From Roots to Rewards: Dynamic Tree Reasoning with Reinforcement Learning
作者: Ahmed Bahloul, Simon Malberg
分类: cs.AI, cs.CL
发布日期: 2025-07-17 (更新: 2025-09-26)
备注: RARA Workshop @ ICDM 2025
🔗 代码/项目: GITHUB
💡 一句话要点
提出基于强化学习的动态树推理框架,提升复杂问答系统的效率和准确性。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 强化学习 树结构推理 动态推理 问答系统 知识集成
📋 核心要点
- 现有思维链和检索增强的语言模型在复杂问题上易出现误差累积和知识融合困难。
- 提出动态强化学习框架,自适应构建推理树,并学习最优策略进行动作选择,提升效率。
- 通过选择性扩展和资源分配,在保证概率严谨性的同时,提高了问题解答的质量和计算效率。
📝 摘要(中文)
现代语言模型通过思维链(CoT)推理和检索增强来处理复杂问题,但存在误差传播和知识集成问题。树结构推理方法,特别是概率树(ProbTree)框架,通过将问题分解为层次结构并通过置信度加权聚合参数化和检索到的知识来选择答案,从而缓解这些问题。然而,ProbTree的静态实现存在两个关键限制:(1)推理树在初始构建阶段是固定的,无法动态适应中间结果;(2)每个节点需要穷举评估所有可能的解决方案策略,导致计算效率低下。我们提出了一种动态强化学习框架,将基于树的推理转化为自适应过程。我们的方法基于实时置信度估计增量构建推理树,同时学习用于动作选择(分解、检索或聚合)的最优策略。这保持了ProbTree的概率严谨性,同时通过选择性扩展和集中资源分配来提高解决方案质量和计算效率。这项工作为树结构推理建立了一个新的范例,该范例平衡了概率框架的可靠性与实际问答系统所需的灵活性。
🔬 方法详解
问题定义:论文旨在解决现有树结构推理方法,如ProbTree,在处理复杂问题时存在的静态性和低效性问题。ProbTree在推理树构建完成后无法动态调整,且每个节点需要评估所有可能的解决方案,导致计算资源浪费和效率低下。
核心思路:论文的核心思路是将树结构推理过程转化为一个动态的、自适应的过程。通过引入强化学习,模型可以根据中间结果的置信度动态地构建推理树,并学习最优的动作选择策略(分解、检索或聚合),从而实现更高效和准确的问题解答。
技术框架:整体框架包含以下几个主要模块:1) 环境:定义了问题解答任务,包括输入问题、外部知识库等;2) 智能体:负责根据当前状态选择动作,例如分解问题、检索相关知识或聚合已有信息;3) 状态:表示当前推理树的状态,包括已生成的节点、每个节点的置信度等;4) 奖励函数:用于评估智能体选择的动作的质量,例如根据最终答案的准确性给予奖励。智能体通过与环境交互,不断学习和优化其策略。
