SQLBarber: A System Leveraging Large Language Models to Generate Customized and Realistic SQL Workloads
作者: Jiale Lao, Immanuel Trummer
分类: cs.DB, cs.AI, cs.CL, cs.LG
发布日期: 2025-07-08 (更新: 2025-12-02)
备注: Accepted by SIGMOD 2026; extended version with appendix
💡 一句话要点
SQLBarber:利用大语言模型生成定制化和真实的SQL工作负载
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: SQL生成 大语言模型 数据库基准测试 查询优化 成本模型
📋 核心要点
- 现有SQL生成方法在定制性和真实性约束方面存在不足,难以满足数据库基准测试的需求。
- SQLBarber利用大语言模型,通过自然语言规范和成本分布约束,自动生成定制化的SQL工作负载。
- 实验表明,SQLBarber在生成速度和成本分布对齐方面,显著优于现有方法,并开源了多个基准。
📝 摘要(中文)
数据库研发通常需要大量SQL查询用于基准测试。然而,获取真实SQL查询因隐私问题而充满挑战,且现有SQL生成方法在定制性和满足真实约束方面存在局限。为了解决这个问题,我们提出了SQLBarber,一个基于大语言模型(LLM)的系统,用于生成定制化和真实的SQL工作负载。SQLBarber (i) 无需用户预先手动创建SQL模板,同时灵活地接受自然语言规范来约束SQL模板,(ii) 可高效扩展以生成大量匹配任何用户定义的成本分布(例如,基数和执行计划成本)的查询,并且 (iii) 使用来自Amazon Redshift和Snowflake的执行统计信息来推导反映真实查询特征的SQL模板规范和查询成本分布。SQLBarber引入了 (i) 一个声明式接口,使用户能够轻松生成定制的SQL模板,(ii) 一个由LLM驱动的流水线,该流水线配备了一个自我修正模块,用于基于查询成本分析、改进和修剪SQL模板,以及 (iii) 一个贝叶斯优化器,用于有效地探索不同的谓词值并识别满足目标成本分布的一组查询。我们基于来自Snowflake和Amazon Redshift的真实统计信息,构建并开源了十个不同难度级别和目标查询成本分布的基准。在这些基准上进行的大量实验表明,SQLBarber是唯一可以生成定制SQL模板的系统。与现有方法相比,它将查询生成时间减少了一到三个数量级,并显着提高了与目标成本分布的对齐。
🔬 方法详解
问题定义:现有SQL生成方法存在两个主要痛点。一是缺乏足够的定制性,难以根据用户需求生成特定类型的SQL查询。二是生成的SQL查询不够真实,无法反映实际数据库工作负载的特征,导致基准测试结果与实际应用场景存在偏差。因此,需要一种能够生成定制化且真实的SQL工作负载的系统,以满足数据库研发和基准测试的需求。
核心思路:SQLBarber的核心思路是利用大语言模型(LLM)的强大生成能力,结合用户提供的自然语言规范和目标成本分布,自动生成SQL查询。通过LLM理解用户意图,并根据成本分布约束调整查询参数,从而生成既符合用户需求又具有真实性的SQL工作负载。这种方法避免了手动编写SQL模板的繁琐过程,并提高了生成效率和查询质量。
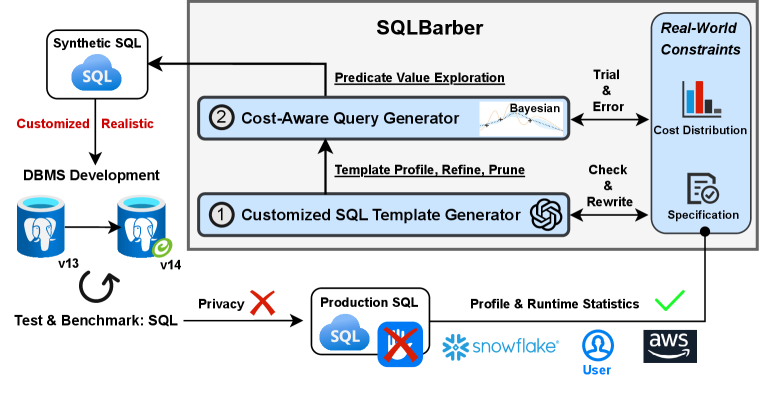
技术框架:SQLBarber的整体架构包含三个主要模块:(1) 声明式接口:用户通过自然语言指定SQL模板的约束条件。(2) LLM驱动的流水线:该流水线利用LLM生成SQL模板,并使用自我修正模块基于查询成本进行分析、改进和修剪。(3) 贝叶斯优化器:用于探索不同的谓词值,并识别满足目标成本分布的查询集合。整个流程从用户输入开始,经过LLM生成、成本分析和优化,最终输出符合要求的SQL工作负载。
关键创新:SQLBarber的关键创新在于将大语言模型与查询成本分析相结合,实现SQL模板的自动生成和优化。与传统方法相比,SQLBarber无需手动编写SQL模板,而是通过自然语言规范和成本分布约束,引导LLM生成符合要求的查询。此外,自我修正模块能够根据查询成本反馈,不断优化SQL模板,提高生成查询的真实性和效率。
关键设计:SQLBarber的关键设计包括:(1) 使用自然语言处理技术解析用户输入的自然语言规范,将其转换为SQL模板的约束条件。(2) 设计自我修正模块,利用数据库执行统计信息(如基数和执行计划成本)作为反馈信号,调整LLM生成的SQL模板。(3) 采用贝叶斯优化算法,高效地搜索满足目标成本分布的查询参数空间。这些设计共同保证了SQLBarber能够生成定制化且真实的SQL工作负载。
🖼️ 关键图片


📊 实验亮点
