KROMA: Ontology Matching with Knowledge Retrieval and Large Language Models
作者: Lam Nguyen, Erika Barcelos, Roger French, Yinghui Wu
分类: cs.AI
发布日期: 2025-07-18 (更新: 2025-09-11)
备注: Accepted to the 24th International Semantic Web Conference Research Track (ISWC 2025)
💡 一句话要点
KROMA:利用知识检索和大型语言模型进行本体匹配
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 本体匹配 大型语言模型 知识检索 检索增强生成 语义互操作性
📋 核心要点
- 现有本体匹配系统依赖手工规则或专用模型,缺乏适应性,难以有效处理复杂的语义互操作性任务。
- KROMA框架利用RAG管道中的LLM,通过检索结构、词汇和定义知识来动态丰富本体匹配任务的语义上下文。
- 实验结果表明,KROMA在多个基准数据集上优于传统OM系统和先进的LLM方法,同时保持了较低的通信开销。
📝 摘要(中文)
本体匹配(OM)是语义互操作性的基石任务,但现有的系统通常依赖于手工规则或适应性有限的专用模型。我们提出了KROMA,这是一个新颖的OM框架,它利用检索增强生成(RAG)管道中的大型语言模型(LLM),通过结构、词汇和定义知识动态地丰富OM任务的语义上下文。为了优化性能和效率,KROMA集成了基于双相似性的概念匹配和一个轻量级的本体细化步骤,这两个步骤可以修剪候选概念,并大大减少调用LLM的通信开销。通过在多个基准数据集上的实验,我们表明,将知识检索与上下文增强的LLM相结合,可以显著增强本体匹配,优于经典的OM系统和最先进的基于LLM的方法,同时保持可比的通信开销。我们的研究强调了所提出的优化技术(有针对性的知识检索、提示丰富和本体细化)在规模化本体匹配中的可行性和益处。
🔬 方法详解
问题定义:本体匹配旨在发现不同本体中语义上对应的概念。现有方法的痛点在于,要么依赖人工规则,泛化能力差;要么使用特定模型,难以适应新的本体结构和领域知识。这些方法在处理大规模本体时效率较低,且难以有效利用外部知识。
核心思路:KROMA的核心思路是利用大型语言模型(LLM)的强大语义理解能力,结合知识检索,动态地为本体匹配任务提供丰富的上下文信息。通过检索相关的结构、词汇和定义知识,LLM可以更好地理解本体概念的含义,从而提高匹配的准确性。
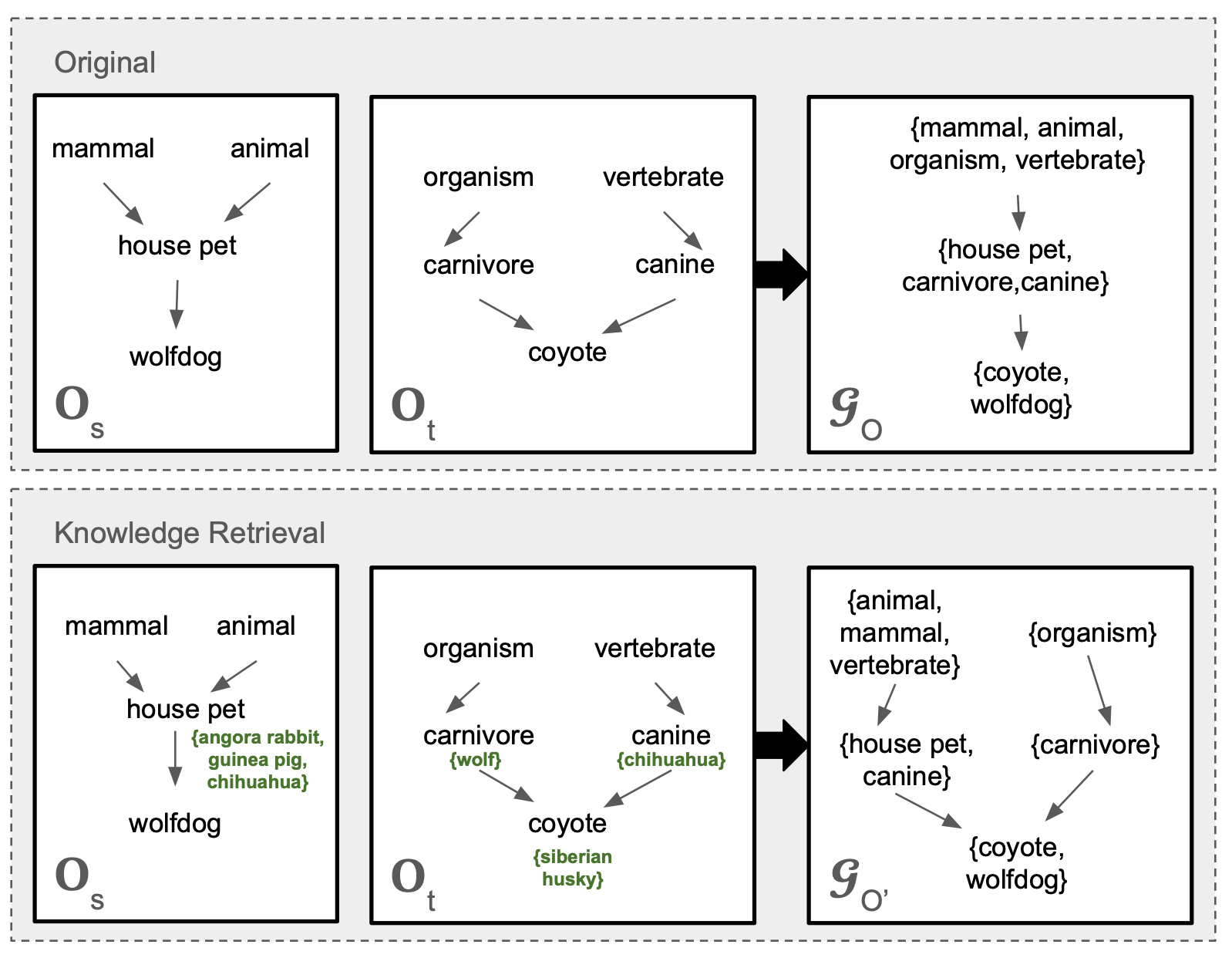
技术框架:KROMA框架包含以下几个主要模块:1) 知识检索模块:根据输入的本体概念,从知识库中检索相关的结构、词汇和定义信息。2) 提示构建模块:将检索到的知识与本体概念一起构建成LLM的输入提示。3) LLM推理模块:利用LLM对提示进行推理,生成本体概念的语义表示。4) 概念匹配模块:基于LLM生成的语义表示,计算不同本体概念之间的相似度,从而进行本体匹配。5) 本体细化模块:使用基于双相似性的概念匹配方法,对候选概念进行剪枝,减少LLM的调用次数,提高效率。
关键创新:KROMA的关键创新在于将知识检索与上下文增强的LLM相结合,用于本体匹配。与传统的基于规则或特定模型的OM系统相比,KROMA能够动态地利用外部知识,提高匹配的准确性和泛化能力。此外,KROMA还通过本体细化步骤,减少了LLM的调用次数,提高了效率。
