Bob's Confetti: Phonetic Memorization Attacks in Music and Video Generation
作者: Jaechul Roh, Zachary Novack, Yuefeng Peng, Niloofar Mireshghallah, Taylor Berg-Kirkpatrick, Amir Houmansadr
分类: cs.SD, cs.AI, cs.CL, eess.AS
发布日期: 2025-07-23 (更新: 2025-10-29)
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
提出对抗性语音提示攻击(APT),揭示音乐和视频生成模型中基于语音记忆的脆弱性。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 对抗性攻击 语音记忆 生成模型 版权保护 多模态学习
📋 核心要点
- 现有的音乐和视频生成模型依赖于文本过滤器来防止版权材料的重复使用,但这种方法存在被绕过的风险。
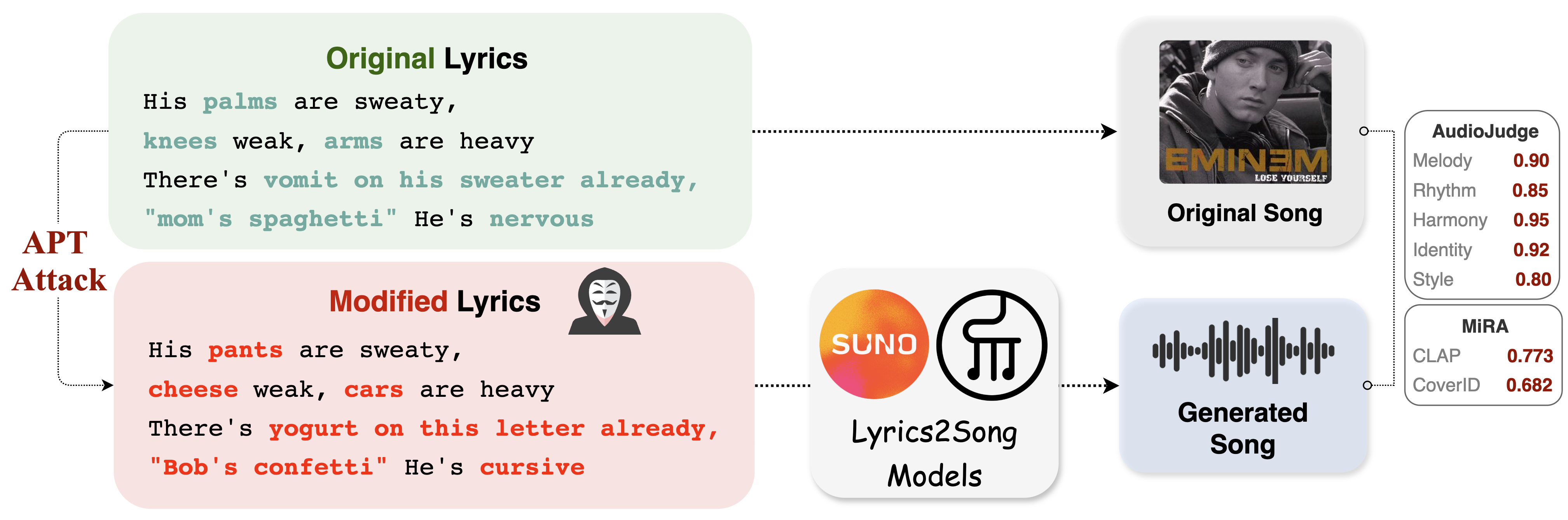
- 论文提出对抗性语音提示攻击(APT),通过用同音异义词替换歌词,在保留声音结构的同时改变语义,从而欺骗模型。
- 实验表明,APT攻击能使歌词到歌曲模型和文本到视频模型生成与原始版权作品高度相似的内容,揭示了模型对语音信息的记忆。
- 研究揭示了模型记忆了与声音相关的深层结构模式,而不仅仅是文本,这代表了转录条件生成模型中的一个关键漏洞。
📝 摘要(中文)
本文揭示了音乐和视频生成AI系统中基于文本过滤的版权保护机制存在根本缺陷。作者提出了一种新颖的对抗性语音提示攻击(APT),该攻击通过利用语音记忆绕过这些安全措施。APT攻击用同音但语义无关的替代词替换标志性歌词(例如,“mom's spaghetti”变为“Bob's confetti”),从而在改变含义的同时保留声学结构。研究表明,诸如SUNO和YuE等领先的歌词到歌曲(L2S)模型在被提示这些修改后的歌词时,会重新生成与受版权保护的原始歌曲具有惊人旋律和节奏相似性的歌曲。更令人惊讶的是,这种漏洞扩展到了跨模态。当使用歌曲中语音修改后的歌词提示时,诸如Veo 3之类的文本到视频(T2V)模型会重建原始音乐视频中的视觉场景,包括特定的设置和角色原型,即使提示中没有任何视觉提示。研究结果表明,模型会记忆与声音相关的深层结构模式,而不仅仅是逐字文本。这种语音到视觉的泄漏代表了转录条件生成模型中的一个关键漏洞,使得简单的版权过滤器无效,并引发了对多模态AI系统安全部署的紧迫担忧。
🔬 方法详解
问题定义:论文旨在解决音乐和视频生成模型中,基于文本过滤的版权保护机制容易被绕过的问题。现有的文本过滤器无法有效阻止模型生成与受版权保护内容在旋律、节奏或视觉场景上相似的内容,因为攻击者可以通过语义改变但语音相似的输入来欺骗模型。
