Can Large Language Models Understand As Well As Apply Patent Regulations to Pass a Hands-On Patent Attorney Test?
作者: Bhakti Khera, Rezvan Alamian, Pascal A. Scherz, Stephan M. Goetz
分类: cs.CY, cs.AI, cs.CL, cs.ET
发布日期: 2025-07-11 (更新: 2025-09-11)
备注: 41 pages, 21 figures
💡 一句话要点
评估大型语言模型在专利律师考试中的表现,揭示其理解与应用专利法规的局限性
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 专利律师考试 法律领域应用 性能评估 专家评估
📋 核心要点
- 现有大型语言模型在法律领域的应用缺乏对其性能的定量评估和原因分析。
- 通过在欧洲专利律师资格考试(EQE)部分试题上评估多个LLM,考察其理解和应用专利法规的能力。
- 实验结果表明,现有LLM难以达到专业律师水平,且对提示词敏感,专家监督仍然至关重要。
📝 摘要(中文)
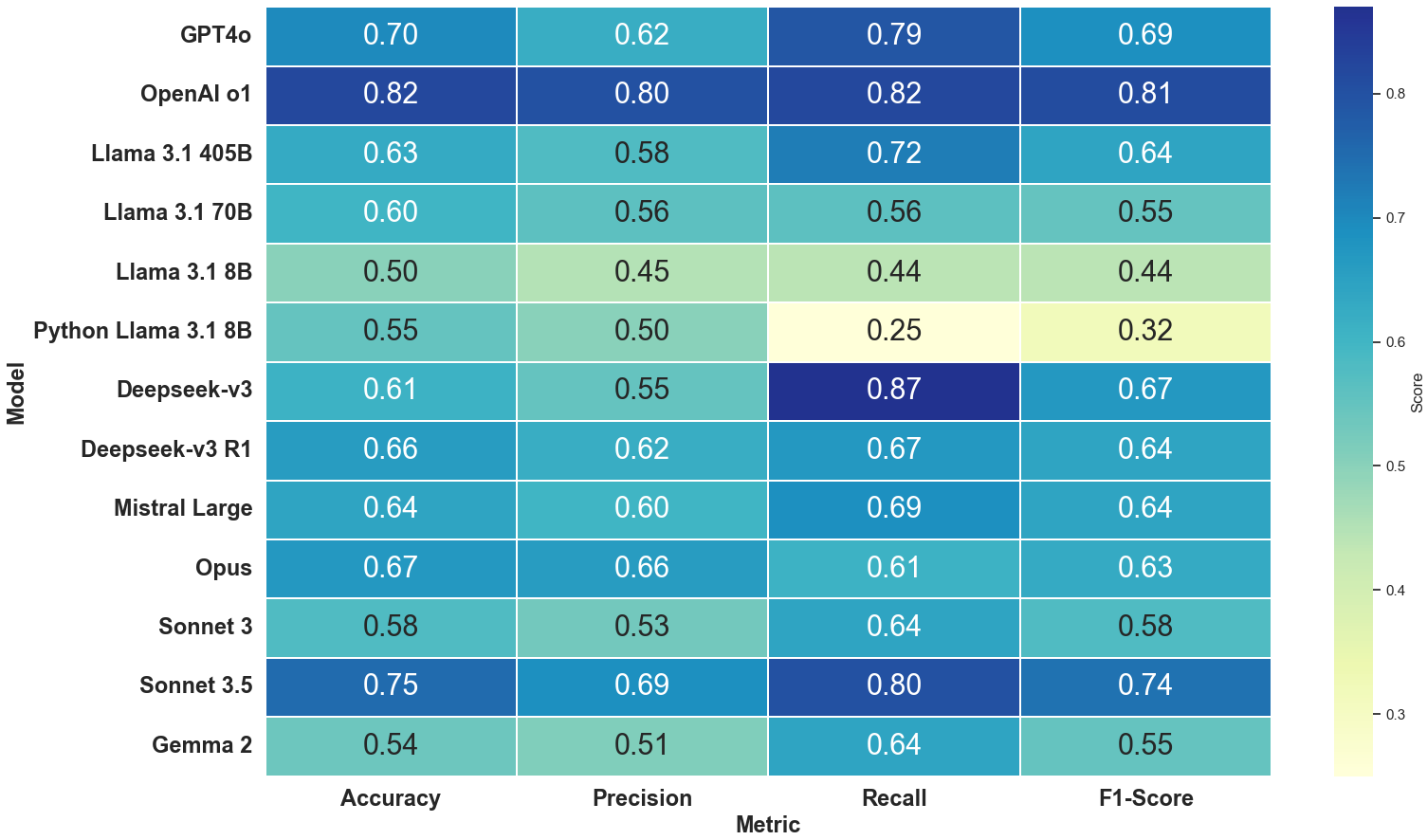
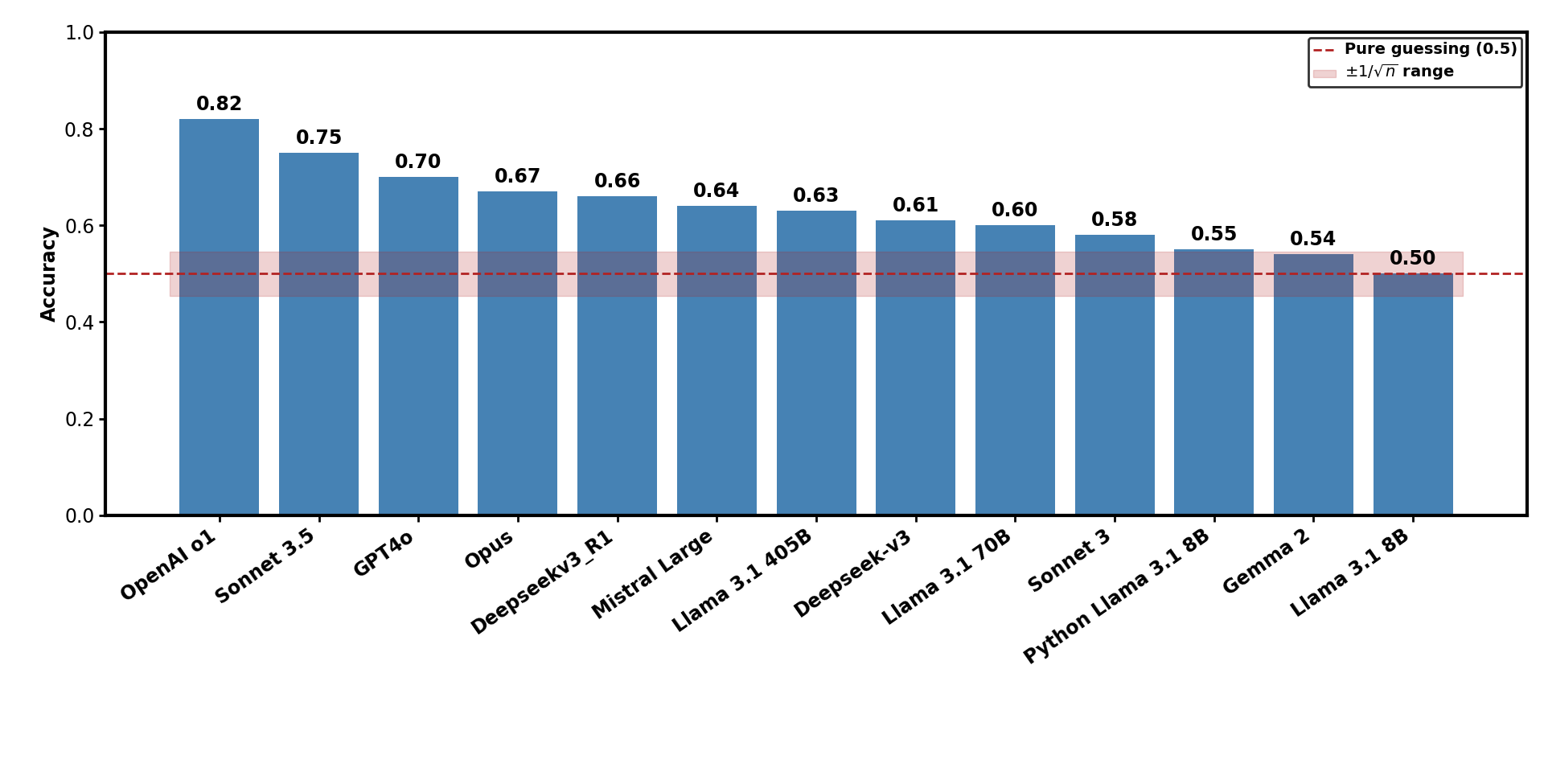
法律领域已在实际应用中使用各种大型语言模型(LLM),但对其定量性能及其原因的研究不足。本文评估了多个开源和专有LLM,包括GPT系列、Anthropic、Deepseek和Llama-3等变体,在欧洲专利律师资格考试(EQE)的部分试题上的表现。OpenAI的GPT-4o以0.82的准确率和0.81的F1分数领先,而AWS Llama 3.1 8B则以0.50的准确率落后,Python部署的Llama 3.1 8B得分为0.55。后两者在双项选择题的设计中仅略高于随机猜测。没有一个被评估的模型能够完全通过考试,因为准确率从未超过专业水平所需的0.90的平均阈值,即使是那些经常被宣传为具有超越博士和律师水平的模型。GPT-4o在整合文本和图形方面表现出色,而Claude 3 Opus经常失去格式一致性。人类专利专家评估了文本论证,并发现了每个模型的各种关键缺陷。