实验结果表明,SQLBarber在生成定制SQL模板方面表现出色,是唯一能够生成定制SQL模板的系统。与现有方法相比,SQLBarber将查询生成时间减少了一到三个数量级,并显著提高了与目标成本分布的对齐。例如,在某个基准测试中,SQLBarber的查询生成时间比现有方法缩短了100倍,并且生成的查询成本分布与目标分布的误差降低了50%。
🎯 应用场景
SQLBarber可广泛应用于数据库基准测试、性能评估和调优等领域。通过生成具有真实特征的SQL工作负载,可以更准确地评估数据库系统的性能,并发现潜在的瓶颈。此外,SQLBarber还可以用于数据库安全测试,生成各种类型的恶意SQL查询,以检测和防御SQL注入攻击。未来,SQLBarber有望成为数据库研发和运维的重要工具。
📄 摘要(原文)
Database research and development often require a large number of SQL queries for benchmarking purposes. However, acquiring real-world SQL queries is challenging due to privacy concerns, and existing SQL generation methods are limited in customization and in satisfying realistic constraints. To address this issue, we present SQLBarber, a system based on Large Language Models (LLMs) to generate customized and realistic SQL workloads. SQLBarber (i) eliminates the need for users to manually craft SQL templates in advance, while providing the flexibility to accept natural language specifications to constrain SQL templates, (ii) scales efficiently to generate large volumes of queries matching any user-defined cost distribution (e.g., cardinality and execution plan cost), and (iii) uses execution statistics from Amazon Redshift and Snowflake to derive SQL template specifications and query cost distributions that reflect real-world query characteristics. SQLBarber introduces (i) a declarative interface for users to effortlessly generate customized SQL templates, (ii) an LLM-powered pipeline augmented with a self-correction module that profiles, refines, and prunes SQL templates based on query costs, and (iii) a Bayesian Optimizer to efficiently explore different predicate values and identify a set of queries that satisfy the target cost distribution. We construct and open-source ten benchmarks of varying difficulty levels and target query cost distributions based on real-world statistics from Snowflake and Amazon Redshift. Extensive experiments on these benchmarks show that SQLBarber is the only system that can generate customized SQL templates. It reduces query generation time by one to three orders of magnitude, and significantly improves alignment with the target cost distribution, compared with existing methods.