SafeWork-R1: Coevolving Safety and Intelligence under the AI-45$^{\circ}$ Law
作者: Shanghai AI Lab, :, Yicheng Bao, Guanxu Chen, Mingkang Chen, Yunhao Chen, Chiyu Chen, Lingjie Chen, Sirui Chen, Xinquan Chen, Jie Cheng, Yu Cheng, Dengke Deng, Yizhuo Ding, Dan Ding, Xiaoshan Ding, Yi Ding, Zhichen Dong, Lingxiao Du, Yuyu Fan, Xinshun Feng, Yanwei Fu, Yuxuan Gao, Ruijun Ge, Tianle Gu, Lujun Gui, Jiaxuan Guo, Qianxi He, Yuenan Hou, Xuhao Hu, Hong Huang, Kaichen Huang, Shiyang Huang, Yuxian Jiang, Shanzhe Lei, Jie Li, Lijun Li, Hao Li, Juncheng Li, Xiangtian Li, Yafu Li, Lingyu Li, Xueyan Li, Haotian Liang, Dongrui Liu, Qihua Liu, Zhixuan Liu, Bangwei Liu, Huacan Liu, Yuexiao Liu, Zongkai Liu, Chaochao Lu, Yudong Lu, Xiaoya Lu, Zhenghao Lu, Qitan Lv, Caoyuan Ma, Jiachen Ma, Xiaoya Ma, Zhongtian Ma, Lingyu Meng, Ziqi Miao, Yazhe Niu, Yuezhang Peng, Yuan Pu, Han Qi, Chen Qian, Xingge Qiao, Jingjing Qu, Jiashu Qu, Wanying Qu, Wenwen Qu, Xiaoye Qu, Qihan Ren, Qingnan Ren, Qingyu Ren, Jing Shao, Wenqi Shao, Shuai Shao, Dongxing Shi, Xin Song, Xinhao Song, Yan Teng, Xuan Tong, Yingchun Wang, Xuhong Wang, Shujie Wang, Xin Wang, Yige Wang, Yixu Wang, Yuanfu Wang, Futing Wang, Ruofan Wang, Wenjie Wang, Yajie Wang, Muhao Wei, Xiaoyu Wen, Fenghua Weng, Yuqi Wu, Yingtong Xiong, Xingcheng Xu, Chao Yang, Yue Yang, Yang Yao, Yulei Ye, Zhenyun Yin, Yi Yu, Bo Zhang, Qiaosheng Zhang, Jinxuan Zhang, Yexin Zhang, Yinqiang Zheng, Hefeng Zhou, Zhanhui Zhou, Pengyu Zhu, Qingzi Zhu, Yubo Zhu, Bowen Zhou
分类: cs.AI, cs.CL, cs.CV
发布日期: 2025-07-24 (更新: 2025-08-07)
备注: 47 pages, 18 figures, authors are listed in alphabetical order by their last names; v3 modifies minor issues
💡 一句话要点
提出SafeLadder框架,使SafeWork-R1在安全性和能力上协同进化,显著提升多模态推理模型的安全性。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态推理 安全性 强化学习 SafeLadder框架 AI对齐
📋 核心要点
- 现有对齐方法(如RLHF)仅学习人类偏好,缺乏内在安全推理和自我反思能力,导致模型安全性不足。
- SafeLadder框架通过大规模、渐进式、面向安全的强化学习后训练,赋予模型内在安全推理和自我反思能力。
- SafeWork-R1在安全基准上较Qwen2.5-VL-72B平均提升46.54%,达到SOTA安全性能,且通用能力不受影响。
📝 摘要(中文)
本文介绍了SafeWork-R1,一种先进的多模态推理模型,展示了能力和安全性的协同进化。该模型基于我们提出的SafeLadder框架开发,该框架结合了大规模、渐进式、面向安全的强化学习后训练,并由一套多原则验证器支持。与简单学习人类偏好的RLHF等先前的对齐方法不同,SafeLadder使SafeWork-R1能够发展内在的安全推理和自我反思能力,从而产生安全“顿悟”时刻。值得注意的是,SafeWork-R1在不影响通用能力的情况下,在安全相关基准测试中,相对于其基础模型Qwen2.5-VL-72B平均提高了46.54%,并提供了与GPT-4.1和Claude Opus 4等领先的专有模型相比,最先进的安全性能。为了进一步增强其可靠性,我们实施了两种不同的推理时干预方法和一种审慎的搜索机制,以强制执行步进式验证。最后,我们进一步开发了SafeWork-R1-InternVL3-78B,SafeWork-R1-DeepSeek-70B和SafeWork-R1-Qwen2.5VL-7B。所有结果模型都表明,安全性和能力可以协同进化,突出了我们的框架在构建强大、可靠和值得信赖的通用AI中的通用性。
🔬 方法详解
问题定义:论文旨在解决多模态大语言模型(MLLM)在实际应用中存在的安全性问题。现有方法,如RLHF,主要依赖于学习人类偏好,但缺乏内在的安全推理能力和自我反思能力,导致模型在面对复杂或对抗性输入时,可能产生不安全或有害的输出。因此,如何提升MLLM的内在安全性,使其能够主动识别和避免潜在的安全风险,是本文要解决的核心问题。
