StackTrans: From Large Language Model to Large Pushdown Automata Model
作者: Kechi Zhang, Ge Li, Jia Li, Huangzhao Zhang, Yihong Dong, Jia Li, Jingjing Xu, Zhi Jin
分类: cs.SE, cs.AI
发布日期: 2025-07-21 (更新: 2025-08-04)
💡 一句话要点
提出StackTrans,通过引入可学习栈结构增强LLM处理上下文无关文法的能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 Transformer 下推自动机 栈结构 上下文无关文法 可学习栈操作 乔姆斯基层次结构 递归结构
📋 核心要点
- Transformer在处理上下文无关文法等乔姆斯基结构时存在局限性,无法有效建模此类结构。
- StackTrans通过在Transformer层间引入可学习的隐藏状态栈,模拟下推自动机,从而增强模型处理上下文无关文法的能力。
- 实验表明,StackTrans在乔姆斯基层次结构和大规模自然语言任务上均优于标准Transformer模型,且小规模模型性能超越参数量更大的开源LLM。
📝 摘要(中文)
Transformer架构是人工智能领域的一项里程碑式进展,有效地推动了大型语言模型(LLM)的出现。然而,尽管Transformer架构具有卓越的能力和显著的进步,但它仍然存在一些局限性。其中一个固有的限制是它无法有效地捕获乔姆斯基层次结构,例如正则表达式或确定性上下文无关文法。受使用栈有效解决确定性上下文无关文法的下推自动机的启发,我们提出了StackTrans来解决LLM中存在的上述问题。与修改注意力计算的先前方法不同,StackTrans在Transformer层之间显式地结合了隐藏状态栈。这种设计保持了与现有框架(如flash-attention)的兼容性。具体来说,我们的设计具有栈操作(例如,推送和弹出隐藏状态),这些操作是可微的,并且可以以端到端的方式学习。我们的综合评估涵盖了乔姆斯基层次结构和大规模自然语言的基准。在这些不同的任务中,StackTrans始终优于标准Transformer模型和其他基线。我们已成功地将StackTrans从360M扩展到7B参数。特别是,我们从头开始预训练的模型StackTrans-360M优于几个具有2-3倍以上参数的更大的开源LLM,展示了其卓越的效率和推理能力。
🔬 方法详解
问题定义:Transformer架构在处理具有递归结构的语言时存在困难,例如上下文无关文法。传统的Transformer模型难以捕捉长距离依赖关系和嵌套结构,这限制了其在某些特定任务上的性能。现有方法通常通过修改注意力机制来尝试解决这个问题,但效果有限,且可能引入额外的计算负担。
核心思路:StackTrans的核心思路是借鉴下推自动机的思想,在Transformer模型中引入栈结构。通过栈来显式地存储和操作隐藏状态,模型可以更好地处理递归结构和长距离依赖关系。这种方法旨在克服Transformer在处理上下文无关文法等乔姆斯基层次结构时的局限性。
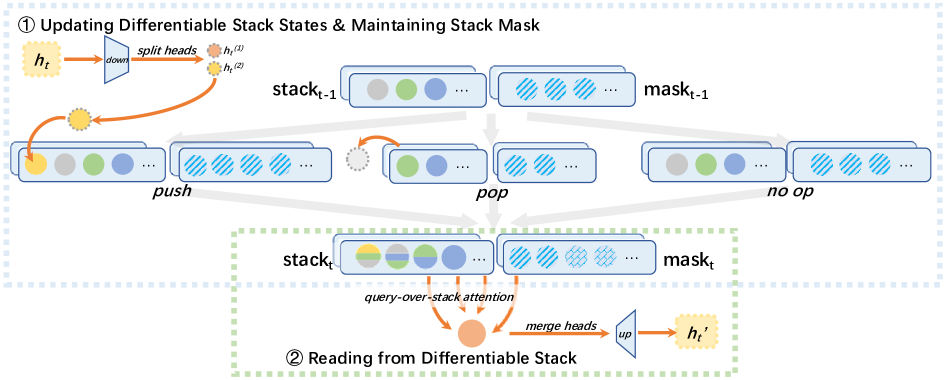
技术框架:StackTrans在标准的Transformer架构中插入了可学习的栈操作层。在Transformer层之间,隐藏状态可以被推入栈中,也可以从栈中弹出。这些栈操作是可微的,因此可以通过反向传播进行训练。整体架构与标准Transformer兼容,可以利用现有的优化技术,如flash-attention。
关键创新:StackTrans的关键创新在于将栈结构显式地集成到Transformer模型中,并使栈操作可学习。与以往尝试修改注意力机制的方法不同,StackTrans直接模拟了下推自动机的行为,从而更有效地处理上下文无关文法。这种方法允许模型动态地管理上下文信息,并更好地捕捉长距离依赖关系。
关键设计:StackTrans的关键设计包括可学习的栈操作(push和pop),以及用于控制这些操作的门控机制。这些门控机制决定何时将隐藏状态推入栈中,以及何时从栈中弹出。损失函数包括标准的语言建模损失,以及可能用于鼓励栈使用的正则化项。具体的网络结构细节(如栈的大小、门控机制的类型)可能需要根据具体任务进行调整。
🖼️ 关键图片
📊 实验亮点
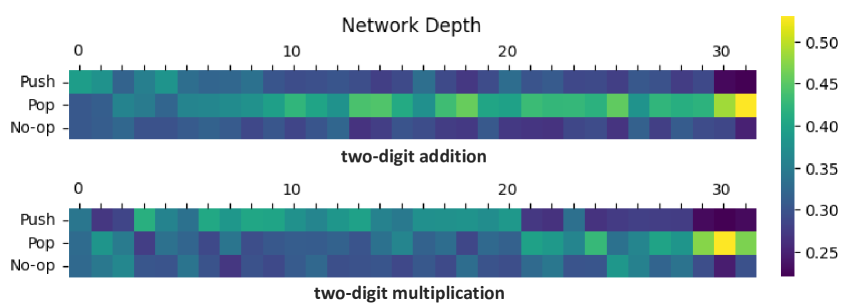
