Voxtral
作者: Alexander H. Liu, Andy Ehrenberg, Andy Lo, Clément Denoix, Corentin Barreau, Guillaume Lample, Jean-Malo Delignon, Khyathi Raghavi Chandu, Patrick von Platen, Pavankumar Reddy Muddireddy, Sanchit Gandhi, Soham Ghosh, Srijan Mishra, Thomas Foubert, Abhinav Rastogi, Adam Yang, Albert Q. Jiang, Alexandre Sablayrolles, Amélie Héliou, Amélie Martin, Anmol Agarwal, Antoine Roux, Arthur Darcet, Arthur Mensch, Baptiste Bout, Baptiste Rozière, Baudouin De Monicault, Chris Bamford, Christian Wallenwein, Christophe Renaudin, Clémence Lanfranchi, Darius Dabert, Devendra Singh Chaplot, Devon Mizelle, Diego de las Casas, Elliot Chane-Sane, Emilien Fugier, Emma Bou Hanna, Gabrielle Berrada, Gauthier Delerce, Gauthier Guinet, Georgii Novikov, Guillaume Martin, Himanshu Jaju, Jan Ludziejewski, Jason Rute, Jean-Hadrien Chabran, Jessica Chudnovsky, Joachim Studnia, Joep Barmentlo, Jonas Amar, Josselin Somerville Roberts, Julien Denize, Karan Saxena, Karmesh Yadav, Kartik Khandelwal, Kush Jain, Lélio Renard Lavaud, Léonard Blier, Lingxiao Zhao, Louis Martin, Lucile Saulnier, Luyu Gao, Marie Pellat, Mathilde Guillaumin, Mathis Felardos, Matthieu Dinot, Maxime Darrin, Maximilian Augustin, Mickaël Seznec, Neha Gupta, Nikhil Raghuraman, Olivier Duchenne, Patricia Wang, Patryk Saffer, Paul Jacob, Paul Wambergue, Paula Kurylowicz, Philomène Chagniot, Pierre