying Web accessibility violations into three key categories - Syntactic, Semantic, and Layout. This taxonomy provides a structured foundation for developing our detection and correction method and redefining evaluation metrics. We propose a novel method, AccessGuru, which combines existing accessibility testing tools and Large Language Models (LLMs) to detect violations and applies taxonomy-driven prompting strategies to correct all three categories. To evaluate these capabilities, we develop a benchmark of real-world Web accessibility violations. Our benchmark quantifies syntactic and layout compliance and judges semantic accuracy through comparative analysis with human expert corrections. Evaluation against our benchmark shows that AccessGuru achieves up to 84% average violation score decrease, significantly outperforming prior methods that achieve at most 50%.