Multimodal Fusion at Three Tiers: Physics-Driven Data Generation and Vision-Language Guidance for Brain Tumor Segmentation
作者: Mingda Zhang
分类: eess.IV, cs.AI, cs.CV, cs.LG
发布日期: 2025-07-14 (更新: 2025-10-19)
备注: 31 pages,3 figures
💡 一句话要点
提出三层融合架构,结合物理建模数据生成与视觉-语言引导,提升脑肿瘤分割精度。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱七:动作重定向 (Motion Retargeting) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 脑肿瘤分割 多模态融合 Transformer 物理建模 视觉-语言引导
📋 核心要点
- 脑肿瘤分割面临肿瘤形态异质性和复杂三维空间关系的挑战,现有方法难以实现精确分割。
- 提出三层融合架构,结合物理建模生成多模态数据,利用Transformer进行跨模态特征融合,并引入视觉-语言引导。
- 在BraTS 2020、2021和2023数据集上验证,Dice系数分别达到0.8665、0.9014和0.8912,HD95平均降低6.57毫米。
📝 摘要(中文)
精确的脑肿瘤分割对于神经肿瘤学的诊断和治疗计划至关重要。深度学习方法取得了显著进展,但自动分割仍然面临挑战,包括肿瘤形态异质性和复杂的三维空间关系。本文提出了一种三层融合架构,以实现精确的脑肿瘤分割。该方法在像素、特征和语义级别逐步处理信息。在像素级别,物理建模将磁共振成像(MRI)扩展到多模态数据,包括模拟超声和合成计算机断层扫描(CT)。在特征级别,该方法通过多教师协同蒸馏执行基于Transformer的跨模态特征融合,整合了三个专家教师(MRI、US、CT)。在语义级别,由GPT-4V生成的临床文本知识使用CLIP对比学习和特征线性调制(FiLM)转换为空间引导信号。这三个层级共同构成了一个从数据增强到特征提取再到语义引导的完整处理链。