Evaluating LLMs on Sequential API Call Through Automated Test Generation
作者: Yuheng Huang, Jiayang Song, Da Song, Zhenlan Ji, Wenhan Wang, Shuai Wang, Lei Ma
分类: cs.SE, cs.AI, cs.CL
发布日期: 2025-07-13 (更新: 2025-12-02)
💡 一句话要点
提出StateGen框架,自动生成API序列调用测试用例,评估LLM工具使用能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: LLM工具使用 自动化测试生成 API序列调用 状态机建模 基准测试
📋 核心要点
- 现有LLM工具使用评估依赖手动用例,缺乏自动化语义校验,难以覆盖API序列交互的复杂性。
- StateGen框架结合状态机约束求解、能量采样和控制流注入,自动生成多样化的API序列调用编码任务。
- StateEval基准包含120个用例,覆盖会话服务、张量运算等场景,实验表明能有效评估LLM的API使用能力。
📝 摘要(中文)
大型语言模型(LLM)通过集成外部API工具,在复杂的现实世界任务中展现出巨大的潜力。然而,对LLM工具使用的测试、评估和分析仍处于早期阶段。现有基准测试主要依赖于手动收集的测试用例,其中许多无法自动检查语义正确性,而是依赖于字符串匹配等静态方法。此外,这些基准测试通常忽略了API序列调用之间发生的复杂交互,而这在实际应用中很常见。为了填补这一空白,本文介绍了一种自动框架StateGen,旨在生成涉及API序列交互的各种编码任务。StateGen结合了基于状态机的API约束求解和验证、基于能量的采样以及控制流注入来生成可执行程序。然后,通过两个LLM代理的协作,将这些程序翻译成类似人类的自然语言任务描述。利用StateGen,我们构建了StateEval,一个包含120个经过验证的测试用例的基准,涵盖了三个代表性场景:会话服务、张量运算和ElevenLabs MCP。实验结果证实,StateGen可以有效地生成具有挑战性和现实的面向API的任务,突出了当前集成API的LLM需要改进的领域。我们将公开我们的框架和基准,以支持未来的研究。
🔬 方法详解
问题定义:现有LLM工具使用评估benchmark依赖人工构建的测试用例,存在以下痛点:一是缺乏自动化的语义正确性检查,主要依赖字符串匹配等简单方法;二是忽略了API序列调用之间复杂的交互关系,而这在实际应用中非常普遍。因此,需要一种能够自动生成多样化、可执行且具有复杂API交互的测试用例的方法,以更全面地评估LLM的工具使用能力。
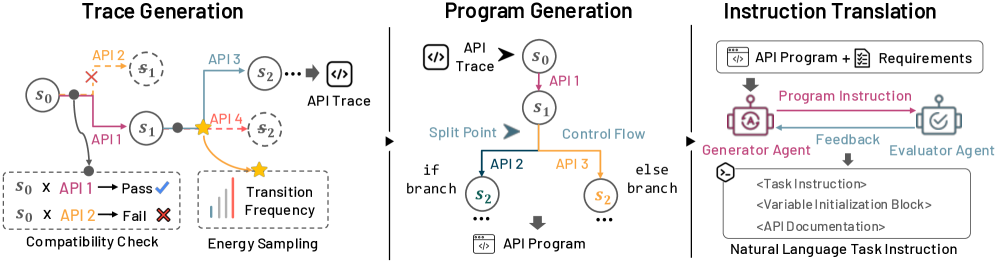
核心思路:StateGen的核心思路是利用状态机来建模API的使用约束,并结合能量模型进行采样,生成满足约束条件的可执行程序。然后,通过控制流注入增加程序的复杂性,最后利用LLM将程序翻译成自然语言描述的任务。这种方法能够自动生成多样化的、具有复杂API交互的测试用例,并且可以通过执行程序来验证语义正确性。
技术框架:StateGen框架主要包含以下几个模块: 1. API状态机建模:使用状态机来描述API的使用约束,例如API的调用顺序、参数类型等。 2. 约束求解和验证:利用约束求解器生成满足状态机约束的API调用序列,并进行验证。 3. 能量采样:使用能量模型对API调用序列进行采样,以增加多样性。 4. 控制流注入:向生成的程序中注入控制流,例如循环、条件分支等,以增加程序的复杂性。 5. 自然语言翻译:使用LLM将生成的程序翻译成自然语言描述的任务。
关键创新:StateGen的关键创新在于: 1. 自动化测试用例生成:能够自动生成多样化的、具有复杂API交互的测试用例,无需人工干预。 2. 基于状态机的约束建模:使用状态机来建模API的使用约束,能够有效地保证生成的测试用例的正确性。 3. 能量采样和控制流注入:通过能量采样和控制流注入,能够增加生成的测试用例的多样性和复杂性。
关键设计:StateGen的关键设计包括: 1. 状态机的设计:状态机的状态和转移需要仔细设计,以准确地描述API的使用约束。 2. 能量模型的设计:能量模型需要能够有效地对API调用序列进行采样,以增加多样性。 3. 控制流注入策略:控制流注入策略需要能够有效地增加程序的复杂性,同时保证程序的可执行性。 4. LLM prompt设计:需要设计合适的prompt,以指导LLM将程序翻译成自然语言描述的任务。
