CodeAssistBench (CAB): Dataset & Benchmarking for Multi-turn Chat-Based Code Assistance
作者: Myeongsoo Kim, Shweta Garg, Baishakhi Ray, Varun Kumar, Anoop Deoras
分类: cs.SE, cs.AI
发布日期: 2025-07-14 (更新: 2026-01-15)
备注: Accepted to NeurIPS 2025 Datasets and Benchmarks Track
🔗 代码/项目: GITHUB
💡 一句话要点
提出CodeAssistBench,用于评估多轮对话代码辅助的基准测试。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 代码辅助 基准测试 多轮对话 大型语言模型 代码生成 GitHub 项目环境
📋 核心要点
- 现有代码辅助基准测试主要集中在单轮交互和孤立的代码片段,缺乏对真实项目环境和多轮对话的支持。
- CodeAssistBench (CAB) 提出了一种自动化的数据集构建流程,能够从 GitHub issues 中提取可运行的上下文,并构建可执行的容器。
- 实验结果表明,现有 LLM 在 Stack Overflow 风格的问题上表现良好,但在 CAB 的真实项目问题上性能显著下降。
📝 摘要(中文)
大型语言模型驱动的编程助手取得了显著进步,但现有基准测试仍局限于狭窄的代码生成设置。InfiBench和StackEval等最新成果依赖Stack Overflow问题,且仅限于单轮交互、手动管理数据和孤立代码片段,而非完整的项目环境。我们推出了CodeAssistBench (CAB),这是首个用于大规模评估多轮、基于项目的编程辅助的基准。CAB自动从GitHub问题中构建数据集,使用LLM驱动的管道过滤噪声、提取可运行上下文、构建可执行容器并验证环境正确性。这实现了跨不同存储库的持续、自动扩展,无需人工干预。使用CAB,我们创建了一个包含214个存储库中3,286个真实问题的测试平台,涵盖七种语言。评估最先进的模型揭示了一个巨大的差距:虽然模型在Stack Overflow风格的问题上实现了70-83%的准确率,但它们仅解决了来自训练后截止存储库的7.22-16.49%的CAB问题。这些结果突显了一个根本挑战:尽管当前LLM在传统问答基准测试中表现出色,但它们难以在真实的、特定于项目的上下文中提供帮助。CAB为推进多轮、基于代码库的编程代理的研究提供了一个可扩展、可重现的框架。该基准和管道是完全自动化的,并在https://github.com/amazon-science/CodeAssistBench/上公开。
🔬 方法详解
问题定义:论文旨在解决现有代码辅助评估基准的不足,即缺乏对多轮对话和真实项目环境的支持。现有方法主要依赖于Stack Overflow等问答平台的数据,这些数据通常是单轮交互,并且缺乏完整的项目上下文。这使得评估结果难以反映模型在实际编程场景中的表现。
