Let's Think in Two Steps: Mitigating Agreement Bias in MLLMs with Self-Grounded Verification
作者: Moises Andrade, Joonhyuk Cha, Brandon Ho, Vriksha Srihari, Karmesh Yadav, Zsolt Kira
分类: cs.AI, cs.CL, cs.LG, cs.MA, cs.RO
发布日期: 2025-07-15 (更新: 2025-12-23)
备注: Our code, models, and data are publicly available at https://mshalimay.github.io/agreement-bias-sgv/
💡 一句话要点
提出自校准验证(SGV)方法,缓解多模态大语言模型验证器中的一致性偏差问题
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态大语言模型 验证器 一致性偏差 自校准验证 机器人控制
📋 核心要点
- 现有的AI验证器在复杂任务中缺乏明确的成功标准,导致难以进行有效的奖励分配和行为评估。
- 论文提出Self-Grounded Verification (SGV)方法,利用MLLM的先验知识和推理能力,生成独立的期望行为,并以此为基础进行验证。
- 实验表明,SGV在多个任务中显著提升了验证的准确性和任务完成度,并在VisualWebArena上取得了新的SOTA。
📝 摘要(中文)
验证器在数学和代码等领域对人工智能的进步至关重要。然而,将这些优势扩展到没有明确成功标准的领域(例如,计算机使用)仍然是一个挑战。多模态大语言模型(MLLM)凭借其世界知识、人类偏好对齐和推理能力,成为一个有希望的解决方案。我们评估了MLLM作为网络导航、计算机使用和机器人操作等领域的验证器,并发现了一个关键限制:过度验证agent行为的强烈倾向,我们称之为一致性偏差。这种偏差在各种模型中普遍存在,对测试时缩放具有弹性,并对依赖MLLM评估的现有方法构成风险。我们讨论了评估和改进MLLM验证器的方法,并引入了自校准验证(SGV),这是一种轻量级方法,通过调节(无)条件生成来利用MLLM自身的采样机制,从而更好地利用其知识、对齐和推理能力。SGV分两步进行:首先,引导MLLM生成关于期望行为的广泛先验,独立于被评估的数据。然后,以自我生成的先验为条件,推理并评估候选轨迹。SGV产生更符合人类的评估,在失败检测方面提高了高达25个百分点,在准确性方面提高了14个百分点,并且优势扩展到下游应用。在自我完善和在线监督中,SGV提高了OSWorld中GUI专家的任务完成度,robomimic中扩散策略的任务完成度,以及VisualWebArena中ReAct agent的任务完成度——创造了新的state of the art,超过了之前的最佳水平20个百分点。我们发布了VisualWebArena的更新版本,其中包含更符合人类的评估器、高保真环境并行性和超过10倍的加速。
🔬 方法详解
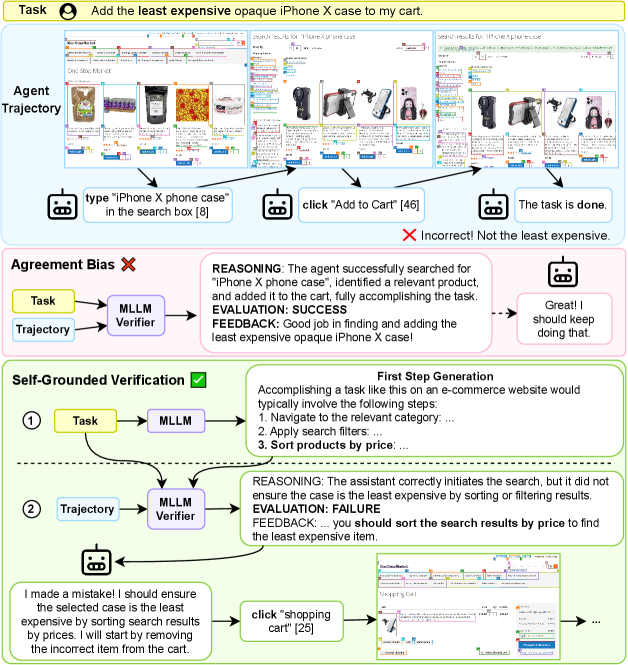
问题定义:论文旨在解决多模态大语言模型(MLLM)作为验证器时存在的“一致性偏差”问题。这种偏差表现为MLLM倾向于过度验证agent的行为,即使这些行为并不理想。现有方法难以有效利用MLLM的知识和推理能力,导致验证结果与人类直觉不符,影响下游任务的性能。
核心思路:论文的核心思路是利用MLLM自身的采样机制,通过生成独立的先验知识来调节其验证行为。具体来说,首先让MLLM在不依赖于待评估数据的情况下,生成关于期望行为的广泛先验。然后,以这些先验为条件,让MLLM对候选轨迹进行推理和评估。这种方法可以更好地利用MLLM的知识、对齐和推理能力,从而减少一致性偏差。
技术框架:SGV方法包含两个主要步骤: 1. 先验生成阶段:MLLM被引导生成关于期望行为的先验知识,这一过程独立于待评估的agent行为轨迹。 2. 验证阶段:MLLM以生成的先验知识为条件,对agent的候选轨迹进行推理和评估,输出验证结果。
关键创新:SGV的关键创新在于其利用MLLM自身生成先验知识,从而调节其验证行为。这种方法避免了直接依赖于待评估数据,减少了过度验证的风险,并更好地利用了MLLM的内在能力。与现有方法相比,SGV更加轻量级,易于实现,并且能够显著提升验证的准确性和任务完成度。
关键设计:SGV的关键设计包括: 1. 先验生成方式:论文可能采用了特定的prompt engineering技术,引导MLLM生成高质量的先验知识。 2. 条件推理方式:论文可能设计了特定的方式,将生成的先验知识融入到MLLM的推理过程中,例如通过attention机制或prompt拼接等。 3. 损失函数或评估指标:论文可能使用了特定的损失函数或评估指标,来衡量SGV的性能,并进行模型优化。(具体细节未知)
🖼️ 关键图片

📊 实验亮点
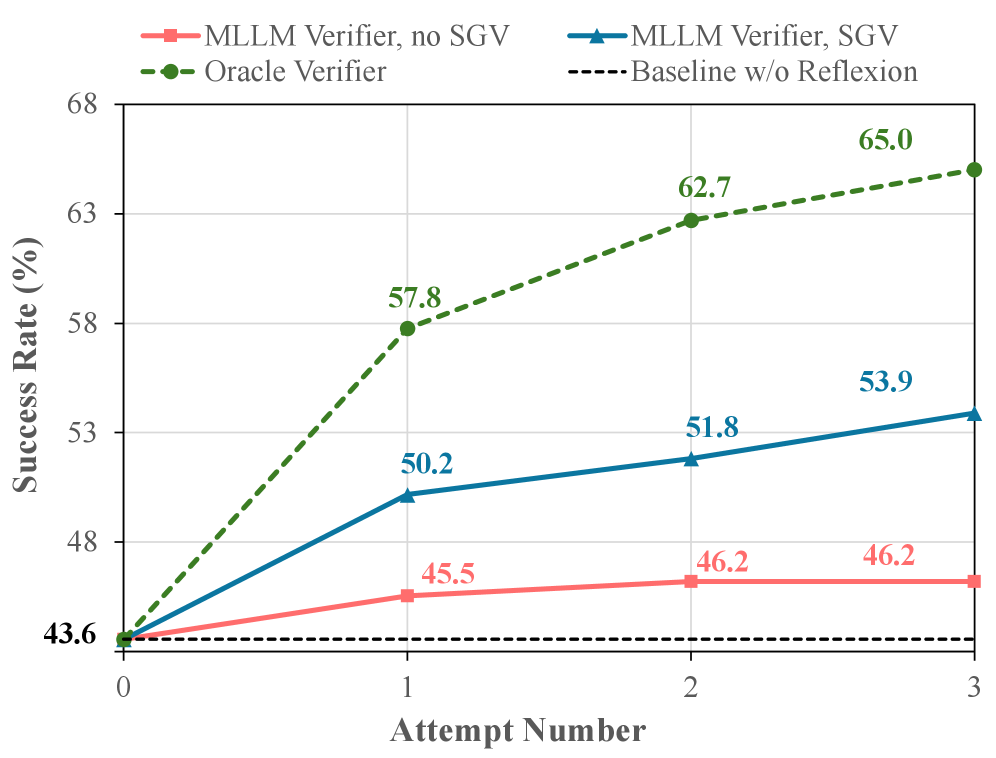
