Aligning Generative Speech Enhancement with Perceptual Feedback
作者: Haoyang Li, Nana Hou, Yuchen Hu, Jixun Yao, Sabato Marco Siniscalchi, Xuyi Zhuang, Deheng Ye, Wei Yang, Eng Siong Chng
分类: eess.AS, cs.AI, cs.LG
发布日期: 2025-07-14 (更新: 2026-01-18)
备注: Accepted to ICASSP 2026
💡 一句话要点
提出基于感知反馈对齐的生成式语音增强方法,提升语音质量。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 语音增强 语言模型 感知对齐 直接偏好优化 UTMOS 语音质量评估 深度学习
📋 核心要点
- 现有基于语言模型的语音增强方法依赖于token级似然目标,与人类感知关联弱,优化效果有限。
- 本文提出一种基于感知对齐的语音增强方法,使用直接偏好优化(DPO)和UTMOS预测器,引导模型生成感知上更优的输出。
- 实验结果表明,该方法在语音质量指标上取得了显著提升,相对增益高达56%,验证了其有效性。
📝 摘要(中文)
本文提出了一种基于感知对齐的语言模型(LM)语音增强(SE)方法。现有方法主要依赖于token级别的似然目标,这与人类感知关联较弱,导致优化信号准确性并不总能提高自然度和听觉舒适度。为了解决这个问题,本文利用UTMOS(一种神经MOS预测器)作为人类评分的代理,采用直接偏好优化(DPO)算法,直接引导模型生成感知上更优的输出。这种设计将模型训练与感知质量直接联系起来,并且广泛适用于基于LM的SE框架。在Deep Noise Suppression Challenge 2020测试集上,该方法持续改进语音质量指标,实现了高达56%的相对增益。据我们所知,这是首次将感知反馈整合到基于LM的SE中,也是DPO在SE领域的首次应用,为感知对齐的语音增强建立了一个新的范例。
🔬 方法详解
问题定义:现有基于语言模型的语音增强方法,通常使用token级别的似然函数作为优化目标。这种优化方式的缺点在于,它并不能很好地反映人类的感知,即信号层面的准确性提升,并不一定带来听觉上的舒适度和自然度提升。因此,如何让语音增强模型更好地对齐人类的感知偏好,是一个亟待解决的问题。