核心思路:论文的核心思路是构建一个自动化的数据集生成流程,该流程能够从 GitHub issues 中提取问题,并自动构建可运行的项目环境。通过这种方式,可以生成大规模、真实的项目代码辅助数据集,从而更全面地评估模型的性能。
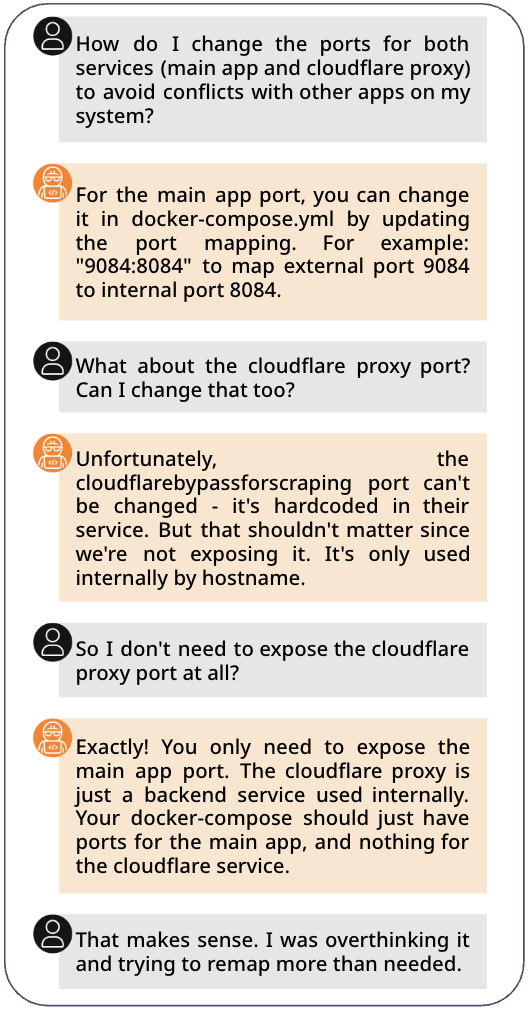
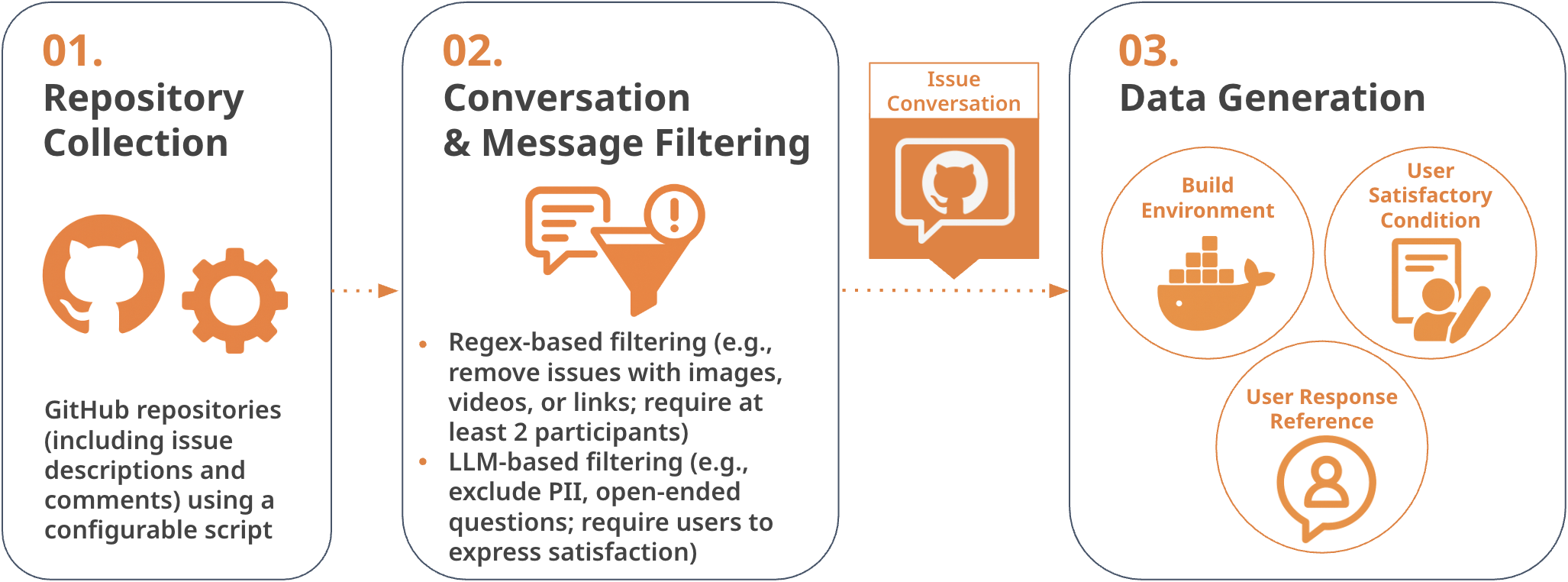
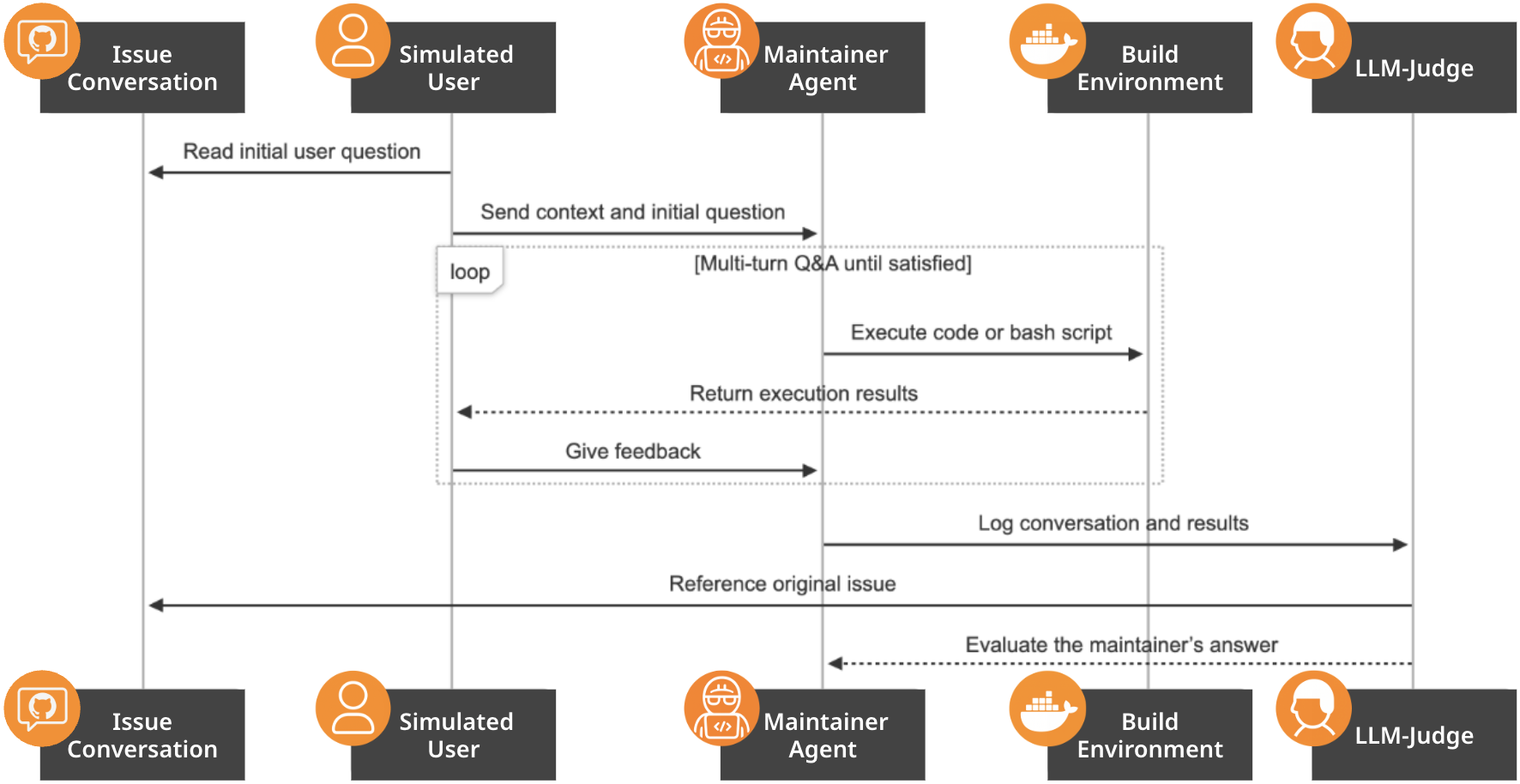
技术框架:CAB 的整体框架包含以下几个主要模块:1) 问题提取:从 GitHub issues 中提取标记为问题的问题;2) 上下文提取:从 issue 相关的代码库中提取可运行的代码上下文;3) 环境构建:使用 Docker 等技术构建可执行的容器环境;4) 问题验证:验证构建的环境是否能够复现 issue 中描述的问题。整个流程由 LLM 驱动,用于过滤噪声、提取信息和验证环境。
关键创新:CAB 的关键创新在于其自动化的数据集生成流程。该流程能够从 GitHub issues 中自动提取问题,并构建可运行的项目环境,从而避免了手动标注的成本和偏差。此外,CAB 还能够处理多轮对话,并评估模型在真实项目环境中的表现。
关键设计:CAB 使用 LLM 来过滤噪声和提取信息。例如,LLM 用于判断 issue 是否包含代码辅助相关的问题,以及提取 issue 中描述的问题和代码上下文。此外,CAB 还使用 Docker 等技术来构建可执行的容器环境,以确保环境的可重现性。
🖼️ 关键图片
📊 实验亮点
实验结果表明,现有 LLM 在 Stack Overflow 风格的问题上取得了 70-83% 的准确率,但在 CAB 的真实项目问题上,准确率仅为 7.22-16.49%。这表明现有 LLM 在处理真实项目环境中的代码辅助任务时仍然存在很大的差距。CAB 提供了一个更具挑战性的评估基准,可以帮助研究人员更好地了解现有模型的局限性,并开发出更有效的代码辅助技术。
🎯 应用场景
CodeAssistBench 可用于评估和改进各种代码辅助工具,例如 IDE 插件、代码生成模型和智能调试器。通过提供一个更真实的评估环境,CAB 可以帮助研究人员开发出更有效的代码辅助技术,从而提高软件开发的效率和质量。该基准测试还有助于推动多轮对话和项目级代码理解等领域的研究。
📄 摘要(原文)
Programming assistants powered by large language models have improved dramatically, yet existing benchmarks still evaluate them in narrow code-generation settings. Recent efforts such as InfiBench and StackEval rely on Stack Overflow questions and remain limited to single-turn interactions, manually curated data, and isolated snippets rather than full project environments. We introduce CodeAssistBench (CAB), the first benchmark for evaluating multi-turn, project-grounded programming assistance at scale. CAB automatically constructs datasets from GitHub issues tagged as questions, using an LLM-driven pipeline that filters noise, extracts runnable contexts, builds executable containers, and verifies environment correctness. This enables continuous, automated expansion across diverse repositories without manual intervention. Using CAB, we create a testbed of 3,286 real-world issues across 214 repositories, spanning seven languages. Evaluating state-of-the-art models reveals a substantial gap: while models achieve 70-83% accuracy on Stack Overflow-style questions, they solve only 7.22-16.49% of CAB issues from post-training-cutoff repositories. These results highlight a fundamental challenge: current LLMs struggle to provide assistance in realistic, project-specific contexts despite strong performance on traditional Q&A benchmarks. CAB provides a scalable, reproducible framework for advancing research in multi-turn, codebase-grounded programming agents. The benchmark and pipeline are fully automated and publicly available at https://github.com/amazon-science/CodeAssistBench/.