我们在脑肿瘤分割(BraTS)2020、2021和2023数据集上验证了该方法。该模型在三个数据集上分别实现了0.8665、0.9014和0.8912的平均Dice系数,并且与基线相比,95% Hausdorff距离(HD95)平均降低了6.57毫米。该方法为精确的肿瘤分割和边界定位提供了一种新的范例。
🔬 方法详解
问题定义:脑肿瘤分割旨在精确识别和分割MRI图像中的肿瘤区域,为诊断和治疗提供依据。现有方法在处理肿瘤形态多样性和复杂空间关系时存在不足,分割精度有待提高。尤其是在多模态数据融合方面,如何有效利用不同模态的信息是一个挑战。
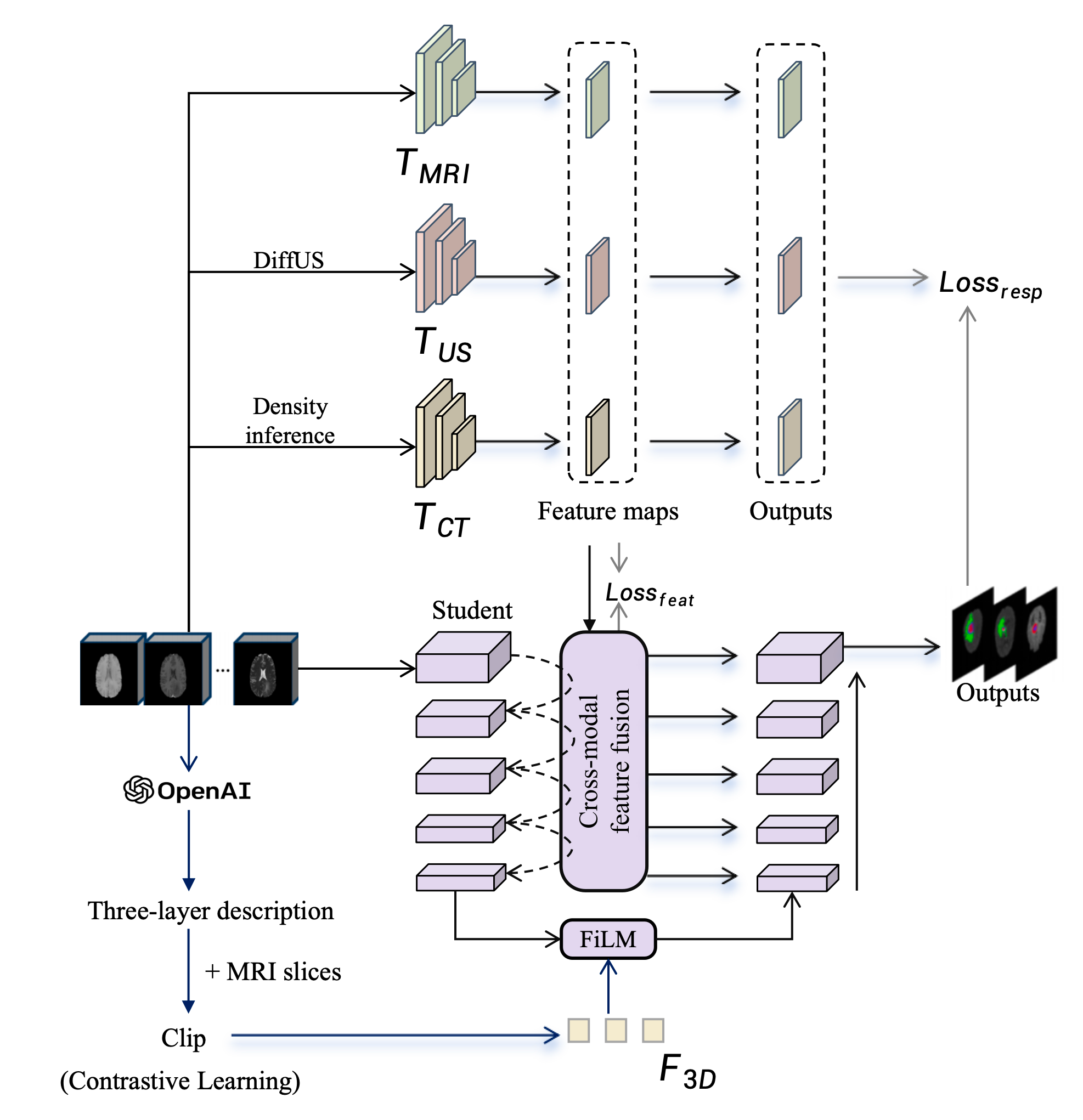
核心思路:论文的核心思路是通过三层融合架构,在像素、特征和语义三个层面逐步整合信息。首先,利用物理建模生成额外的模态数据,增强数据的多样性。然后,通过Transformer进行跨模态特征融合,提取不同模态的互补信息。最后,利用视觉-语言模型生成语义引导,指导分割过程。这种多层次的融合方式旨在充分利用各种信息,提高分割精度。
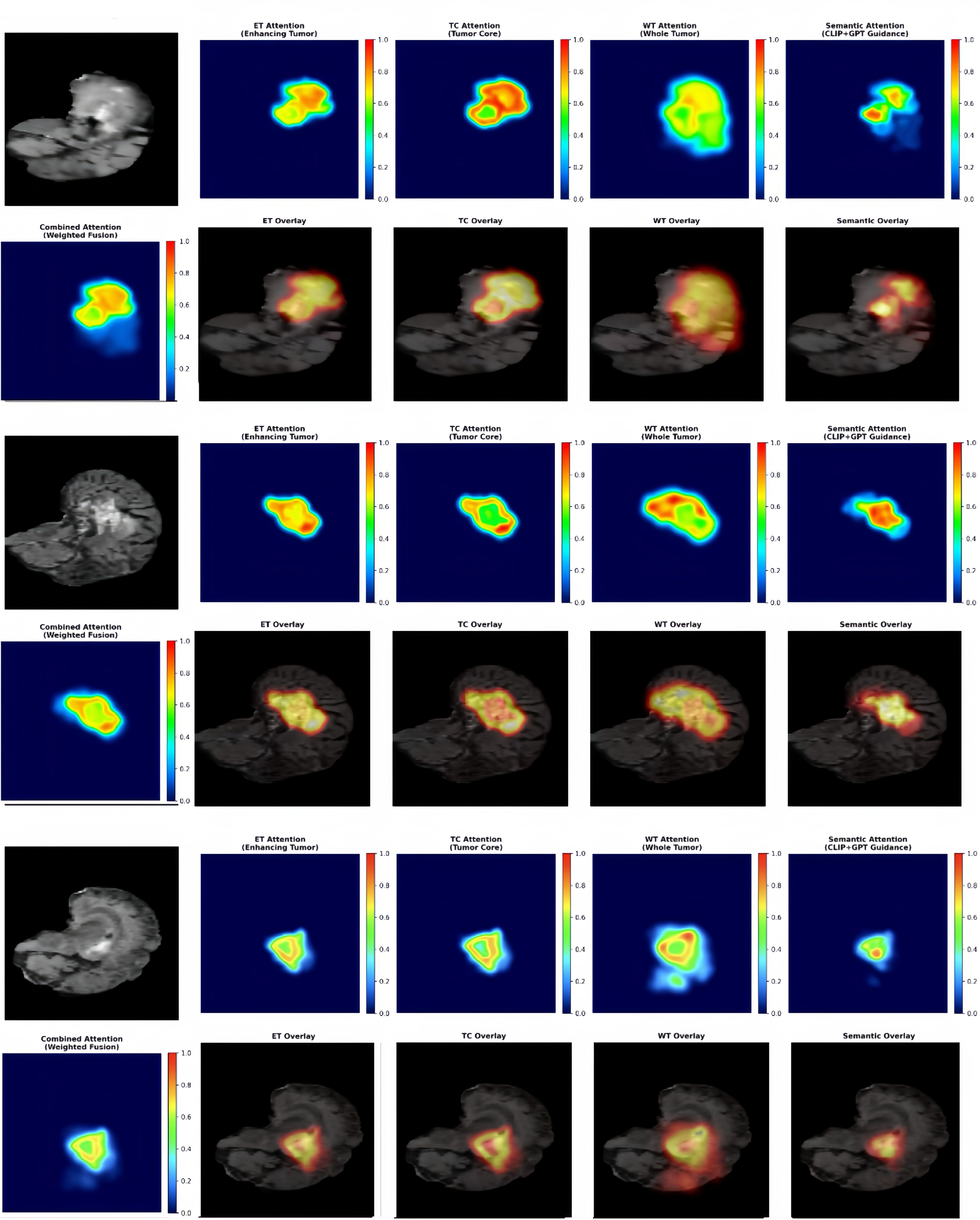
技术框架:该方法包含三个主要阶段:1) 像素级融合:利用物理建模生成模拟超声和合成CT图像,扩展MRI数据。2) 特征级融合:使用Transformer进行跨模态特征融合,通过多教师协同蒸馏,整合MRI、US和CT三种模态的特征。3) 语义级融合:利用GPT-4V生成临床文本知识,通过CLIP对比学习和FiLM,将文本知识转换为空间引导信号,指导分割。
关键创新:该方法最重要的创新点在于三层融合架构的设计,以及将视觉-语言模型引入脑肿瘤分割任务中。通过物理建模生成数据,有效解决了数据稀缺问题。利用Transformer进行跨模态特征融合,能够充分利用不同模态的信息。将临床文本知识转化为空间引导信号,能够提高分割的准确性。
关键设计:在特征级融合中,使用了多教师协同蒸馏,三个教师分别对应MRI、US和CT模态。在语义级融合中,使用了CLIP对比学习,将文本知识与图像特征对齐。FiLM用于将语义引导信号融入到分割网络中。具体的网络结构和损失函数细节未在摘要中详细说明,属于未知信息。
