Automated Visualization Makeovers with LLMs
作者: Siddharth Gangwar, David A. Selby, Sebastian J. Vollmer
分类: cs.HC, cs.AI
发布日期: 2025-07-21
💡 一句话要点
利用多模态大语言模型实现数据可视化自动优化与改进
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态大语言模型 数据可视化 自动优化 提示工程 可视化改进 图表评估 人机交互
📋 核心要点
- 现有数据可视化教学不足,缺乏有效反馈机制,导致图表质量参差不齐,难以准确传达信息。
- 利用多模态LLM,通过提示工程和最佳实践指导,对现有图表进行自动评估和改进建议,提升可视化效果。
- 通过定量评估验证了LLM对不同图表类型和问题的敏感性,并提供了一个易于使用的Web界面工具。
📝 摘要(中文)
创建能够准确有效地向受众传达所需信息的优秀图形,既是一门艺术,也是一门科学,但通常不在数据科学课程中教授。可视化改进是一种社区交流反馈以改进图表和数据可视化的实践。多模态大语言模型(LLM)能否模拟这项任务?给定图像文件形式的图表或用于生成图表的代码,该系统利用预训练的LLM,并结合可视化最佳实践列表,来半自动地生成建设性批评,从而产生更好的图表。我们的系统以预训练模型的提示工程为中心,依赖于用户指定的指南以及LLM训练语料库中可能存在的关于数据可视化实践的潜在知识。与其他工作不同,本文的重点不是从原始数据或提示生成有效的可视化脚本,而是教育用户如何根据对最佳实践的理解来改进其现有的数据可视化。进行了定量评估,以衡量LLM代理对不同图表类型中各种绘图问题的敏感性。该工具以简单的自托管小程序形式提供,并具有可访问的Web界面。
🔬 方法详解
问题定义:论文旨在解决数据可视化改进的问题。现有方法主要依赖人工反馈,效率低且主观性强。数据科学家通常缺乏专业的可视化设计知识,难以创建高质量的图表。因此,需要一种自动化的方法来评估和改进现有的数据可视化。
核心思路:论文的核心思路是利用多模态大语言模型(LLM)的强大能力,模拟人类专家进行可视化改进的过程。通过提示工程,将可视化最佳实践注入LLM,使其能够理解图表内容,识别潜在问题,并提出改进建议。这种方法旨在弥合数据科学家和可视化专家之间的差距。
技术框架:该系统的整体框架包括以下几个主要阶段:1) 输入:接收用户提供的图表图像或生成图表的代码。2) 提示工程:构建包含可视化最佳实践的提示,引导LLM进行评估和改进。3) LLM处理:利用预训练的LLM,根据提示分析图表,识别问题并生成改进建议。4) 输出:将LLM生成的建议呈现给用户,帮助用户改进图表。该系统提供了一个Web界面,方便用户上传图表并获取反馈。
关键创新:该论文的关键创新在于将多模态LLM应用于数据可视化改进领域。与以往专注于从原始数据生成图表的工作不同,该论文侧重于利用LLM的理解和推理能力,对现有图表进行评估和改进。这种方法能够更好地利用LLM的潜在知识,并为用户提供更具针对性的建议。
关键设计:关键设计包括:1) 提示工程:精心设计的提示包含可视化最佳实践,例如避免过度拥挤、选择合适的图表类型、使用清晰的标签等。2) LLM选择:选择具有强大的图像理解和文本生成能力的LLM。3) 定量评估:设计实验来评估LLM对不同图表类型和问题的敏感性,例如颜色选择、轴标签、数据比例等。具体的参数设置和损失函数未知,因为论文侧重于提示工程而非模型训练。
🖼️ 关键图片


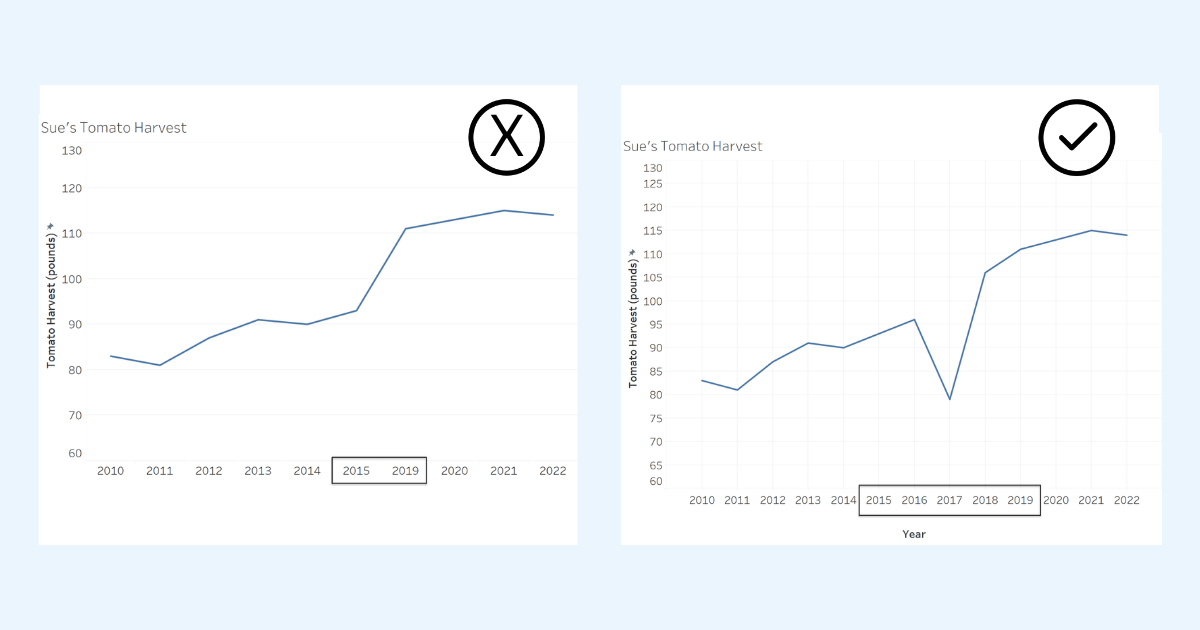