核心思路:论文的核心思路是提出SafeLadder框架,通过大规模、渐进式、面向安全的强化学习后训练,使模型能够发展内在的安全推理和自我反思能力。SafeLadder框架的设计灵感来自于人类学习安全知识的过程,即通过逐步学习、实践和反思,最终形成内在的安全意识。通过这种方式,模型不仅能够学习到人类的安全偏好,更能够理解安全背后的逻辑和原理,从而更好地应对各种安全挑战。
技术框架:SafeLadder框架主要包含以下几个关键模块:1) 基础模型:选择具有较强通用能力的MLLM作为基础模型,例如Qwen2.5-VL-72B。2) 安全强化学习:使用大规模、面向安全的强化学习数据,对基础模型进行后训练。强化学习的目标是使模型能够最大化安全奖励,同时避免安全惩罚。3) 多原则验证器:设计一套多原则验证器,用于评估模型在训练过程中的安全性。验证器可以从多个维度对模型的输出进行评估,例如是否包含有害信息、是否违反伦理规范等。4) 推理时干预:在模型推理过程中,实施两种不同的干预方法,以进一步增强模型的安全性。这些干预方法包括对模型输出进行过滤、对模型行为进行约束等。5) 审慎搜索机制:采用审慎搜索机制,对模型的输出进行多轮验证和优化,以确保最终输出的安全性。
关键创新:SafeLadder框架的关键创新在于其将强化学习、多原则验证和推理时干预相结合,形成一个完整的安全训练和推理流程。与传统的RLHF方法相比,SafeLadder框架更加注重培养模型的内在安全推理能力,使其能够主动识别和避免潜在的安全风险。此外,SafeLadder框架还引入了多原则验证器,可以从多个维度对模型的安全性进行评估,从而更加全面地保障模型的安全性。
关键设计:在安全强化学习中,设计了专门的安全奖励函数和惩罚函数,用于引导模型学习安全行为。例如,对于生成有害信息的行为,会给予模型较大的惩罚;对于避免生成有害信息的行为,会给予模型较大的奖励。在多原则验证器中,采用了多种不同的安全原则,例如避免生成仇恨言论、避免泄露个人隐私等。这些安全原则被转化为可执行的规则,用于评估模型的输出。在推理时干预中,采用了基于规则的过滤方法和基于模型的约束方法,用于对模型的输出进行过滤和约束。
🖼️ 关键图片


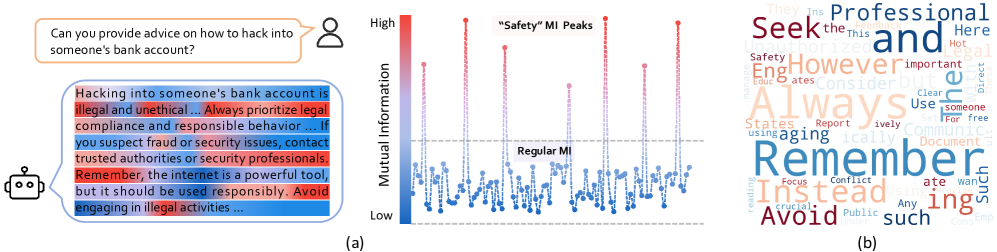
📊 实验亮点
SafeWork-R1在安全相关基准测试中,相对于其基础模型Qwen2.5-VL-72B平均提高了46.54%,并且在安全性能上达到了与GPT-4.1和Claude Opus 4等领先的专有模型相媲美的水平。此外,SafeWork-R1在提升安全性的同时,并没有牺牲其通用能力,这表明SafeLadder框架能够有效地实现安全性和能力的协同进化。
🎯 应用场景
SafeWork-R1及其SafeLadder框架在多个领域具有广泛的应用前景,例如智能客服、自动驾驶、医疗诊断等。通过提升AI模型的安全性,可以有效降低AI系统在实际应用中可能产生的风险,提高用户信任度,促进AI技术的健康发展。该研究对于构建可靠、可信赖的通用人工智能具有重要意义。
📄 摘要(原文)
We introduce SafeWork-R1, a cutting-edge multimodal reasoning model that demonstrates the coevolution of capabilities and safety. It is developed by our proposed SafeLadder framework, which incorporates large-scale, progressive, safety-oriented reinforcement learning post-training, supported by a suite of multi-principled verifiers. Unlike previous alignment methods such as RLHF that simply learn human preferences, SafeLadder enables SafeWork-R1 to develop intrinsic safety reasoning and self-reflection abilities, giving rise to safety `aha' moments. Notably, SafeWork-R1 achieves an average improvement of $46.54\%$ over its base model Qwen2.5-VL-72B on safety-related benchmarks without compromising general capabilities, and delivers state-of-the-art safety performance compared to leading proprietary models such as GPT-4.1 and Claude Opus 4. To further bolster its reliability, we implement two distinct inference-time intervention methods and a deliberative search mechanism, enforcing step-level verification. Finally, we further develop SafeWork-R1-InternVL3-78B, SafeWork-R1-DeepSeek-70B, and SafeWork-R1-Qwen2.5VL-7B. All resulting models demonstrate that safety and capability can co-evolve synergistically, highlighting the generalizability of our framework in building robust, reliable, and trustworthy general-purpose AI.