Architecting Clinical Collaboration: Multi-Agent Reasoning Systems for Multimodal Medical VQA
作者: Karishma Thakrar, Shreyas Basavatia, Akshay Daftardar
分类: cs.AI
发布日期: 2025-07-07 (更新: 2025-08-26)
💡 一句话要点
构建临床协作:用于多模态医学VQA的多智能体推理系统
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 医学视觉问答 多模态学习 临床协作 多智能体系统 检索增强生成
📋 核心要点
- 现有医学AI系统在远程医疗场景中,难以模拟临床医生进行诊断时的全面信息获取和协作过程。
- 论文提出模仿临床推理过程,构建多智能体推理系统,结合同行咨询和文献检索,增强模型推理能力。
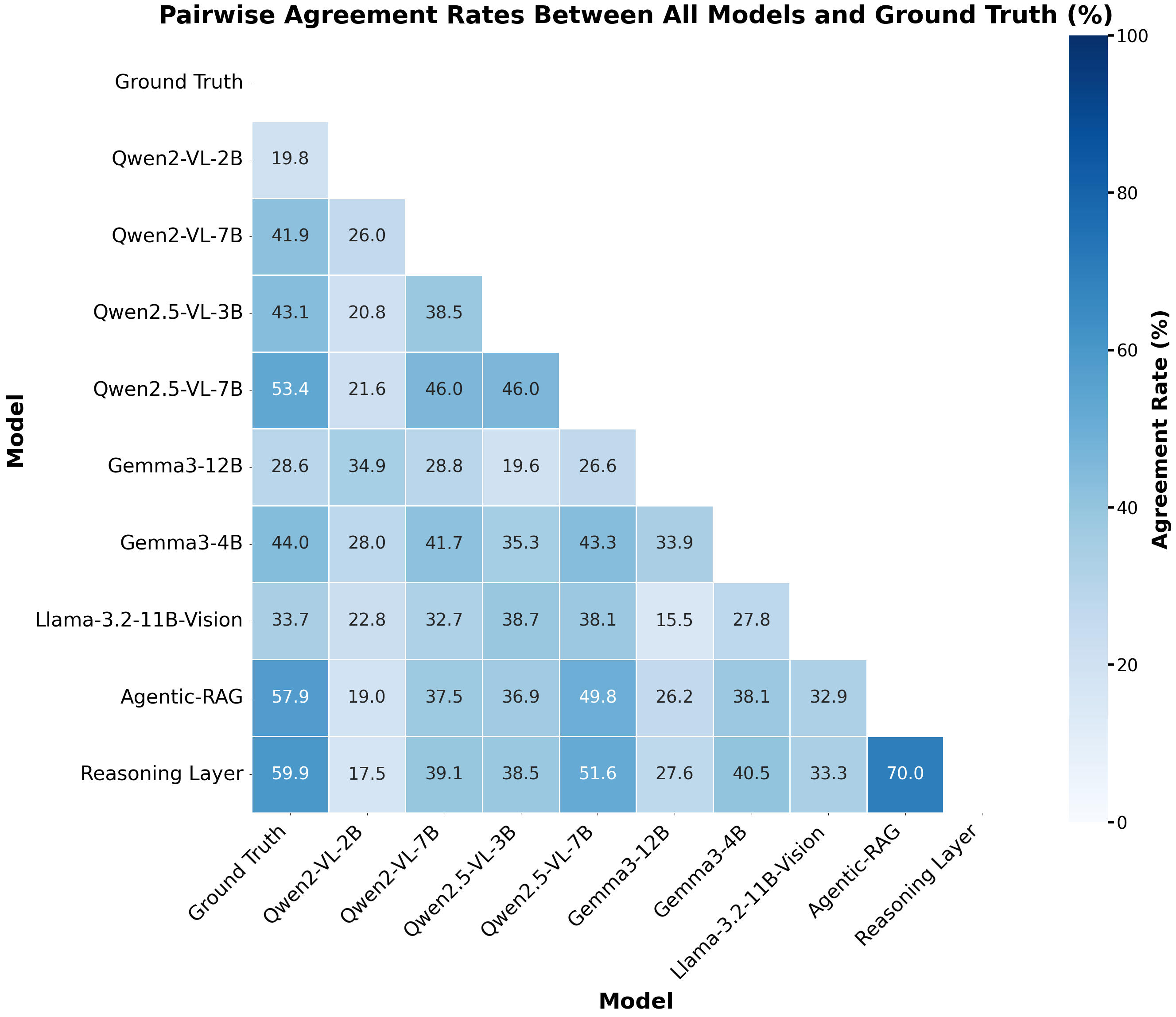
- 实验表明,临床启发式架构显著提升了医学视觉问答的准确率,并生成了可解释的、基于文献的输出。
📝 摘要(中文)
远程皮肤科护理通常缺乏面对面就诊的丰富背景信息。临床医生必须仅凭少量图像和简短描述做出诊断,无法进行体格检查、获得第二意见或查阅参考资料。虽然许多医学AI系统试图通过特定领域的微调来弥补这些差距,但本研究假设,模仿临床推理过程可能提供更有效的方法。本研究在六种配置下测试了七种视觉-语言模型在医学视觉问答方面的性能:基线模型、微调变体,以及两者都增强了推理层(结合多个模型视角,类似于同行咨询)或检索增强生成(在推理时纳入医学文献,起到类似参考检查的作用)。结果表明,微调降低了七个模型中四个的性能,平均下降30%,而基线模型在测试数据上表现崩溃。临床启发式架构则实现了高达70%的准确率,在未见数据上保持了性能,同时生成了可解释的、基于文献的输出,这对于临床应用至关重要。这些发现表明,医学AI通过重建临床诊断的基本协作和循证实践而获得成功。
🔬 方法详解
问题定义:论文旨在解决远程医疗中,临床医生仅凭有限的图像和描述进行皮肤科诊断时,信息不足和缺乏协作的问题。现有医学AI系统通常采用领域特定微调,但忽略了临床推理过程中的协作和证据检索,导致泛化能力差和可解释性不足。
核心思路:论文的核心思路是模仿临床医生的诊断过程,构建一个多智能体推理系统,该系统能够模拟同行咨询(通过组合多个模型的视角)和文献检索(通过检索增强生成)。通过这种方式,模型可以获得更全面的信息,并生成更可信和可解释的诊断结果。
