SPICE: An Automated SWE-Bench Labeling Pipeline for Issue Clarity, Test Coverage, and Effort Estimation
作者: Gustavo A. Oliva, Gopi Krishnan Rajbahadur, Aaditya Bhatia, Haoxiang Zhang, Yihao Chen, Zhilong Chen, Arthur Leung, Dayi Lin, Boyuan Chen, Ahmed E. Hassan
分类: cs.SE, cs.AI
发布日期: 2025-07-12 (更新: 2025-09-18)
备注: *First three authors contributed equally
💡 一句话要点
SPICE:自动化SWE-bench标注流水线,提升问题清晰度、测试覆盖率和工作量评估。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 自动化标注 软件工程 数据集构建 SWE-bench 代码导航 大型语言模型 多轮共识
📋 核心要点
- 软件工程领域基础模型训练依赖高质量标注数据,但人工标注成本高昂,阻碍了大规模数据集的构建。
- SPICE通过结合上下文代码导航、理由驱动提示和多轮共识,自动化生成高质量的SWE-bench风格标注。
- SPICE显著降低了标注成本(从10万美元降至5.1美元/千例),并发布了包含6802个实例的SPICE Bench数据集。
📝 摘要(中文)
高质量的标注数据集对于训练和评估软件工程领域的基础模型至关重要,但创建这些数据集的成本通常高昂且耗费大量人力。我们介绍了SPICE,一个可扩展的自动化流水线,用于标注SWE-bench风格的数据集,并提供问题清晰度、测试覆盖率和工作量评估的注释。SPICE结合了上下文感知的代码导航、基于理由的提示和多轮共识,以生成与专家注释非常接近的标签。SPICE的设计受到了我们在标注SWE-Gym中超过800个实例的经验和挫败感的启发。SPICE在与人工标注的SWE-bench Verified数据达成高度一致的同时,将标注1000个实例的成本从大约10万美元(人工标注)降低到仅5.10美元。这些结果表明,SPICE有潜力实现经济高效的大规模数据集创建,以支持专注于软件工程的基础模型。为了支持社区,我们发布了SPICE工具和SPICE Bench,这是一个新的数据集,包含从SWE-Gym中291个开源项目整理的6,802个SPICE标注实例(比SWE-bench Verified大13倍以上)。
🔬 方法详解
问题定义:论文旨在解决软件工程领域数据集标注成本高昂且耗时的问题。现有的人工标注方法难以满足训练和评估大规模软件工程基础模型的需求,限制了该领域的发展。SWE-bench等数据集的构建需要大量专家参与,成本极高,阻碍了相关研究的进展。
核心思路:SPICE的核心思路是利用自动化流水线来模拟人工标注过程,通过结合上下文感知的代码导航、基于理由的提示和多轮共识,生成高质量的标注。这种方法旨在降低标注成本,提高标注效率,并保证标注质量,从而促进软件工程领域基础模型的发展。
技术框架:SPICE的整体架构是一个自动化流水线,包含以下主要模块:1) 上下文感知的代码导航:自动定位与问题相关的代码片段。2) 理由驱动的提示:利用大型语言模型生成标注理由。3) 多轮共识:通过多轮迭代和投票机制,提高标注的准确性和一致性。整个流程旨在模拟人工标注的思考过程,并利用自动化技术提高效率。
关键创新:SPICE最重要的技术创新点在于其自动化标注流水线的设计,该流水线能够以极低的成本生成高质量的SWE-bench风格标注。与传统的人工标注方法相比,SPICE显著降低了标注成本,并提高了标注效率。此外,SPICE还引入了理由驱动的提示和多轮共识机制,进一步提高了标注的准确性和一致性。