StackTrans在乔姆斯基层次结构和大规模自然语言任务上均取得了显著的性能提升。例如,StackTrans-360M在某些任务上优于参数量为其2-3倍的开源LLM。实验结果表明,StackTrans能够更有效地处理上下文无关文法,并具有更强的推理能力。这些结果验证了StackTrans的有效性和效率。
🎯 应用场景
StackTrans在需要处理具有复杂语法结构的文本的任务中具有广泛的应用前景,例如代码生成、程序理解、自然语言处理中的语法分析和语义理解等。该模型可以提高机器翻译的准确性,改进代码生成的质量,并促进更智能的对话系统和问答系统的发展。此外,StackTrans还可以应用于生物信息学领域,用于分析DNA序列等具有复杂结构的生物数据。
📄 摘要(原文)
The Transformer architecture has emerged as a landmark advancement within the broad field of artificial intelligence, effectively catalyzing the advent of large language models (LLMs). However, despite its remarkable capabilities and the substantial progress it has facilitated, the Transformer architecture still has some limitations. One such intrinsic limitation is its inability to effectively capture the Chomsky hierarchy, such as regular expressions or deterministic context-free grammars. Drawing inspiration from pushdown automata, which efficiently resolve deterministic context-free grammars using stacks, we propose StackTrans to address the aforementioned issue within LLMs. Unlike previous approaches that modify the attention computation, StackTrans explicitly incorporates hidden state stacks between Transformer layers. This design maintains compatibility with existing frameworks like flash-attention. Specifically, our design features stack operations -- such as pushing and popping hidden states -- that are differentiable and can be learned in an end-to-end manner. Our comprehensive evaluation spans benchmarks for both Chomsky hierarchies and large-scale natural languages. Across these diverse tasks, StackTrans consistently outperforms standard Transformer models and other baselines. We have successfully scaled StackTrans up from 360M to 7B parameters. In particular, our from-scratch pretrained model StackTrans-360M outperforms several larger open-source LLMs with 2-3x more parameters, showcasing its superior efficiency and reasoning capability.