Stock, Pravesh Agrawal, Rémi Delacourt, Romain Sauvestre, Roman Soletskyi, Sagar Vaze, Sandeep Subramanian, Saurabh Garg, Shashwat Dalal, Siddharth Gandhi, Sumukh Aithal, Szymon Antoniak, Teven Le Scao, Thibault Schueller, Thibaut Lavril, Thomas Robert, Thomas Wang, Timothée Lacroix, Tom Bewley, Valeriia Nemychnikova, Victor Paltz, Virgile Richard, Wen-Ding Li, William Marshall, Xuanyu Zhang, Yihan Wan, Yunhao Tang
分类: cs.SD, cs.AI, eess.AS
发布日期: 2025-07-17
备注: 17 pages
💡 一句话要点
提出Voxtral Mini和Voxtral Small多模态音频聊天模型,在音频理解任务上达到SOTA。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态学习 音频理解 语音识别 长上下文窗口 Transformer模型
📋 核心要点
- 现有音频理解模型在处理长音频和多轮对话方面存在挑战,且性能有待提升。
- Voxtral通过训练多模态模型,同时理解音频和文本,并扩大上下文窗口来解决上述问题。
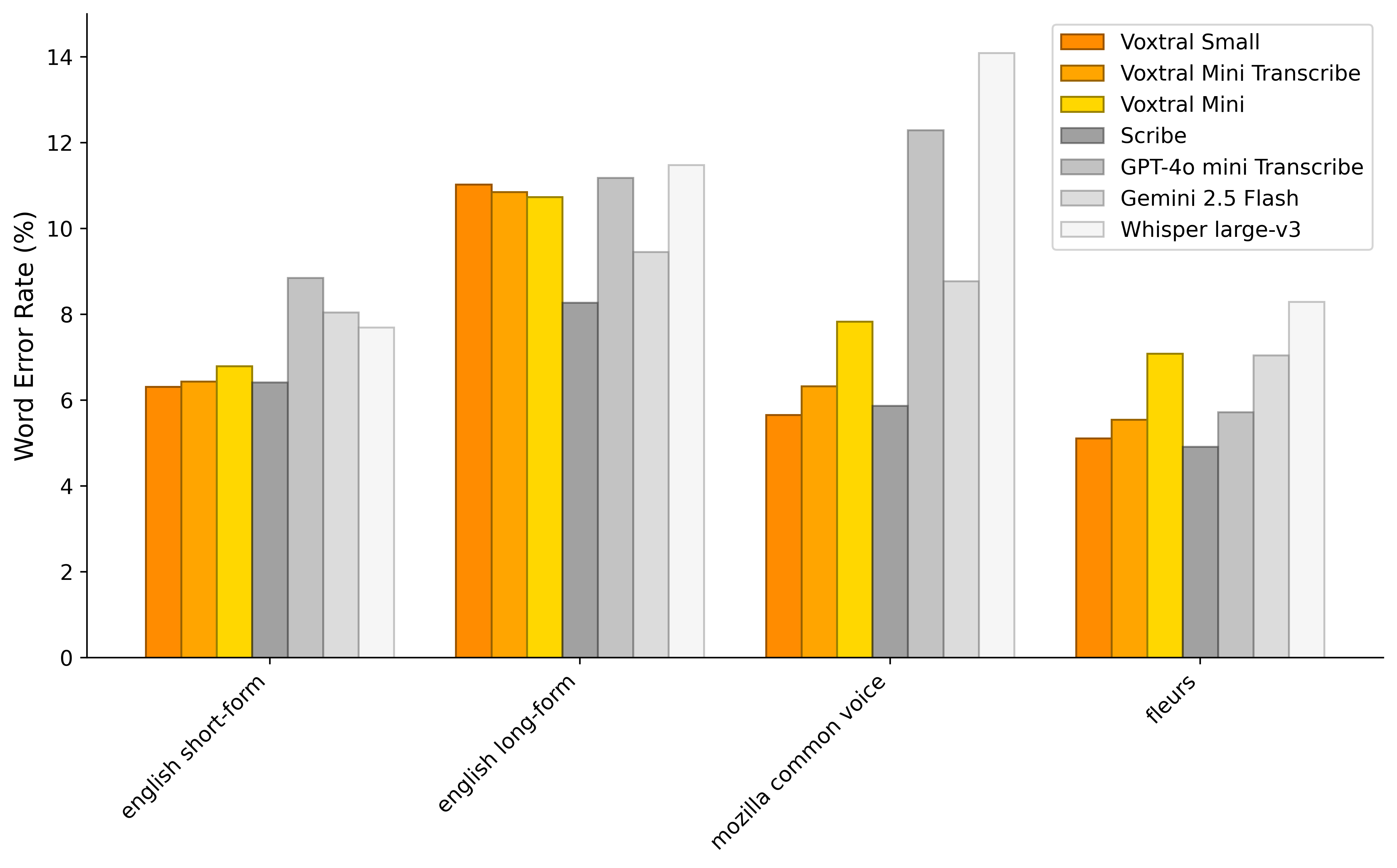
- Voxtral Small在音频基准测试中超越了多个闭源模型,并开源了模型和评估基准。
📝 摘要(中文)
本文介绍了Voxtral Mini和Voxtral Small,两个多模态音频聊天模型。Voxtral经过训练,能够理解口语音频和文本文件,在各种音频基准测试中实现了最先进的性能,同时保持了强大的文本处理能力。Voxtral Small的性能优于许多闭源模型,并且足够小,可以在本地运行。32K的上下文窗口使该模型能够处理长达40分钟的音频文件和长时间的多轮对话。此外,本文还贡献了三个基准测试,用于评估语音理解模型在知识和琐事方面的能力。两个Voxtral模型均以Apache 2.0许可证发布。
🔬 方法详解
问题定义:现有音频理解模型在处理长音频文件和进行长时间多轮对话时面临挑战。此外,许多高性能模型是闭源的,限制了研究和应用。因此,需要一种能够处理长音频、支持多轮对话,并且性能优越的开源模型。
核心思路:Voxtral的核心思路是构建一个能够同时理解音频和文本的多模态模型。通过联合训练音频和文本数据,模型可以学习到音频和文本之间的关联,从而提高音频理解的性能。此外,通过扩大模型的上下文窗口,使其能够处理更长的音频文件和更长的对话历史。
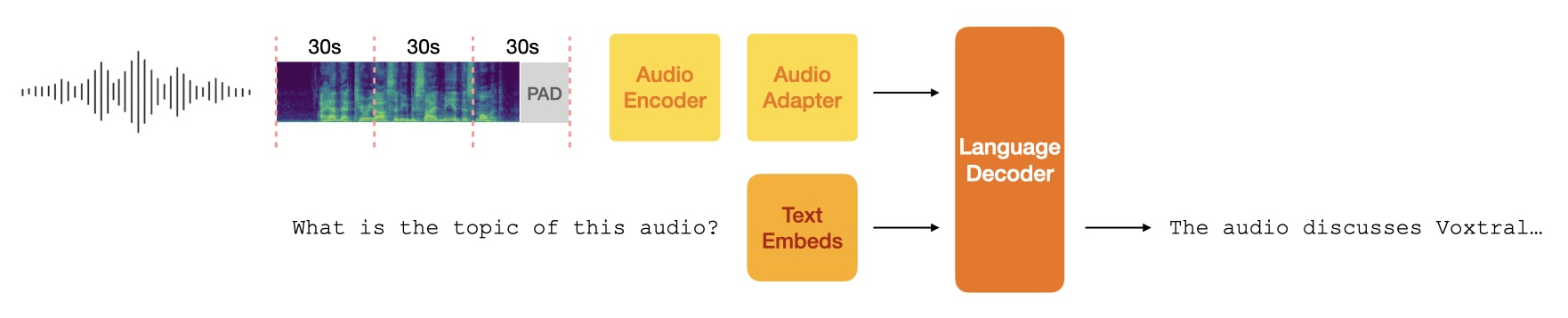