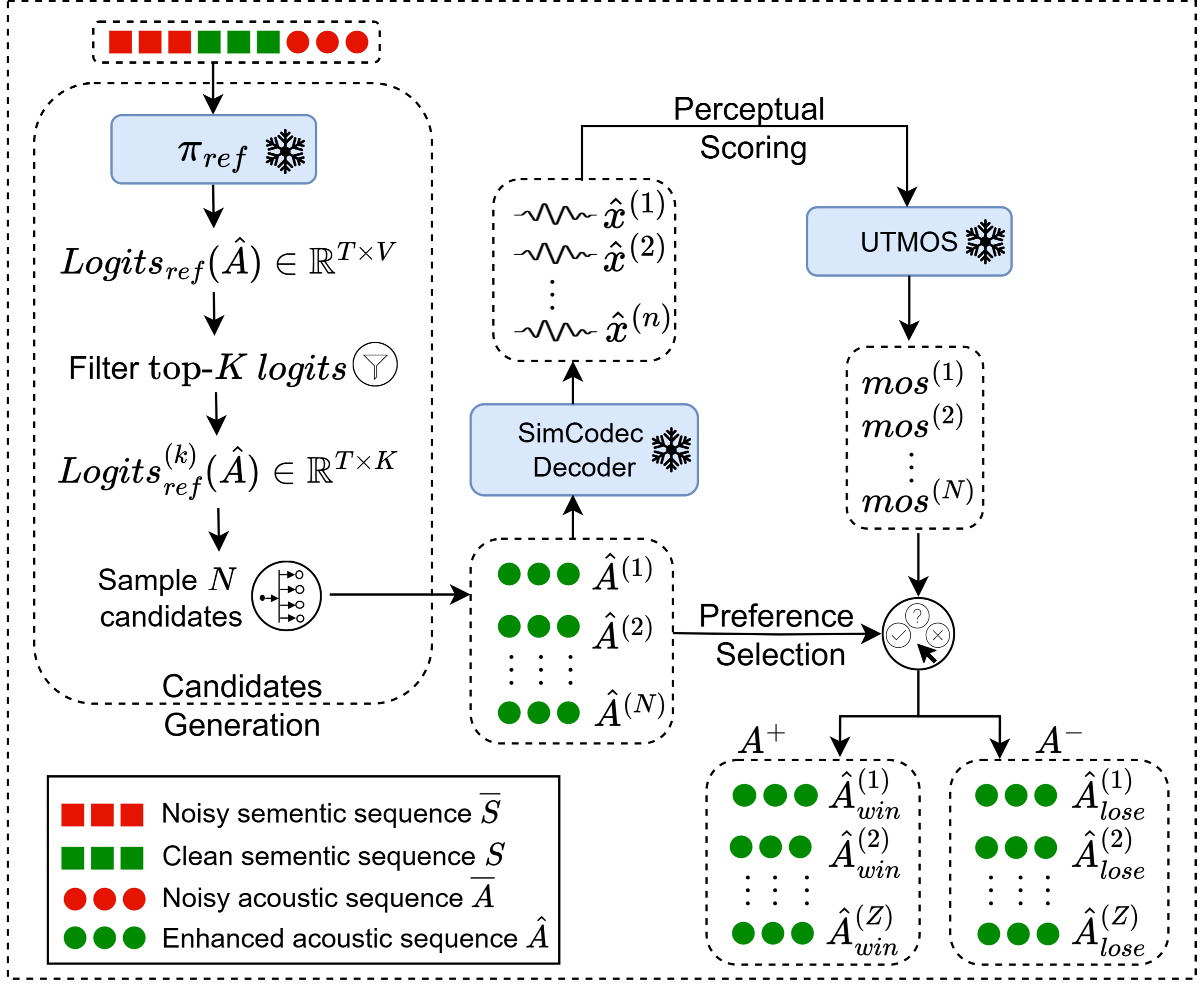
核心思路:本文的核心思路是利用直接偏好优化(DPO)算法,直接将模型的训练目标与人类的感知偏好对齐。具体来说,就是使用一个能够预测人类语音质量评分的神经模型(UTMOS)作为人类评分的代理,然后利用DPO算法,引导模型生成UTMOS评分更高的语音增强结果。
技术框架:该方法的技术框架主要包括以下几个部分:1)一个基于语言模型的语音增强模型,用于生成增强后的语音;2)一个UTMOS模型,用于预测增强后语音的质量评分;3)一个DPO优化器,用于根据UTMOS的评分,调整语音增强模型的参数,使其生成更高质量的语音。整个流程可以看作是一个闭环的反馈系统,通过感知反馈不断优化语音增强模型。
关键创新:本文最重要的技术创新点在于,首次将感知反馈整合到基于语言模型的语音增强中,并首次将DPO算法应用于语音增强领域。这种方法能够直接优化模型的感知质量,从而更好地满足人类的听觉需求。
关键设计:UTMOS模型被用作人类感知偏好的代理,为DPO算法提供优化信号。DPO算法通过比较不同增强结果的UTMOS评分,来调整语音增强模型的参数。损失函数的设计直接基于UTMOS评分的差异,鼓励模型生成评分更高的语音。具体的网络结构和参数设置取决于所使用的语言模型和UTMOS模型。
🖼️ 关键图片
📊 实验亮点
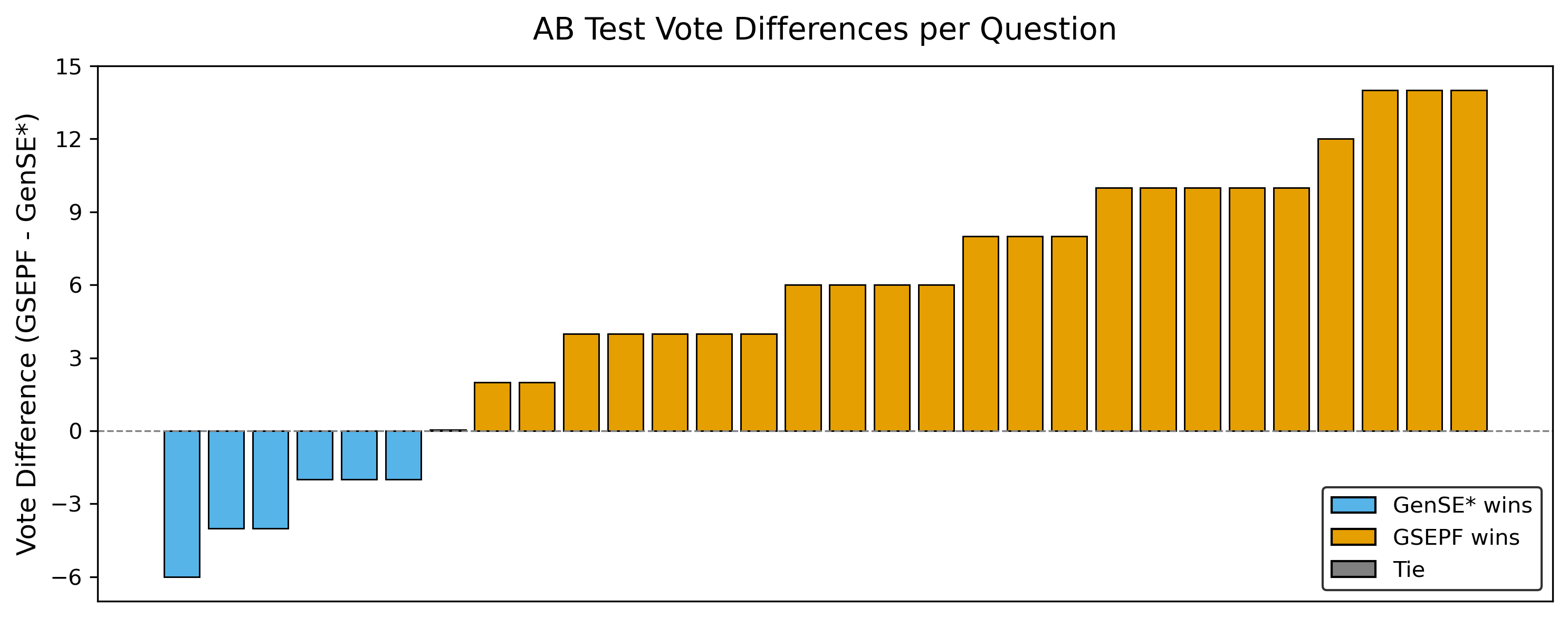
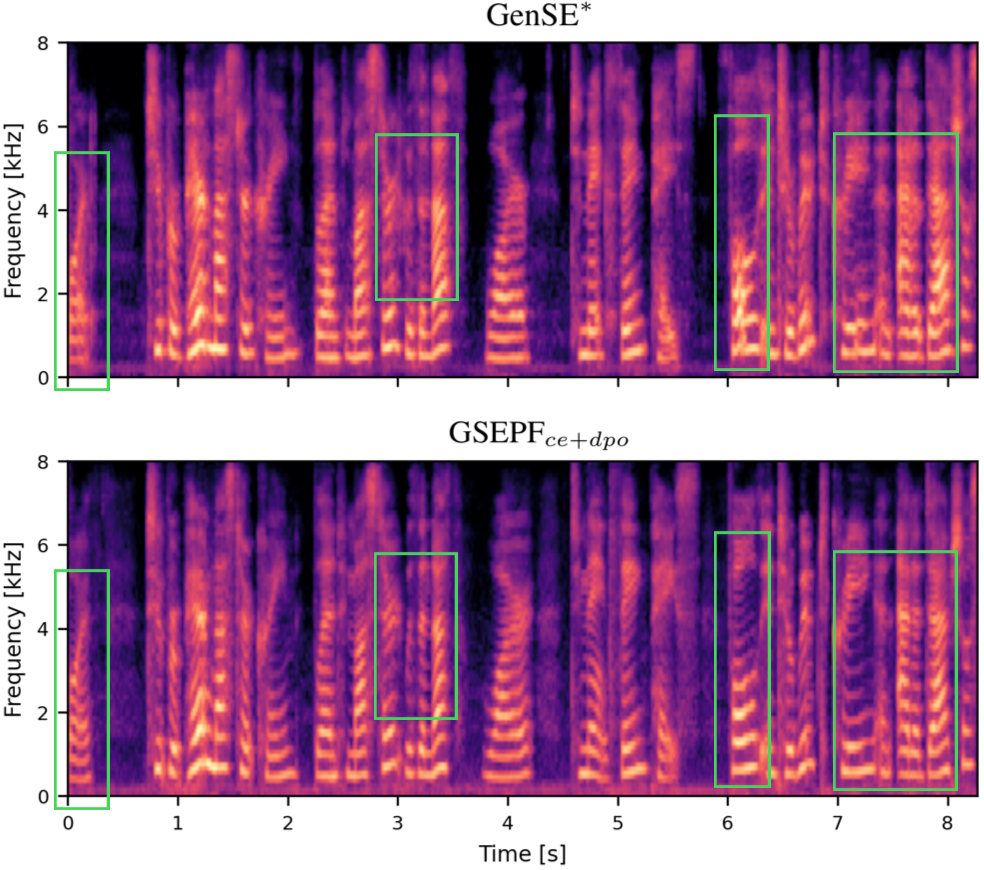
实验结果表明,该方法在Deep Noise Suppression Challenge 2020测试集上取得了显著的性能提升,语音质量指标相对增益高达56%。这表明该方法能够有效地提高语音增强的感知质量,优于传统的基于token级似然函数优化的方法。
🎯 应用场景
该研究成果可广泛应用于语音通信、语音助手、助听设备等领域,提升嘈杂环境下的语音清晰度和用户听觉舒适度。通过感知对齐的语音增强,可以显著改善用户体验,提高语音交互的自然性和可靠性,具有重要的实际应用价值和商业前景。
📄 摘要(原文)
Language Model (LM)-based speech enhancement (SE) has recently emerged as a promising direction, but existing approaches predominantly rely on token-level likelihood objectives that weakly reflect human perception. This mismatch limits progress, as optimizing signal accuracy does not always improve naturalness or listening comfort. We address this gap by introducing a perceptually aligned LM-based SE approach. Our method applies Direct Preference Optimization (DPO) with UTMOS, a neural MOS predictor, as a proxy for human ratings, directly steering models toward perceptually preferred outputs. This design directly connects model training to perceptual quality and is broadly applicable within LM-based SE frameworks. On the Deep Noise Suppression Challenge 2020 test sets, our approach consistently improves speech quality metrics, achieving relative gains of up to 56%. To our knowledge, this is the first integration of perceptual feedback into LM-based SE and the first application of DPO in the SE domain, establishing a new paradigm for perceptually aligned enhancement with SE.