关键创新:最重要的技术创新点在于将强化学习引入到树结构推理中,实现了推理树的动态构建和动作选择的自适应优化。与传统的静态树结构推理方法相比,该方法能够根据中间结果动态调整推理路径,避免了不必要的计算,并提高了问题解答的准确性。
关键设计:论文的关键设计包括:1) 状态表示:如何有效地表示当前推理树的状态,以便智能体能够做出明智的决策;2) 动作空间:如何定义合理的动作空间,包括分解问题的粒度、检索知识的范围等;3) 奖励函数:如何设计合适的奖励函数,以鼓励智能体选择更有效的推理路径;4) 强化学习算法:选择合适的强化学习算法(例如,Q-learning、Policy Gradient等)来训练智能体。
🖼️ 关键图片
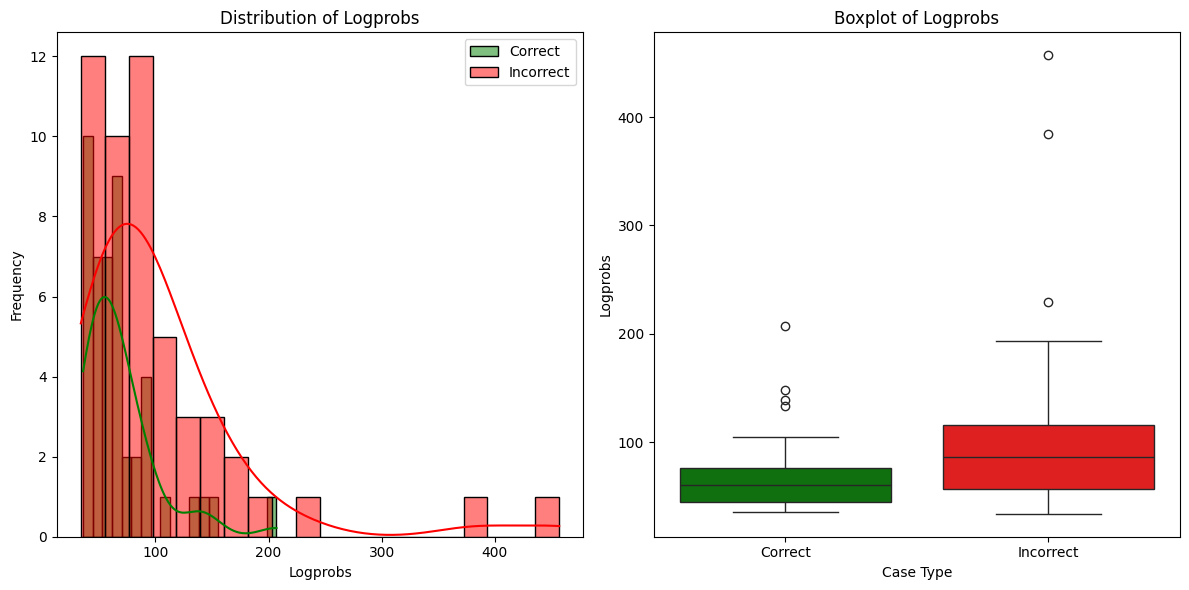
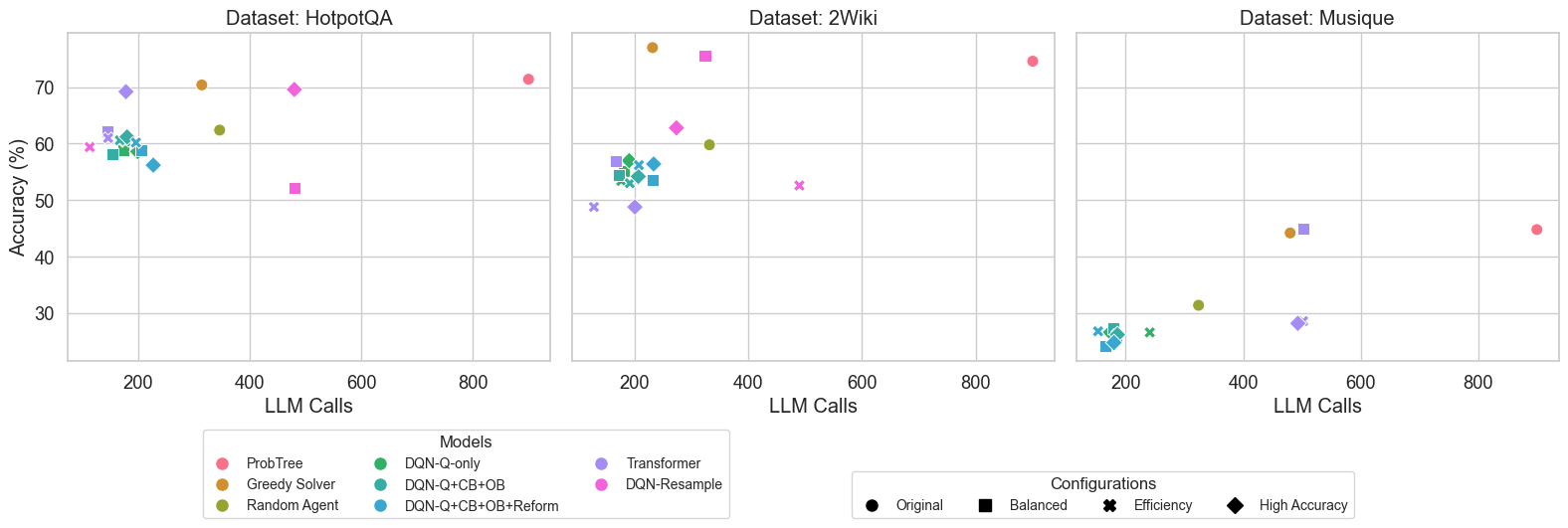
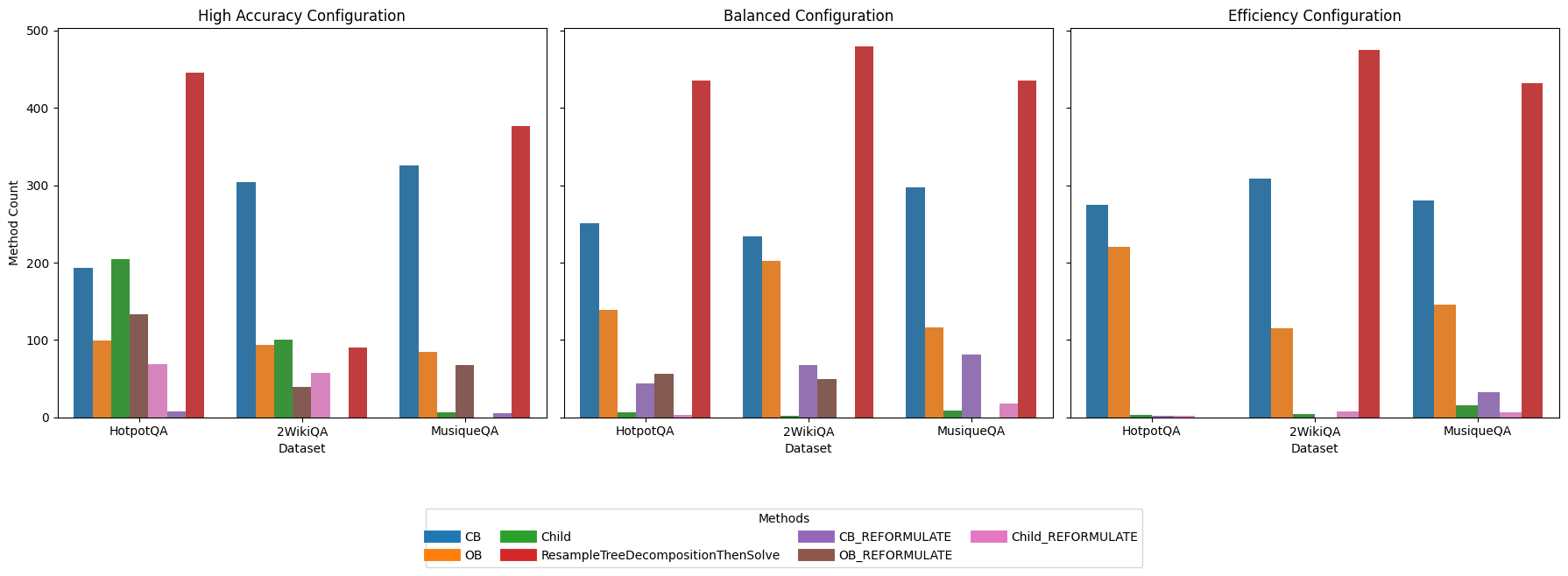
📊 实验亮点
论文提出了基于强化学习的动态树推理框架,通过实验验证了其在复杂问答任务上的有效性。与静态的ProbTree相比,该方法在保持或提高解答准确性的同时,显著降低了计算成本。具体性能提升数据未知,但论文强调了选择性扩展和集中资源分配带来的效率提升。
🎯 应用场景
该研究成果可应用于各种需要复杂推理和知识集成的问答系统,例如智能客服、医学诊断、法律咨询等。通过动态调整推理路径和优化资源分配,可以显著提高这些系统的效率和准确性,从而提供更优质的服务。此外,该方法还可以扩展到其他领域,例如规划、决策等。
📄 摘要(原文)
Modern language models address complex questions through chain-of-thought (CoT) reasoning (Wei et al., 2023) and retrieval augmentation (Lewis et al., 2021), yet struggle with error propagation and knowledge integration. Tree-structured reasoning methods, particularly the Probabilistic Tree-of-Thought (ProbTree)(Cao et al., 2023) framework, mitigate these issues by decomposing questions into hierarchical structures and selecting answers through confidence-weighted aggregation of parametric and retrieved knowledge (Yao et al., 2023). However, ProbTree's static implementation introduces two key limitations: (1) the reasoning tree is fixed during the initial construction phase, preventing dynamic adaptation to intermediate results, and (2) each node requires exhaustive evaluation of all possible solution strategies, creating computational inefficiency. We present a dynamic reinforcement learning (Sutton and Barto, 2018) framework that transforms tree-based reasoning into an adaptive process. Our approach incrementally constructs the reasoning tree based on real-time confidence estimates, while learning optimal policies for action selection (decomposition, retrieval, or aggregation). This maintains ProbTree's probabilistic rigor while improving both solution quality and computational efficiency through selective expansion and focused resource allocation. The work establishes a new paradigm for treestructured reasoning that balances the reliability of probabilistic frameworks with the flexibility required for real-world question answering systems. Code available at: https://github.com/ahmedehabb/From-Roots-to-Rewards-Dynamic-Tree-Reasoning-with-RL