他们重视清晰度和法律依据,而非答案的原始正确性,这揭示了自动指标与专家判断之间的不一致。模型输出对温度和提示词的细微变化敏感,这突显了专家监督的必要性。未来的工作应针对逻辑一致性、强大的多模态和自适应提示,以接近人类水平的专利能力。总而言之,尽管最近的大型模型表现出色,但公众可能高估了它们的性能。开发虚拟专利律师还有很长的路要走。本文旨在指出需要解决的几个具体限制。
🔬 方法详解
问题定义:论文旨在评估大型语言模型(LLM)在理解和应用专利法规方面的能力,具体通过模拟欧洲专利律师资格考试(EQE)的部分试题来进行评估。现有方法缺乏对LLM在法律领域定量性能的深入分析,并且对LLM的局限性认识不足,导致公众可能高估其能力。
核心思路:核心思路是将LLM应用于实际的专利律师考试场景,通过客观的考试成绩来评估其性能。同时,引入人类专利专家对LLM的答案进行评估,从专业角度分析LLM的优势和不足,从而更全面地了解LLM在法律领域的应用潜力。
技术框架:整体框架包括以下几个主要步骤:1) 选择合适的LLM模型,包括开源和商业模型;2) 准备EQE考试题目,并将其转化为LLM可以处理的格式;3) 使用不同的LLM模型回答考试题目;4) 使用自动指标(如准确率、F1分数)评估LLM的性能;5) 邀请人类专利专家对LLM的答案进行评估,并分析其优缺点;6) 分析实验结果,总结LLM在专利领域的应用潜力和局限性。
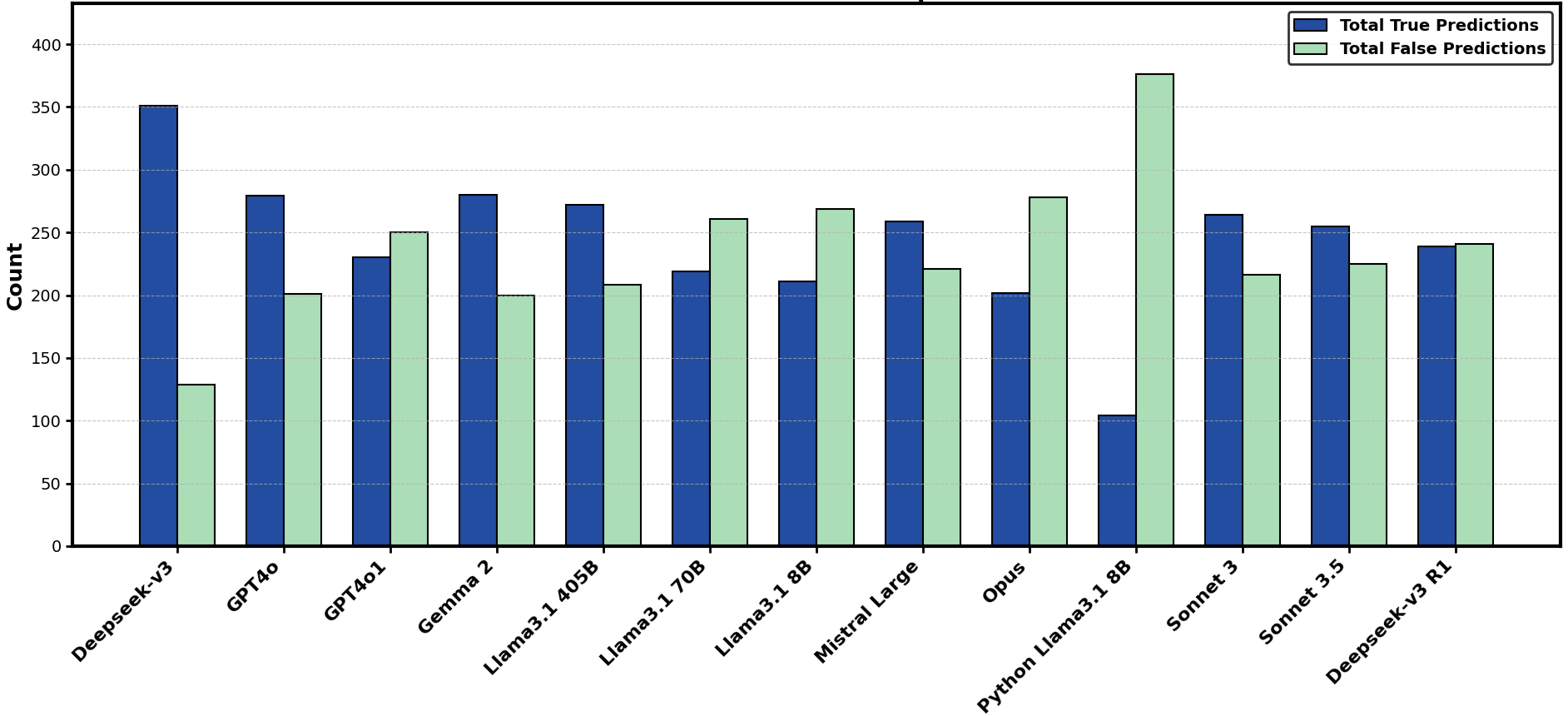
关键创新:关键创新在于将LLM应用于实际的专利律师考试场景,并结合自动指标和专家评估,从而更全面地评估LLM在法律领域的应用潜力。此外,论文还深入分析了LLM在处理文本和图形、保持格式一致性、理解法律逻辑等方面的能力,并指出了现有LLM的局限性。
关键设计:论文的关键设计包括:1) 选择具有代表性的LLM模型,包括GPT系列、Anthropic、Deepseek和Llama-3等;2) 使用EQE考试题目作为评估标准,确保评估的客观性和专业性;3) 引入人类专利专家进行评估,弥补自动指标的不足;4) 分析LLM对温度和提示词的敏感性,从而了解其鲁棒性;5) 深入分析LLM在处理文本和图形、保持格式一致性、理解法律逻辑等方面的能力。
🖼️ 关键图片
📊 实验亮点