🖼️ 关键图片
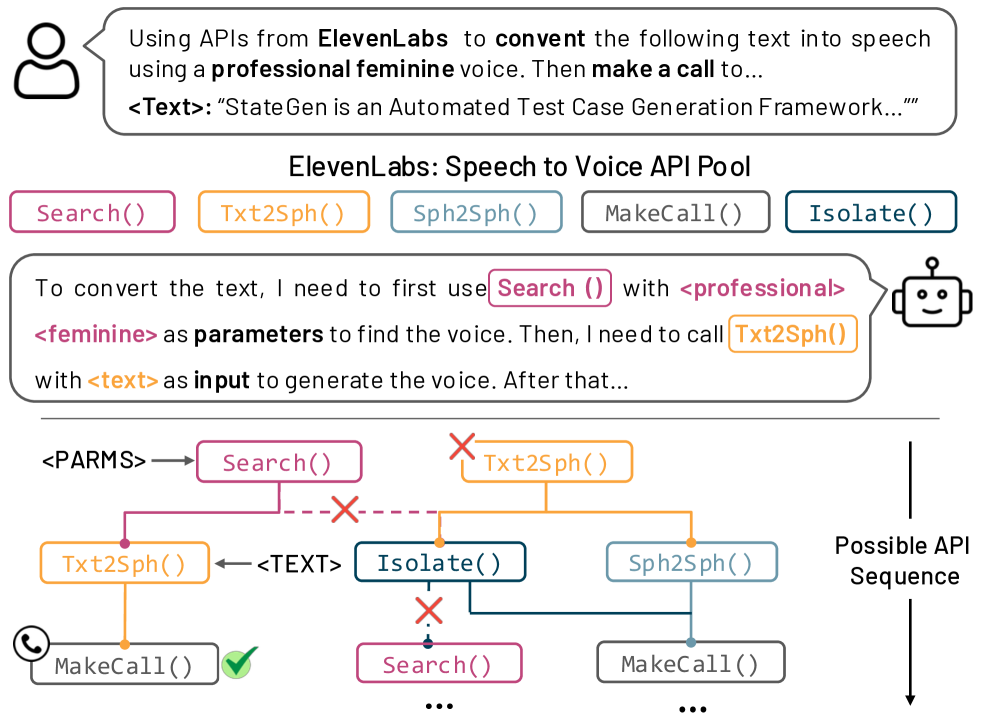
📊 实验亮点
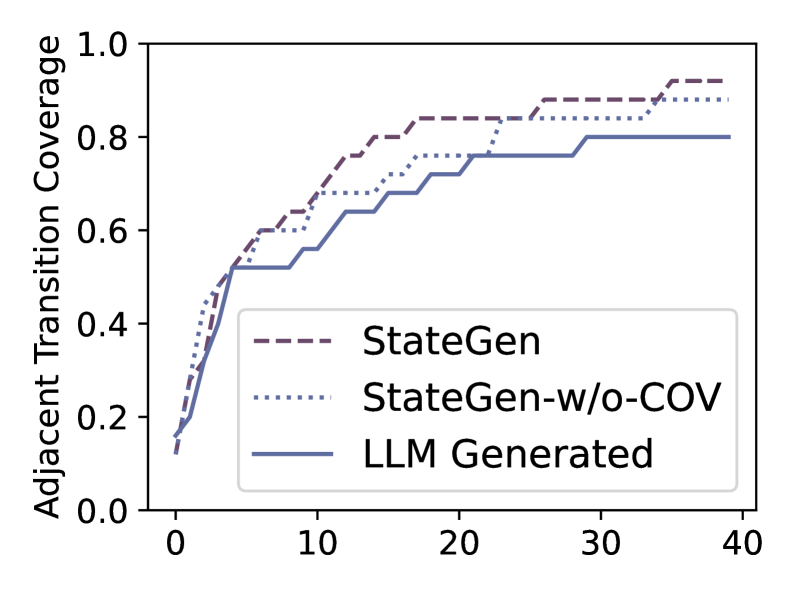
实验结果表明,StateGen能够有效地生成具有挑战性和现实的面向API的任务。StateEval基准测试包含120个用例,涵盖了会话服务、张量运算和ElevenLabs MCP等三个代表性场景。实验结果突出了当前集成API的LLM在处理复杂API序列调用时存在的不足,为未来的研究指明了方向。
🎯 应用场景
StateGen框架可用于自动化测试和评估LLM的工具使用能力,尤其是在需要复杂API交互的场景下,例如智能助手、自动化运维、科学计算等。通过StateGen生成的测试用例,可以帮助开发者发现LLM在工具使用方面的缺陷,并进行改进,从而提高LLM的可靠性和安全性。该研究为LLM工具使用的评测提供了一种新的思路和方法,具有重要的实际价值和未来影响。
📄 摘要(原文)
By integrating tools from external APIs, Large Language Models (LLMs) have expanded their promising capabilities in a diverse spectrum of complex real-world tasks. However, testing, evaluation, and analysis of LLM tool use remain in their early stages. Most existing benchmarks rely on manually collected test cases, many of which cannot be automatically checked for semantic correctness and instead depend on static methods such as string matching. Additionally, these benchmarks often overlook the complex interactions that occur between sequential API calls, which are common in real-world applications. To fill the gap, in this paper, we introduce StateGen, an automated framework designed to generate diverse coding tasks involving sequential API interactions. StateGen combines state-machine-based API constraint solving and validation, energy-based sampling, and control-flow injection to generate executable programs. These programs are then translated into human-like natural language task descriptions through a collaboration of two LLM agents. Utilizing StateGen, we construct StateEval, a benchmark encompassing 120 verified test cases spanning across three representative scenarios: Session Service, Tensor Operation, and ElevenLabs MCP. Experimental results confirm that StateGen can effectively generate challenging and realistic API-oriented tasks, highlighting areas for improvement in current LLMs incorporating APIs.We make our framework and benchmark publicly available to support future research.