One Step is Enough: Multi-Agent Reinforcement Learning based on One-Step Policy Optimization for Order Dispatch on Ride-Sharing Platforms
作者: Zijian Zhao, Sen Li
分类: cs.AI, cs.ET, cs.MA
发布日期: 2025-07-21 (更新: 2025-12-31)
🔗 代码/项目: GITHUB
💡 一句话要点
提出基于单步策略优化的多智能体强化学习方法,解决网约车平台订单分配问题
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 多智能体强化学习 订单分配 自动驾驶 群体策略优化 单步策略优化
📋 核心要点
- 传统MARL方法在网约车订单分配中依赖价值函数估计,在大规模不确定环境中表现不佳。
- 论文提出GRPO和OSPO两种新方法,绕过价值函数估计,利用自动驾驶车队的同质性进行优化。
- 实验表明,GRPO和OSPO均能有效优化接送时间和订单数量,且OSPO性能优于GRPO。
📝 摘要(中文)
订单分配是自动驾驶网约车系统中的关键任务,直接影响效率和利润。多智能体强化学习(MARL)通过将大型状态和动作空间分解到各个智能体中,成为解决该问题的一种有前景的方案,有效解决了由大量车辆、乘客和订单引起的交通市场中的维度灾难(CoD)。然而,传统的基于MARL的方法严重依赖于对价值函数的准确估计,这在大型、高度不确定的环境中变得有问题。为了解决这个问题,我们提出了两种绕过价值函数估计的新方法,利用自动驾驶车队的同质性。首先,我们将自动驾驶车队与群体相对策略优化(GRPO)中的群体进行类比,并将其应用于订单分配任务。通过用群体平均回报代替近端策略优化(PPO)基线,GRPO消除了评论家估计误差并减少了训练偏差。受此基线替换的启发,我们进一步提出了单步策略优化(OSPO),证明了在同质车队下,只需一步群体奖励即可训练出最优策略。在真实网约车数据集上的实验表明,GRPO和OSPO在所有场景中都取得了有希望的性能,使用简单的多层感知器(MLP)网络有效地优化了接送时间和服务的订单数量。此外,OSPO在所有场景中都优于GRPO,这归因于它消除了由GRPO的有界时间范围引起的偏差。我们的代码、训练模型和处理后的数据可在https://github.com/RS2002/OSPO 获得。
🔬 方法详解
问题定义:论文旨在解决网约车平台中自动驾驶车辆的订单分配问题。现有基于MARL的方法依赖于准确的价值函数估计,但在大规模、高不确定性的实际环境中,价值函数的估计变得困难且不准确,导致策略优化效果不佳。维度灾难(CoD)也是一个挑战,车辆、乘客和订单数量巨大,使得状态和动作空间非常庞大。
核心思路:论文的核心思路是利用自动驾驶车队的同质性,避免直接估计价值函数。通过将车队视为一个整体,并基于群体奖励进行策略优化,从而简化学习过程并提高效率。GRPO通过替换PPO基线来减少偏差,而OSPO则进一步简化,仅使用单步群体奖励进行优化。