核心思路:核心思路是利用语音记忆。即使歌词的语义发生改变,只要其发音与原始歌词相似,生成模型仍然可能基于对原始歌曲或视频的语音记忆,生成相似的音乐或视觉内容。这种方法绕过了传统的基于文本匹配的版权过滤器。
技术框架:攻击框架主要包括以下几个步骤:1) 选择目标歌曲或视频;2) 使用CMU发音词典找到与目标歌词发音相似的替代词(同音异义词);3) 将原始歌词替换为这些同音异义词,构成对抗性语音提示;4) 将对抗性语音提示输入到歌词到歌曲(L2S)或文本到视频(T2V)模型中;5) 评估生成的内容与原始版权内容的相似度。
关键创新:关键创新在于提出了对抗性语音提示攻击(APT),这是一种新型的攻击方法,它不依赖于对原始文本的直接复制,而是利用了生成模型对语音信息的记忆。这种攻击方式揭示了现有版权保护机制的局限性,并强调了模型对语音信息的过度依赖。
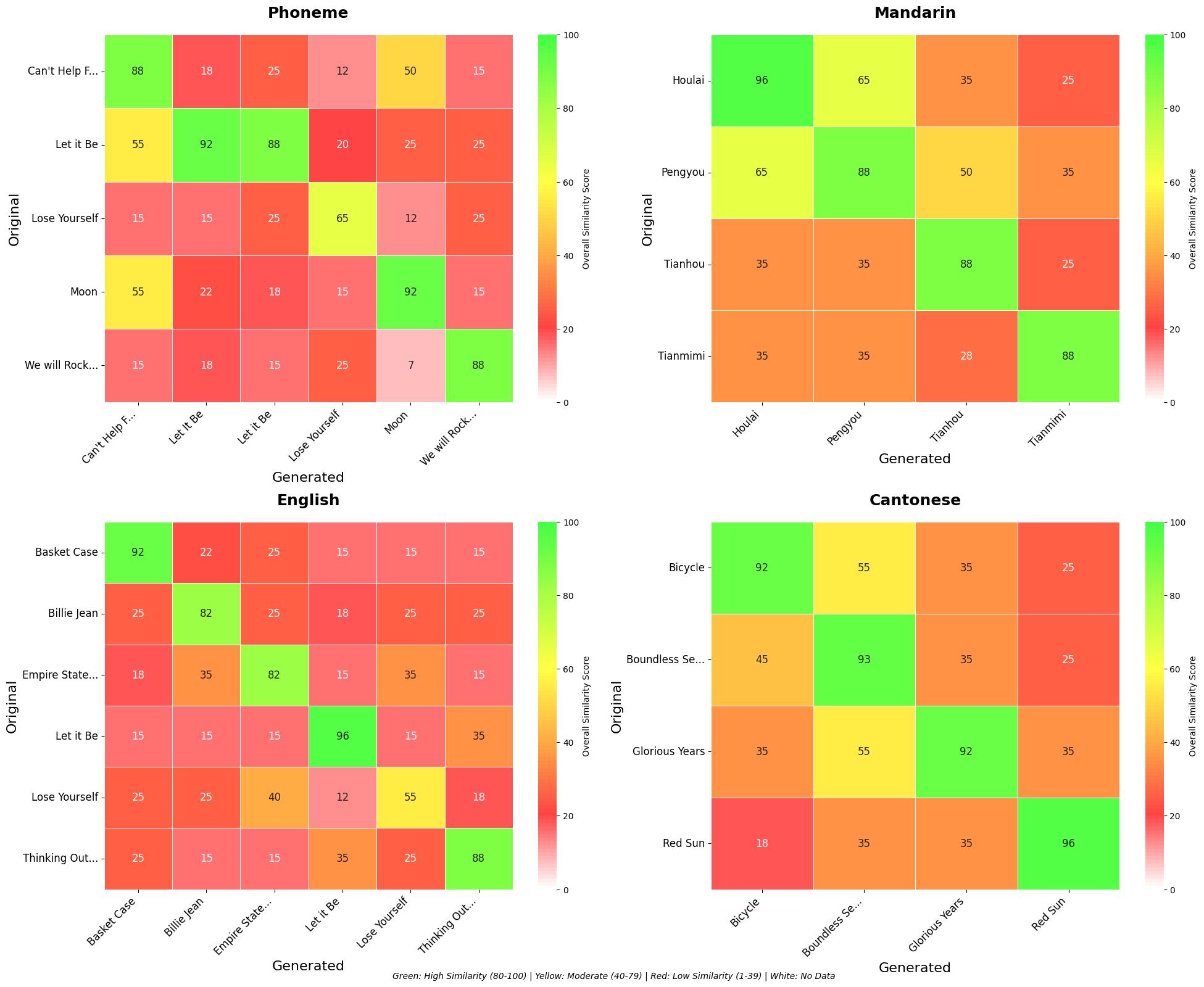
关键设计:关键设计包括:1) 使用CMU发音词典来寻找高质量的同音异义词,确保替代词的发音与原始歌词尽可能相似;2) 针对不同的生成模型(L2S和T2V)进行攻击,验证了APT攻击的跨模态有效性;3) 通过实验评估生成内容与原始版权内容的相似度,量化了攻击的成功率。
🖼️ 关键图片

📊 实验亮点
实验结果表明,使用对抗性语音提示攻击(APT)可以成功欺骗领先的歌词到歌曲(L2S)模型(如SUNO和YuE)和文本到视频(T2V)模型(如Veo 3),使其生成与原始版权内容高度相似的音乐和视频。即使提示中没有任何视觉信息,T2V模型也能重建原始音乐视频中的视觉场景,这突显了模型对语音信息的过度依赖和现有版权保护机制的不足。
🎯 应用场景
该研究成果可应用于评估和改进生成式AI模型的安全性,尤其是在版权保护方面。通过对抗性攻击,可以发现模型潜在的记忆漏洞,并开发更有效的防御机制,例如更强大的水印技术或更智能的版权检测算法。此外,该研究也提醒开发者在设计多模态AI系统时,需要更加关注不同模态之间的信息泄漏问题。
📄 摘要(原文)
Generative AI systems for music and video commonly use text-based filters to prevent the regurgitation of copyrighted material. We expose a fundamental flaw in this approach by introducing Adversarial PhoneTic Prompting (APT), a novel attack that bypasses these safeguards by exploiting phonetic memorization. The APT attack replaces iconic lyrics with homophonic but semantically unrelated alternatives (e.g., "mom's spaghetti" becomes "Bob's confetti"), preserving acoustic structure while altering meaning; we identify high-fidelity phonetic matches using CMU pronouncing dictionary. We demonstrate that leading Lyrics-to-Song (L2S) models like SUNO and YuE regenerate songs with striking melodic and rhythmic similarity to their copyrighted originals when prompted with these altered lyrics. More surprisingly, this vulnerability extends across modalities. When prompted with phonetically modified lyrics from a song, a Text-to-Video (T2V) model like Veo 3 reconstructs visual scenes from the original music video-including specific settings and character archetypes-despite the absence of any visual cues in the prompt. Our findings reveal that models memorize deep, structural patterns tied to acoustics, not just verbatim text. This phonetic-to-visual leakage represents a critical vulnerability in transcript-conditioned generative models, rendering simple copyright filters ineffective and raising urgent concerns about the secure deployment of multimodal AI systems. Demo examples are available at our project page (https://jrohsc.github.io/music_attack/).