Measuring and Analyzing Intelligence via Contextual Uncertainty in Large Language Models using Information-Theoretic Metrics
作者: Jae Wan Shim
分类: cs.AI
发布日期: 2025-07-21 (更新: 2025-10-26)
💡 一句话要点
提出基于信息论度量的上下文不确定性分析方法,用于评估大型语言模型的智能水平。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 信息论 熵 不确定性 认知剖面 信息增益 上下文学习
📋 核心要点
- 现有方法缺乏对LLM内部信息处理机制的深入理解,难以解释其成功的原因。
- 提出一种任务无关的方法,通过分析模型预测不确定性随上下文长度的变化,构建认知剖面。
- 实验表明,该方法能够揭示不同LLM的独特剖面,并量化模型的信息处理能力。
📝 摘要(中文)
大型语言模型(LLMs)在许多特定任务的基准测试中表现出色,但驱动这种成功的机制仍然知之甚少。本文不再关注这些系统能做什么,而是转向研究它们如何处理信息。本文的贡献是一种与任务无关的方法,可以为任何模型构建量化的认知剖面。该剖面围绕熵衰减曲线构建——该曲线绘制了模型归一化的预测不确定性随上下文长度增长的变化。通过对几种最先进的LLM和不同的文本进行分析,这些曲线揭示了独特的、稳定的剖面,这些剖面取决于模型规模和文本复杂性。本文还提出了信息增益跨度(IGS)作为一个单一指标,总结了衰减模式的理想性。总之,这些工具提供了一种原则性的方法来分析和比较现代人工智能系统的内部动态。
🔬 方法详解
问题定义:现有的大型语言模型评估主要集中在特定任务的性能指标上,缺乏对模型内部认知过程的理解。现有方法难以解释模型如何利用上下文信息进行预测,以及不同模型在信息处理能力上的差异。因此,需要一种与任务无关的方法来量化和比较不同LLM的智能水平。
核心思路:本文的核心思路是通过分析模型在不同上下文长度下的预测不确定性来推断其信息处理能力。模型在处理上下文信息时,其预测的不确定性应该逐渐降低。通过观察不确定性随上下文长度的变化,可以了解模型如何利用上下文信息,并评估其信息处理效率。
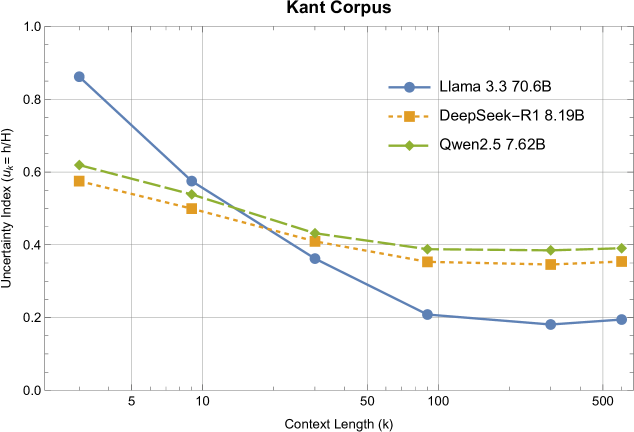
技术框架:该方法主要包含以下几个阶段:1) 选择一系列文本作为输入;2) 对于每个文本,逐步增加上下文长度;3) 在每个上下文长度下,计算模型的预测概率分布;4) 根据预测概率分布,计算模型的熵(作为不确定性的度量);5) 将熵值归一化,并绘制熵衰减曲线;6) 计算信息增益跨度(IGS),作为熵衰减曲线的总结指标。
关键创新:该方法的主要创新在于:1) 提出了一种与任务无关的认知剖面构建方法,可以用于分析任何LLM;2) 利用熵衰减曲线来可视化模型的信息处理过程;3) 提出了信息增益跨度(IGS)作为一个单一指标,用于量化模型的智能水平。与现有方法相比,该方法更加通用、可解释,并且能够提供更深入的模型内部认知过程的理解。
关键设计:关键设计包括:1) 使用交叉熵作为损失函数,训练LLM;2) 使用困惑度(perplexity)来衡量模型预测的不确定性,困惑度与熵密切相关;3) 使用归一化的熵值,以便比较不同模型和不同文本之间的熵衰减曲线;4) 信息增益跨度(IGS)的计算方式为熵衰减曲线的积分,可以反映模型在整个上下文长度范围内的信息增益。
🖼️ 关键图片


📊 实验亮点
实验结果表明,不同规模的LLM具有不同的熵衰减曲线,表明模型规模对信息处理能力有显著影响。此外,文本的复杂性也会影响熵衰减曲线的形状,表明模型能够感知文本的难度。信息增益跨度(IGS)能够有效区分不同模型的智能水平,并与模型在特定任务上的性能表现相关。
🎯 应用场景
该研究成果可应用于LLM的评估与选择、模型优化与改进、以及对人类认知过程的理解。通过分析LLM的认知剖面,可以选择更适合特定任务的模型,并指导模型结构的改进。此外,该方法还可以用于比较LLM与人类在信息处理方面的差异,从而加深对人类认知过程的理解。
📄 摘要(原文)
Large Language Models (LLMs) excel on many task-specific benchmarks, yet the mechanisms that drive this success remain poorly understood. We move from asking what these systems can do to asking how they process information. Our contribution is a task-agnostic method that builds a quantitative Cognitive Profile for any model. The profile is built around the Entropy Decay Curve-a plot of a model's normalised predictive uncertainty as context length grows. Across several state-of-the-art LLMs and diverse texts, the curves expose distinctive, stable profiles that depend on both model scale and text complexity. We also propose the Information Gain Span (IGS) as a single index that summarises the desirability of a decay pattern. Together, these tools offer a principled way to analyse and compare the internal dynamics of modern AI systems.