关键设计:KROMA使用基于双相似性的概念匹配方法进行本体细化,该方法能够有效地剪枝候选概念,减少LLM的调用次数。此外,KROMA还设计了有效的提示模板,将检索到的知识与本体概念一起输入LLM,从而提高LLM的推理效果。具体的参数设置和损失函数等技术细节在论文中未明确说明,属于未知信息。
🖼️ 关键图片


📊 实验亮点
KROMA在多个基准数据集上的实验结果表明,其性能优于经典的OM系统和最先进的基于LLM的方法。具体性能数据和提升幅度在摘要中提到“显著增强本体匹配”,但未给出具体数值。该研究证明了知识检索与上下文增强的LLM相结合在本体匹配中的有效性。
🎯 应用场景
KROMA可应用于各种需要语义互操作性的领域,例如数据集成、知识图谱构建、语义搜索等。通过提高本体匹配的准确性和效率,KROMA可以促进不同系统和数据源之间的信息共享和知识融合,具有重要的实际应用价值和未来发展潜力。
📄 摘要(原文)
Ontology Matching (OM) is a cornerstone task of semantic interoperability, yet existing systems often rely on handcrafted rules or specialized models with limited adaptability. We present KROMA, a novel OM framework that harnesses Large Language Models (LLMs) within a Retrieval-Augmented Generation (RAG) pipeline to dynamically enrich the semantic context of OM tasks with structural, lexical, and definitional knowledge. To optimize both performance and efficiency, KROMA integrates a bisimilarity-based concept matching and a lightweight ontology refinement step, which prune candidate concepts and substantially reduce the communication overhead from invoking LLMs. Through experiments on multiple benchmark datasets, we show that integrating knowledge retrieval with context-augmented LLMs significantly enhances ontology matching, outperforming both classic OM systems and cutting-edge LLM-based approaches while keeping communication overhead comparable. Our study highlights the feasibility and benefit of the proposed optimization techniques (targeted knowledge retrieval, prompt enrichment, and ontology refinement) for ontology matching at scale.