实验结果表明,SGV在失败检测方面提高了高达25个百分点,在准确性方面提高了14个百分点。在OSWorld、robomimic和VisualWebArena等任务中,SGV显著提升了任务完成度,并在VisualWebArena上创造了新的SOTA,超过了之前的最佳水平20个百分点。这些结果表明SGV是一种有效的缓解一致性偏差的方法。
🎯 应用场景
该研究成果可应用于各种需要AI验证器的场景,例如机器人控制、自动驾驶、游戏AI等。通过提高验证器的准确性和可靠性,可以提升AI系统的性能和安全性,并促进AI技术在更广泛领域的应用。此外,该研究对于理解和缓解大语言模型中的偏差问题具有重要的理论价值。
📄 摘要(原文)
Verifiers--functions assigning rewards to agent behavior--have been key for AI progress in domains like math and code. However, extending gains to domains without clear-cut success criteria (e.g., computer use) remains a challenge: while humans can recognize desired outcomes, translating this intuition into scalable rules is nontrivial. Multimodal Large Language Models (MLLMs) emerge as a promising solution, given their world knowledge, human-preference alignment, and reasoning skills. We evaluate MLLMs as verifiers across web navigation, computer use, and robotic manipulation, and identify a critical limitation: a strong tendency to over-validate agent behavior, a phenomenon we term agreement bias. This bias is pervasive across models, resilient to test-time scaling, and poses risks to existing methods relying on MLLM evaluations. We discuss methods to evaluate and improve MLLM verifiers and introduce Self-Grounded Verification (SGV), a lightweight method that harnesses MLLMs' own sampling mechanisms by modulating (un)conditional generation to better leverage their knowledge, alignment, and reasoning. SGV operates in two steps: first, the MLLM is elicited to generate broad priors about desired behavior, independent of the data under evaluation. Then, conditioned on self-generated priors, it reasons over and evaluates a candidate trajectory. SGV yields more human-aligned evaluations with gains of up to 25pp in failure detection, 14pp in accuracy, and benefits extending to downstream applications. In self-refinement and online supervision, SGV boosts task completion of a GUI specialist in OSWorld, a diffusion policy in robomimic, and a ReAct agent in VisualWebArena--setting a new state of the art, surpassing the previous best by 20pp. We release an updated version of VisualWebArena featuring more human-aligned evaluators, high-fidelity environment parallelism, and speedups of over 10x.