🖼️ 关键图片
📊 实验亮点
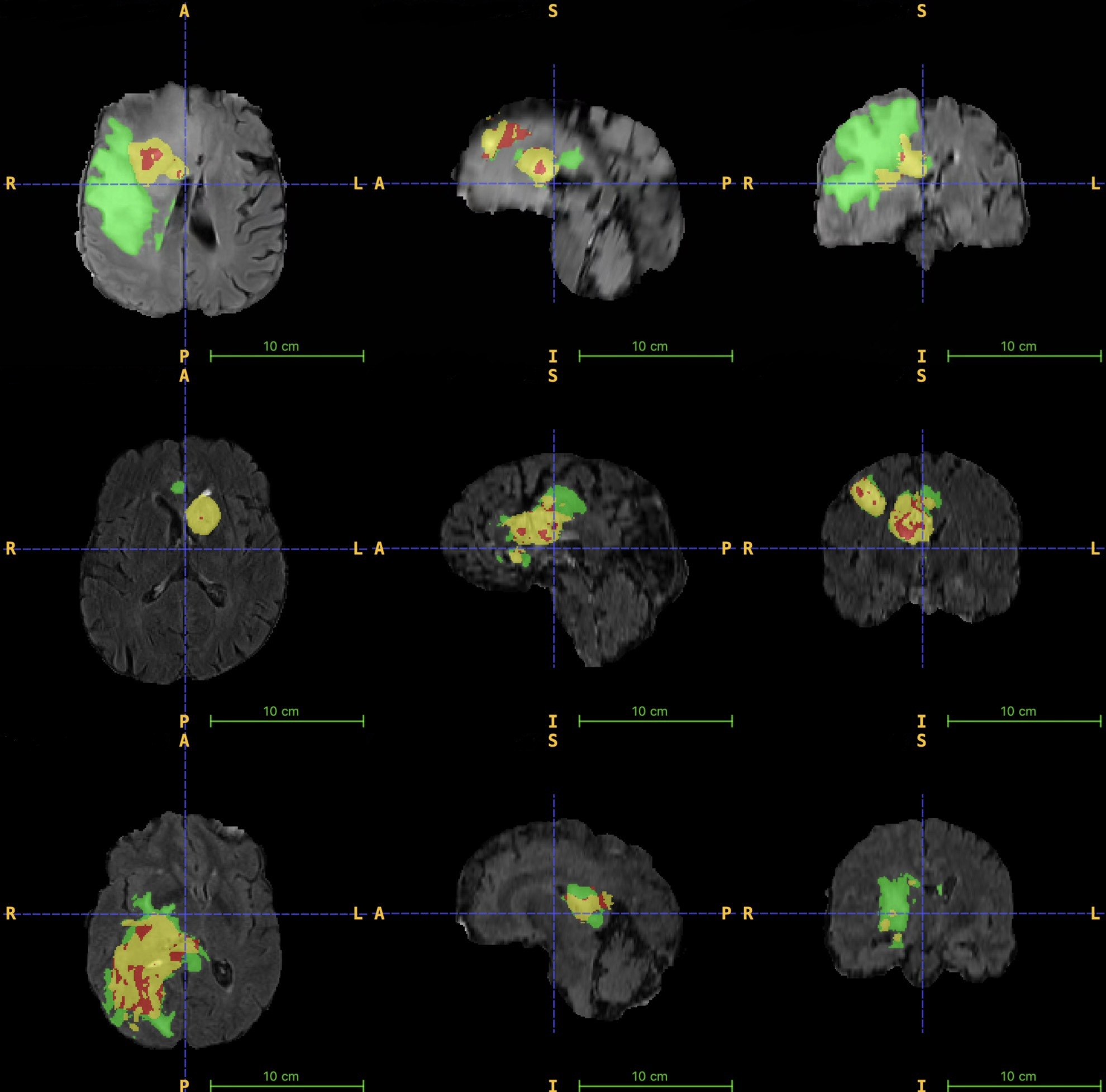
实验结果表明,该方法在BraTS 2020、2021和2023数据集上取得了显著的性能提升。在三个数据集上分别实现了0.8665、0.9014和0.8912的平均Dice系数,并且与基线相比,95% Hausdorff距离(HD95)平均降低了6.57毫米。这些结果表明,该方法能够有效提高脑肿瘤分割的精度和边界定位能力。
🎯 应用场景
该研究成果可应用于神经肿瘤学领域,辅助医生进行脑肿瘤的诊断、治疗计划制定和疗效评估。通过提高脑肿瘤分割的精度,可以更准确地确定肿瘤的位置、大小和形状,从而为手术、放疗和化疗等治疗手段提供更可靠的依据。该方法还可扩展到其他医学图像分割任务中,具有广泛的应用前景。
📄 摘要(原文)
Accurate brain tumor segmentation is crucial for neuro-oncology diagnosis and treatment planning. Deep learning methods have made significant progress, but automatic segmentation still faces challenges, including tumor morphological heterogeneity and complex three-dimensional spatial relationships. This paper proposes a three-tier fusion architecture that achieves precise brain tumor segmentation. The method processes information progressively at the pixel, feature, and semantic levels. At the pixel level, physical modeling extends magnetic resonance imaging (MRI) to multimodal data, including simulated ultrasound and synthetic computed tomography (CT). At the feature level, the method performs Transformer-based cross-modal feature fusion through multi-teacher collaborative distillation, integrating three expert teachers (MRI, US, CT). At the semantic level, clinical textual knowledge generated by GPT-4V is transformed into spatial guidance signals using CLIP contrastive learning and Feature-wise Linear Modulation (FiLM). These three tiers together form a complete processing chain from data augmentation to feature extraction to semantic guidance. We validated the method on the Brain Tumor Segmentation (BraTS) 2020, 2021, and 2023 datasets. The model achieves average Dice coefficients of 0.8665, 0.9014, and 0.8912 on the three datasets, respectively, and reduces the 95% Hausdorff Distance (HD95) by an average of 6.57 millimeters compared with the baseline. This method provides a new paradigm for precise tumor segmentation and boundary localization.