Invariant-based Robust Weights Watermark for Large Language Models
作者: Qingxiao Guo, Xinjie Zhu, Yilong Ma, Hui Jin, Yunhao Wang, Weifeng Zhang, Xiaobing Guo
分类: cs.CR, cs.AI
发布日期: 2025-07-11
💡 一句话要点
提出一种基于不变性的鲁棒权重水印方案,用于保护大语言模型的知识产权。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 水印技术 知识产权保护 模型不变性 鲁棒性 边缘计算 共谋攻击
📋 核心要点
- 大语言模型在边缘设备上的广泛应用使得知识产权保护成为关键问题,现有的水印技术可能无法满足资源受限场景下的需求。
- 该论文提出了一种基于模型不变性的鲁棒水印方案,无需重新训练或微调模型,即可实现有效的知识产权保护。
- 实验结果表明,该方案在多种攻击手段下仍能保持较高的鲁棒性,适用于Llama3、Phi3、Gemma等主流大语言模型。
📝 摘要(中文)
随着大语言模型(LLMs)在数十亿资源受限的边缘设备上的日益普及,知识产权(IP)保护变得至关重要,水印技术因此备受关注。为了应对恶意用户潜在的IP盗窃威胁,本文提出了一种鲁棒的水印方案,该方案无需对Transformer模型进行重新训练或微调。该方案为每个用户生成唯一的密钥,并通过求解由模型不变性构建的线性约束来推导出稳定的水印值。此外,该技术利用噪声机制来隐藏多用户场景中的水印位置,以防御共谋攻击。本文在三个流行的模型(Llama3、Phi3、Gemma)上评估了该方法,实验结果证实了其在各种攻击方法(微调、剪枝、量化、置换、缩放、可逆矩阵和共谋攻击)下的强大鲁棒性。
🔬 方法详解
问题定义:论文旨在解决大语言模型在边缘设备上部署时,模型权重容易被恶意用户窃取,导致知识产权侵犯的问题。现有水印方法可能需要重新训练或微调模型,计算开销大,且鲁棒性不足,难以抵抗各种攻击手段。
核心思路:论文的核心思路是利用Transformer模型的内在不变性,构建与模型权重相关的线性约束,并基于这些约束生成稳定的水印值。通过为每个用户生成唯一的密钥,并将水印嵌入到模型权重中,实现知识产权的保护。该方法无需重新训练或微调模型,降低了计算成本,并提高了水印的鲁棒性。
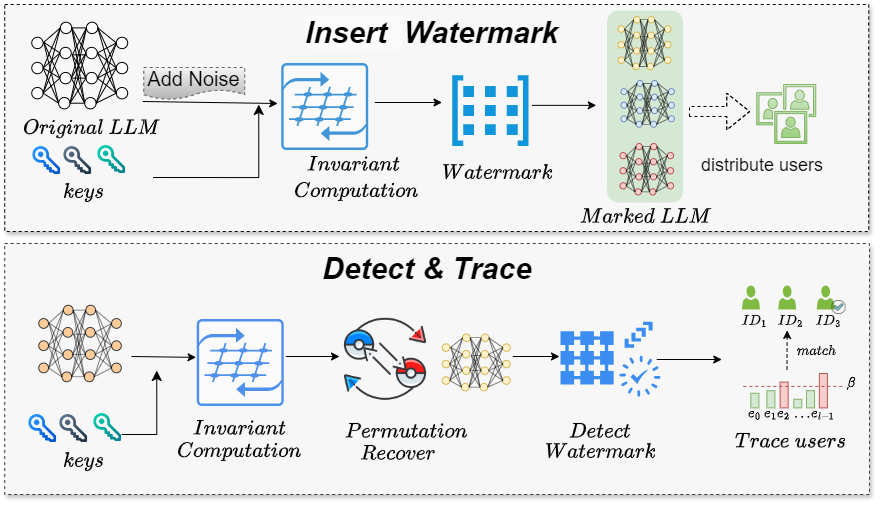
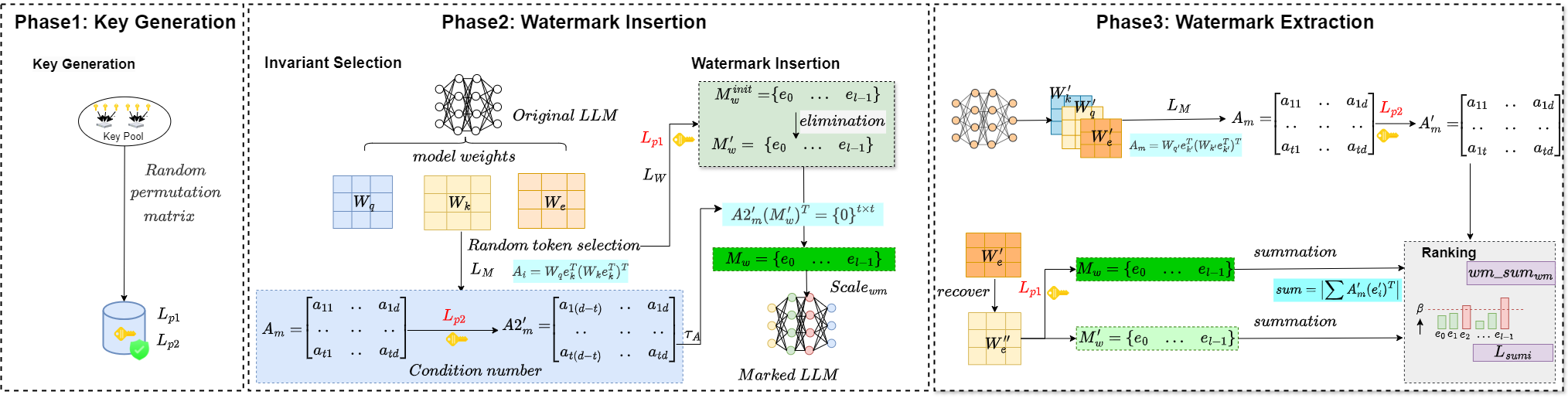
技术框架:该水印方案主要包含以下几个阶段:1) 用户密钥生成:为每个用户生成唯一的密钥。2) 不变性约束构建:利用Transformer模型的内在不变性,构建与模型权重相关的线性约束。3) 水印值计算:基于线性约束和用户密钥,计算稳定的水印值。4) 水印嵌入:将水印值嵌入到模型权重中,并使用噪声机制隐藏水印位置,以防御共谋攻击。5) 水印检测:通过分析模型权重,提取水印值,并验证用户身份。
关键创新:该论文的关键创新在于利用Transformer模型的内在不变性来构建水印。这种方法无需重新训练或微调模型,降低了计算成本,并提高了水印的鲁棒性。此外,该论文还提出了噪声机制来隐藏水印位置,以防御共谋攻击。
