Chat with AI: The Surprising Turn of Real-time Video Communication from Human to AI
作者: Jiangkai Wu, Zhiyuan Ren, Liming Liu, Xinggong Zhang
分类: cs.NI, cs.AI, cs.HC, cs.MM
发布日期: 2025-07-14 (更新: 2025-11-24)
备注: 9 pages, 10 figures, Proceedings of the 24th ACM Workshop on Hot Topics in Networks (HotNets 2025), College Park, Maryland, USA
🔗 代码/项目: GITHUB
💡 一句话要点
针对AI视频聊天,提出上下文感知视频流以降低延迟并保持MLLM准确性
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: AI视频聊天 实时通信 多模态大语言模型 上下文感知视频流 低延迟 视频编码 降级视频理解 DeViBench
📋 核心要点
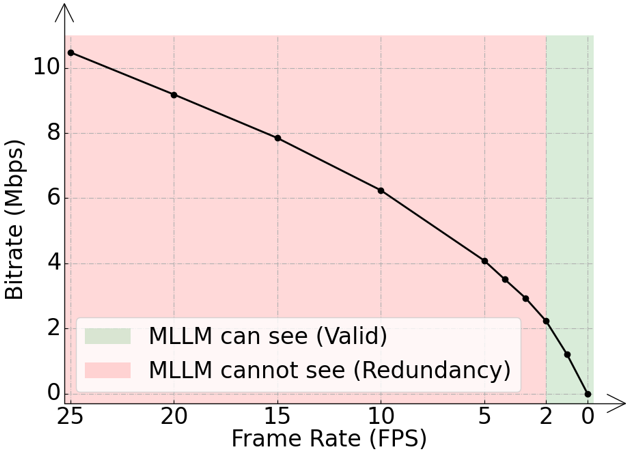
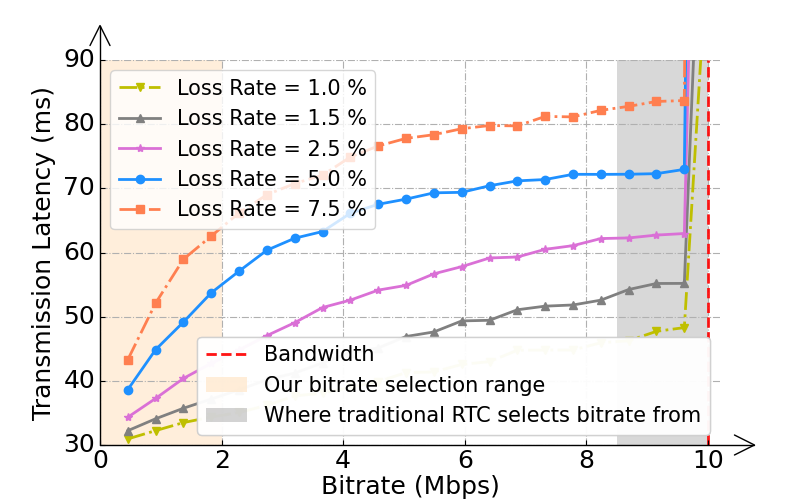
- 传统实时通信(RTC)在AI视频聊天场景中面临延迟挑战,因为MLLM推理耗时,网络传输延迟成为瓶颈。
- 论文提出上下文感知视频流,根据视频区域对聊天的重要性分配比特率,从而在降低比特率的同时保持MLLM准确性。
- 论文构建了降级视频理解基准(DeViBench),用于评估视频流质量对MLLM准确性的影响,并开源了该基准。
📝 摘要(中文)
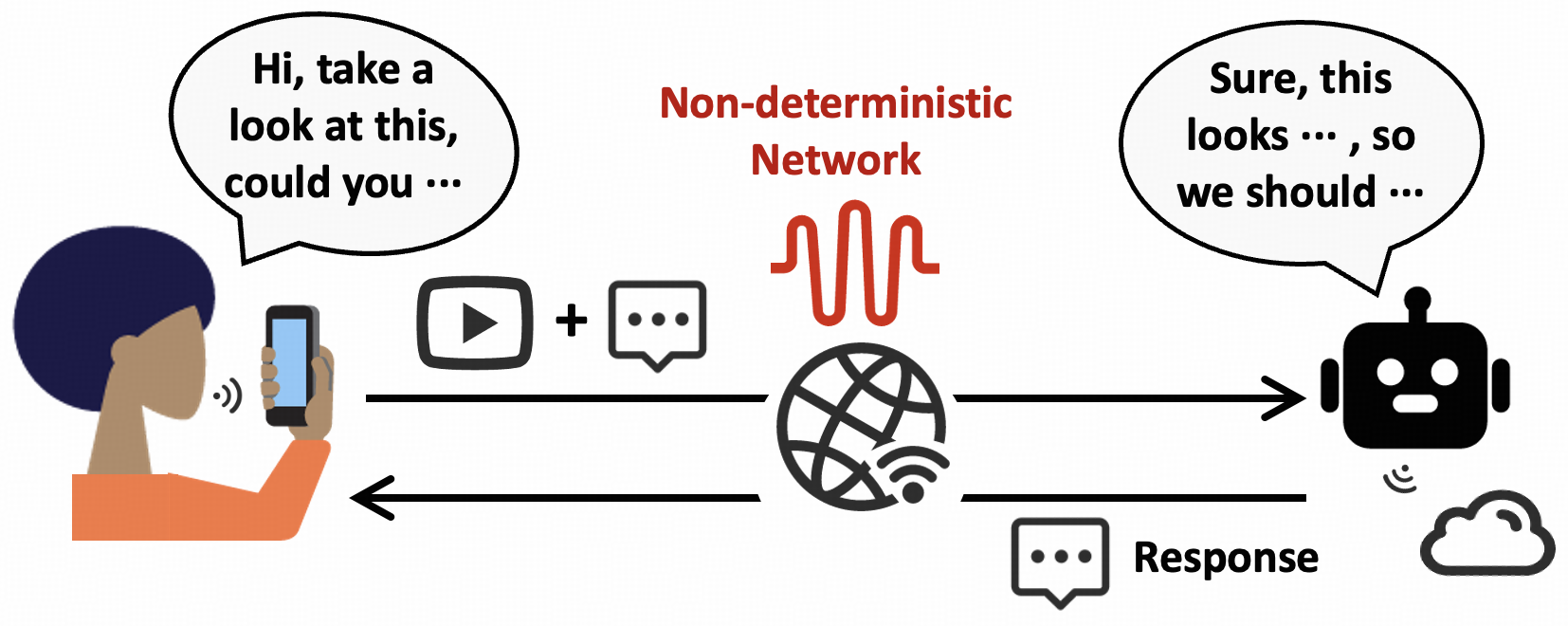
AI视频聊天作为一种新的实时通信(RTC)范式正在兴起,其中一方不再是人类,而是多模态大型语言模型(MLLM)。这使得人与AI之间的交互更加直观,就像与真人面对面聊天一样。然而,这也给延迟带来了重大挑战,因为MLLM推理占据了大部分响应时间,留给视频流的时间非常少。由于网络的不确定性,传输延迟成为阻止AI像真人一样交互的关键瓶颈。为了解决这个问题,我们呼吁以AI为导向的RTC研究,探索网络需求从“人类观看视频”到“AI理解视频”的转变。我们首先认识到AI视频聊天和传统RTC之间的主要区别。然后,通过原型测量,我们确定超低比特率是低延迟的关键因素。为了在显著降低比特率的同时保持MLLM的准确性,我们提出了上下文感知视频流,该方法识别每个视频区域对于聊天的重要性,并将比特率几乎完全分配给聊天重要的区域。为了评估视频流质量对MLLM准确性的影响,我们构建了第一个基准测试,名为降级视频理解基准(DeViBench)。最后,我们讨论了AI视频聊天的一些开放性问题和正在进行的解决方案。DeViBench已开源。
🔬 方法详解
问题定义:论文旨在解决AI视频聊天中由于MLLM推理和网络传输导致的延迟问题。现有方法主要针对“人类观看视频”的场景优化,无法满足“AI理解视频”的需求,导致AI视频聊天的实时性较差。现有视频编码方法没有考虑视频内容对于AI理解的重要性,导致不必要的带宽浪费。
核心思路:论文的核心思路是利用MLLM对视频内容的理解能力,识别出对聊天至关重要的视频区域,并优先为这些区域分配比特率。通过降低非重要区域的比特率,可以显著降低整体比特率,从而降低延迟,同时保证MLLM的准确性。
技术框架:整体框架包含以下几个主要模块:1) 视频采集与预处理;2) MLLM分析:使用MLLM分析视频内容,识别出对聊天重要的区域;3) 上下文感知编码:根据MLLM的分析结果,对视频进行编码,优先保证重要区域的质量;4) 网络传输;5) 解码与显示/MLLM推理。
关键创新:论文的关键创新在于提出了上下文感知视频流。与传统的视频编码方法不同,该方法不是均匀地分配比特率,而是根据视频内容对聊天的重要性进行分配。此外,论文还构建了DeViBench,用于评估降质视频对MLLM理解能力的影响。