技术框架:Voxtral的技术框架基于Transformer架构,包含音频编码器和文本编码器。音频编码器将音频信号转换为特征向量,文本编码器将文本转换为特征向量。然后,将音频和文本的特征向量输入到Transformer解码器中,生成文本回复。模型采用预训练和微调相结合的训练策略,首先在大量的文本数据上进行预训练,然后在音频和文本数据上进行微调。
关键创新:Voxtral的关键创新在于其多模态融合方法和长上下文窗口。通过将音频和文本信息融合在一起,模型可以更好地理解音频内容。32K的上下文窗口使得模型能够处理更长的音频文件和更长的对话历史,从而提高了模型的实用性。此外,开源发布使得研究人员可以更容易地使用和改进该模型。
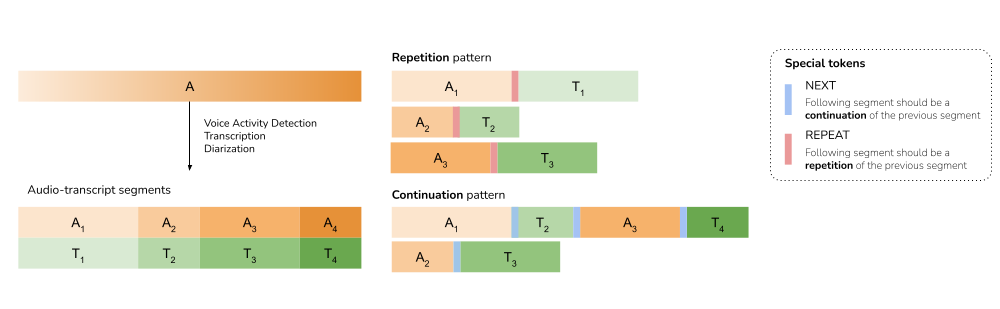
关键设计:Voxtral的关键设计包括:1) 使用预训练的文本模型作为初始化,加速训练过程;2) 设计了专门的音频编码器,能够有效地提取音频特征;3) 采用了32K的上下文窗口,能够处理长音频和长对话;4) 使用了多种数据增强技术,提高了模型的鲁棒性。
🖼️ 关键图片
📊 实验亮点
Voxtral Small在多个音频基准测试中超越了许多闭源模型,证明了其强大的音频理解能力。32K的上下文窗口使其能够处理长达40分钟的音频文件,显著提升了模型的实用性。此外,开源发布促进了研究和应用,加速了语音理解技术的发展。
🎯 应用场景
Voxtral可应用于语音助手、智能客服、音频内容分析、自动语音摘要等领域。其开源特性促进了语音理解技术的发展,并为研究人员和开发者提供了强大的工具。长上下文窗口使其能够处理更复杂的音频任务,例如长时间会议记录分析和长篇有声读物理解。
📄 摘要(原文)
We present Voxtral Mini and Voxtral Small, two multimodal audio chat models. Voxtral is trained to comprehend both spoken audio and text documents, achieving state-of-the-art performance across a diverse range of audio benchmarks, while preserving strong text capabilities. Voxtral Small outperforms a number of closed-source models, while being small enough to run locally. A 32K context window enables the model to handle audio files up to 40 minutes in duration and long multi-turn conversations. We also contribute three benchmarks for evaluating speech understanding models on knowledge and trivia. Both Voxtral models are released under Apache 2.0 license.