关键设计:论文的关键设计包括:1) 线性约束的构建方式,确保水印值的稳定性。2) 噪声机制的设计,平衡水印的隐蔽性和鲁棒性。3) 水印嵌入的位置选择,避免影响模型性能。4) 水印检测的阈值设置,降低误报率。
🖼️ 关键图片

📊 实验亮点
该论文在Llama3、Phi3和Gemma等主流大语言模型上进行了实验,结果表明该水印方案在各种攻击手段下均表现出强大的鲁棒性,包括微调、剪枝、量化、置换、缩放、可逆矩阵和共谋攻击。具体性能数据(如水印检测准确率、模型性能下降幅度)在论文中进行了详细展示,并与现有方法进行了对比,证明了该方案的优越性。
🎯 应用场景
该研究成果可广泛应用于大语言模型的知识产权保护,尤其是在资源受限的边缘设备上。它可以有效防止模型权重被恶意窃取和滥用,维护开发者的合法权益。此外,该技术还可以用于模型溯源,追踪模型的传播路径,为打击侵权行为提供技术支持。未来,该技术有望成为大语言模型安全部署的重要组成部分。
📄 摘要(原文)
Watermarking technology has gained significant attention due to the increasing importance of intellectual property (IP) rights, particularly with the growing deployment of large language models (LLMs) on billions resource-constrained edge devices. To counter the potential threats of IP theft by malicious users, this paper introduces a robust watermarking scheme without retraining or fine-tuning for transformer models. The scheme generates a unique key for each user and derives a stable watermark value by solving linear constraints constructed from model invariants. Moreover, this technology utilizes noise mechanism to hide watermark locations in multi-user scenarios against collusion attack. This paper evaluates the approach on three popular models (Llama3, Phi3, Gemma), and the experimental results confirm the strong robustness across a range of attack methods (fine-tuning, pruning, quantization, permutation, scaling, reversible matrix and collusion attacks).