关键设计:具体的技术细节包括:1) 使用目标检测模型识别视频中的物体;2) 使用MLLM判断哪些物体与当前聊天内容相关;3) 根据物体的重要性,调整编码参数,例如量化参数和帧率;4) 设计了新的损失函数,用于优化编码器,使其能够更好地保留重要区域的信息。
🖼️ 关键图片
📊 实验亮点
论文构建了DeViBench基准测试,并使用该基准测试评估了上下文感知视频流的性能。实验结果表明,该方法可以在显著降低比特率的同时,保持MLLM的准确性。具体来说,该方法可以将比特率降低到传统方法的1/3,而MLLM的准确率仅下降了不到5%。
🎯 应用场景
该研究成果可应用于各种AI助手、虚拟客服、远程教育等领域,实现更自然、流畅的人机交互体验。通过降低延迟,可以使AI更像真人一样进行实时对话,从而提高用户满意度和工作效率。未来,该技术还可以应用于机器人视觉、自动驾驶等领域。
📄 摘要(原文)
AI Video Chat emerges as a new paradigm for Real-time Communication (RTC), where one peer is not a human, but a Multimodal Large Language Model (MLLM). This makes interaction between humans and AI more intuitive, as if chatting face-to-face with a real person. However, this poses significant challenges to latency, because the MLLM inference takes up most of the response time, leaving very little time for video streaming. Due to network uncertainty, transmission latency becomes a critical bottleneck preventing AI from being like a real person. To address this, we call for AI-oriented RTC research, exploring the network requirement shift from "humans watching video" to "AI understanding video". We begin by recognizing the main differences between AI Video Chat and traditional RTC. Then, through prototype measurements, we identify that ultra-low bitrate is a key factor for low latency. To reduce bitrate dramatically while maintaining MLLM accuracy, we propose Context-Aware Video Streaming that recognizes the importance of each video region for chat and allocates bitrate almost exclusively to chat-important regions. To evaluate the impact of video streaming quality on MLLM accuracy, we build the first benchmark, named Degraded Video Understanding Benchmark (DeViBench). Finally, we discuss some open questions and ongoing solutions for AI Video Chat. DeViBench is open-sourced at: https://github.com/pku-netvideo/DeViBench.