GPT-4o在整合文本和图形方面表现出色,准确率达到0.82,F1分数达到0.81。然而,所有被评估的模型都未能达到专业律师水平所需的0.90的平均阈值。人类专家评估发现,模型在清晰度、法律依据等方面存在不足,且模型输出对温度和提示词的细微变化敏感。
🎯 应用场景
该研究成果可应用于评估和改进LLM在法律领域的应用,例如辅助专利检索、撰写专利申请文件、提供法律咨询等。通过了解LLM的优势和局限性,可以更好地利用LLM提高法律工作的效率和质量,并为开发虚拟专利律师提供指导。
📄 摘要(原文)
The legal field already uses various large language models (LLMs) in actual applications, but their quantitative performance and reasons for it are underexplored. We evaluated several open-source and proprietary LLMs -- including GPT-series, Anthropic, Deepseek and Llama-3, variants -- on parts of the European Qualifying Examination (EQE) for future European Patent Attorneys. OpenAI o1 led with 0.82 accuracy and 0.81 F1 score, whereas (Amazon Web Services) AWS Llama 3.1 8B lagged at 0.50 accuracy, and a Python-deployed Llama 3.1 8B scored 0.55. The latter two are within the range of mere guessing for the two-answer forced-choice design. None of the evaluated models could have passed the examination fully, as accuracy never exceeded the average threshold of 0.90 required for professional-level standards -- also not models that are regularly promoted for their assumed beyond-PhD- and bar-admitted-lawyer-level performance. GPT-4o excelled at integrating text and graphics, while Claude 3 Opus often lost formatting coherence. Human patent experts evaluated the textual justifications and uncovered various critical shortcomings of each model. They valued clarity and legal rationale over the raw correctness of the answers, which revealed misalignment between automatic metrics and expert judgment. Model outputs were sensitive to modest temperature changes and prompt wording, which underscores the remaining necessity of expert oversight. Future work should target logical consistency, robust multimodality, and adaptive prompting to approach human-level patent proficiency. In summary, despite the outstanding performance of recent large models, the general public might overestimate their performance. The field has a long way to go to develop a virtual patent attorney. This paper wants to point out several specific limitations that need solutions.