📊 实验亮点
论文通过定量评估验证了LLM在识别和改进数据可视化问题方面的能力。实验结果表明,LLM能够有效地识别不同图表类型中的各种问题,例如颜色选择不当、轴标签不清晰等。虽然具体的性能数据未在摘要中给出,但该研究为利用LLM进行数据可视化改进提供了有力的证据。
🎯 应用场景
该研究成果可应用于数据分析、报告生成、教育培训等领域。数据科学家和分析师可以使用该工具快速改进其数据可视化,提高信息传达的效率和准确性。在教育领域,该工具可以帮助学生学习数据可视化最佳实践,提升其数据表达能力。未来,该技术有望集成到各种数据分析平台中,实现数据可视化的自动化优化。
📄 摘要(原文)
Making a good graphic that accurately and efficiently conveys the desired message to the audience is both an art and a science, typically not taught in the data science curriculum. Visualisation makeovers are exercises where the community exchange feedback to improve charts and data visualizations. Can multi-modal large language models (LLMs) emulate this task? Given a plot in the form of an image file, or the code used to generate it, an LLM, primed with a list of visualization best practices, is employed to semi-automatically generate constructive criticism to produce a better plot. Our system is centred around prompt engineering of a pre-trained model, relying on a combination of userspecified guidelines and any latent knowledge of data visualization practices that might lie within an LLMs training corpus. Unlike other works, the focus is not on generating valid visualization scripts from raw data or prompts, but on educating the user how to improve their existing data visualizations according to an interpretation of best practices. A quantitative evaluation is performed to measure the sensitivity of the LLM agent to various plotting issues across different chart types. We make the tool available as a simple self-hosted applet with an accessible Web interface.