关键设计:SPICE的关键设计包括:1) 上下文感知的代码导航算法,用于准确地定位与问题相关的代码片段。2) 基于大型语言模型的提示策略,用于生成清晰、合理的标注理由。3) 多轮共识机制的具体实现,包括投票策略、迭代次数等。这些设计细节直接影响着SPICE的标注质量和效率,是SPICE成功的关键。
🖼️ 关键图片
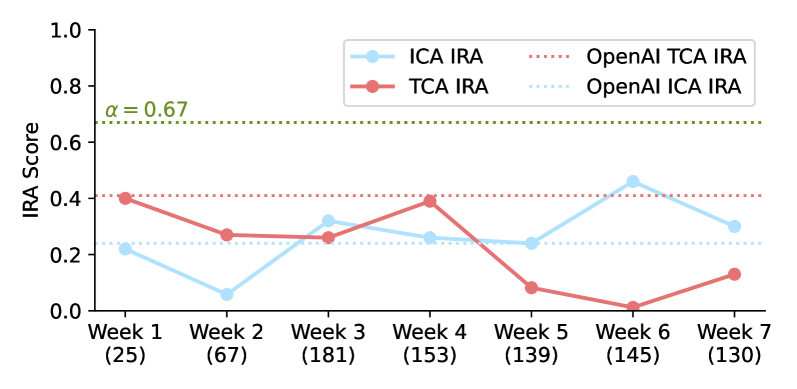
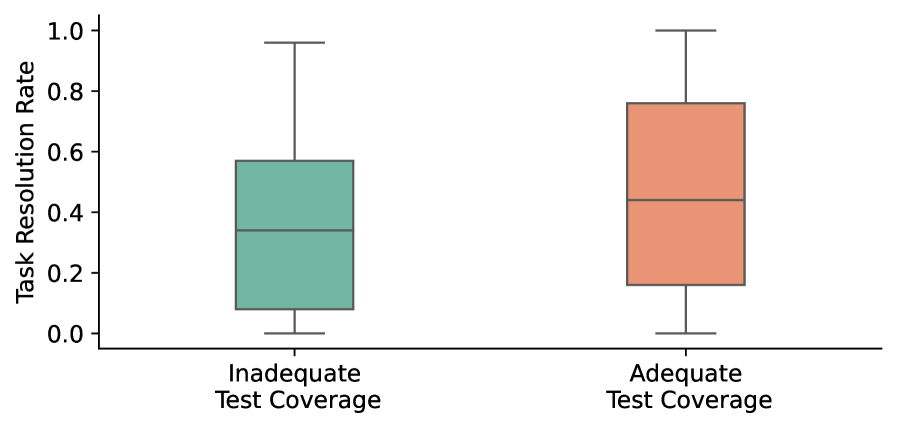

📊 实验亮点
SPICE在SWE-bench风格数据集的标注上,实现了与人工标注高度一致的结果,同时将标注成本从10万美元/千例大幅降低至5.1美元/千例。SPICE还构建了一个包含6802个实例的SPICE Bench数据集,比SWE-bench Verified数据集大13倍以上,为软件工程领域的研究提供了有力支持。
🎯 应用场景
SPICE可应用于大规模软件工程数据集的自动标注,加速软件缺陷检测、代码修复、测试生成等任务的基础模型训练。该技术能够降低数据集构建成本,促进软件工程领域的自动化和智能化,并为软件开发人员提供更智能的辅助工具。
📄 摘要(原文)
High-quality labeled datasets are crucial for training and evaluating foundation models in software engineering, but creating them is often prohibitively expensive and labor-intensive. We introduce SPICE, a scalable, automated pipeline for labeling SWE-bench-style datasets with annotations for issue clarity, test coverage, and effort estimation. SPICE combines context-aware code navigation, rationale-driven prompting, and multi-pass consensus to produce labels that closely approximate expert annotations. SPICE's design was informed by our own experience and frustration in labeling more than 800 instances from SWE-Gym. SPICE achieves strong agreement with human-labeled SWE-bench Verified data while reducing the cost of labeling 1,000 instances from around \$100,000 (manual annotation) to just \$5.10. These results demonstrate SPICE's potential to enable cost-effective, large-scale dataset creation for SE-focused FMs. To support the community, we release both SPICE tool and SPICE Bench, a new dataset of 6,802 SPICE-labeled instances curated from 291 open-source projects in SWE-Gym (over 13x larger than SWE-bench Verified).