技术框架:整体框架包含以下几个关键部分:首先,将订单分配问题建模为MARL问题,每个自动驾驶车辆作为一个智能体。然后,使用GRPO或OSPO算法进行策略优化。GRPO算法使用群体平均回报代替PPO中的优势函数估计,而OSPO算法则直接基于单步群体奖励进行策略更新。最后,使用训练好的策略进行订单分配,并评估性能。
关键创新:最重要的创新点在于提出了OSPO算法,证明了在同质车队下,仅使用单步群体奖励即可训练出最优策略。这极大地简化了学习过程,降低了计算复杂度,并且避免了价值函数估计带来的误差。与传统的MARL方法相比,OSPO不需要复杂的价值函数网络,只需要一个简单的策略网络即可。
关键设计:论文中使用多层感知机(MLP)作为策略网络。GRPO算法的关键在于使用群体平均回报代替PPO中的优势函数估计。OSPO算法的关键在于使用单步群体奖励进行策略更新。具体而言,OSPO的目标是最大化单步群体奖励的期望,策略更新可以使用梯度上升等方法。
🖼️ 关键图片

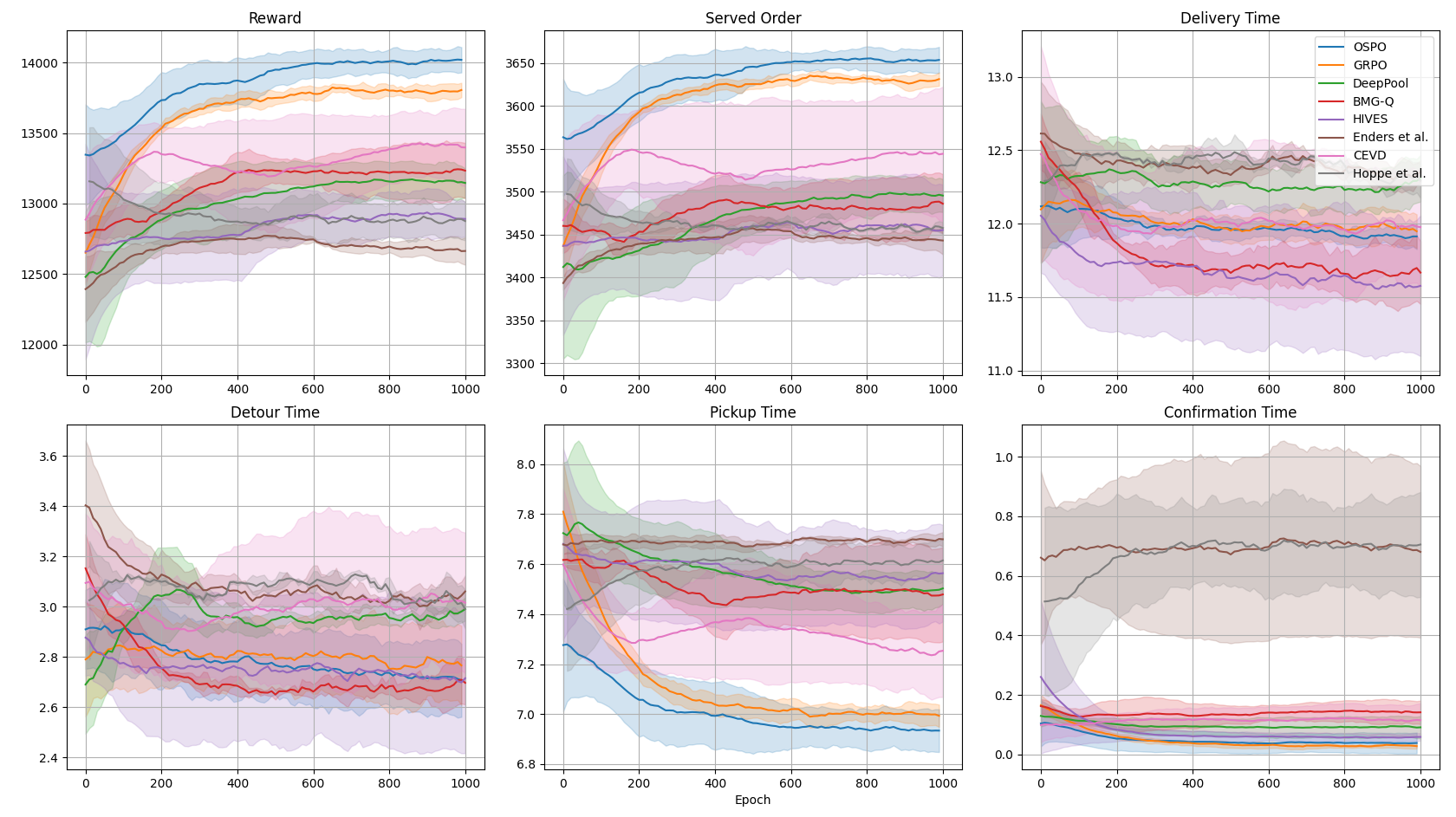
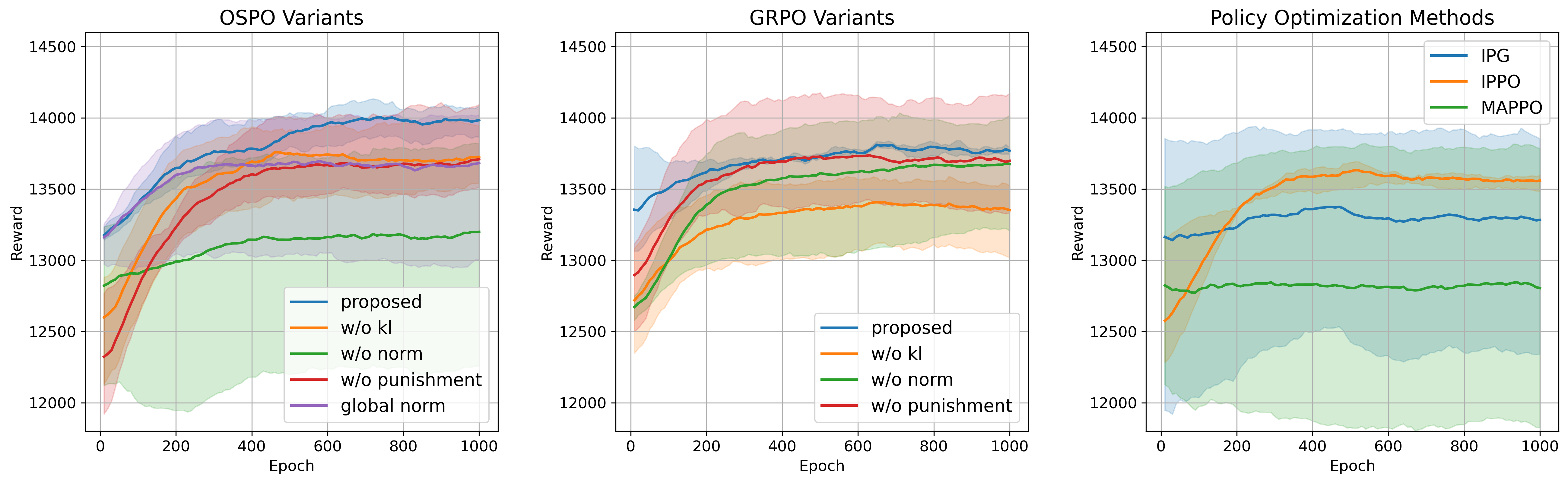
📊 实验亮点
实验结果表明,GRPO和OSPO在真实网约车数据集上均取得了良好的性能。OSPO在所有场景中都优于GRPO,这归因于它消除了由GRPO的有界时间范围引起的偏差。具体而言,OSPO能够更有效地优化接送时间和服务的订单数量,证明了其在实际应用中的潜力。代码和数据已开源。
🎯 应用场景
该研究成果可直接应用于自动驾驶网约车平台的订单分配系统,提高运营效率和乘客满意度。通过更智能的订单分配,可以减少乘客等待时间,提高车辆利用率,从而增加平台收益。此外,该方法还可以扩展到其他资源分配场景,例如物流配送、任务调度等。
📄 摘要(原文)
Order dispatch is a critical task in ride-sharing systems with Autonomous Vehicles (AVs), directly influencing efficiency and profits. Recently, Multi-Agent Reinforcement Learning (MARL) has emerged as a promising solution to this problem by decomposing the large state and action spaces among individual agents, effectively addressing the Curse of Dimensionality (CoD) in transportation market, which is caused by the substantial number of vehicles, passengers, and orders. However, conventional MARL-based approaches heavily rely on accurate estimation of the value function, which becomes problematic in large-scale, highly uncertain environments. To address this issue, we propose two novel methods that bypass value function estimation, leveraging the homogeneous property of AV fleets. First, we draw an analogy between AV fleets and groups in Group Relative Policy Optimization (GRPO), adapting it to the order dispatch task. By replacing the Proximal Policy Optimization (PPO) baseline with the group average reward-to-go, GRPO eliminates critic estimation errors and reduces training bias. Inspired by this baseline replacement, we further propose One-Step Policy Optimization (OSPO), demonstrating that the optimal policy can be trained using only one-step group rewards under a homogeneous fleet. Experiments on a real-world ride-hailing dataset show that both GRPO and OSPO achieve promising performance across all scenarios, efficiently optimizing pickup times and the number of served orders using simple Multilayer Perceptron (MLP) networks. Furthermore, OSPO outperforms GRPO in all scenarios, attributed to its elimination of bias caused by the bounded time horizon of GRPO. Our code, trained models, and processed data are provided at https://github.com/RS2002/OSPO .