技术框架:整体架构包括以下几个主要模块:1) 基线视觉-语言模型:作为基础的诊断智能体。2) 微调模块:对基线模型进行领域特定微调。3) 推理层:组合多个模型的预测结果,模拟同行咨询。4) 检索增强生成模块:在推理时检索相关医学文献,并将其融入答案生成过程。整个流程是,首先使用基线模型或微调模型对图像和问题进行编码,然后通过推理层整合多个模型的视角,最后使用检索增强生成模块生成基于文献的答案。
关键创新:论文的关键创新在于将临床协作的理念融入到医学视觉问答系统中。具体体现在两个方面:一是通过推理层模拟同行咨询,利用多个模型的互补优势;二是通过检索增强生成模拟文献检索,为诊断提供证据支持。这种方法不同于传统的领域特定微调,它更注重模拟临床推理过程,从而提高了模型的泛化能力和可解释性。
关键设计:论文中,推理层可以通过简单的平均或更复杂的注意力机制来组合多个模型的预测结果。检索增强生成模块可以使用现有的检索模型(如BM25或基于Transformer的检索模型)来检索相关医学文献。损失函数方面,可以使用交叉熵损失或对比学习损失来训练模型。具体的网络结构和参数设置取决于所使用的基线模型和检索模型。
🖼️ 关键图片


📊 实验亮点
实验结果表明,临床启发式架构在医学视觉问答任务上取得了显著的性能提升,最高准确率达到70%。与基线模型相比,该架构在未见数据上保持了良好的泛化能力。更重要的是,该架构能够生成可解释的、基于文献的输出,这对于临床应用至关重要。微调在部分模型上反而降低了性能,平均下降30%,突显了模拟临床推理过程的重要性。
🎯 应用场景
该研究成果可应用于远程医疗、辅助诊断、医学教育等领域。通过构建临床协作的AI系统,可以帮助临床医生更准确、高效地进行诊断,尤其是在资源有限或缺乏专家支持的地区。此外,该系统还可以作为医学教育工具,帮助学生学习临床推理和循证医学。
📄 摘要(原文)
Dermatological care via telemedicine often lacks the rich context of in-person visits. Clinicians must make diagnoses based on a handful of images and brief descriptions, without the benefit of physical exams, second opinions, or reference materials. While many medical AI systems attempt to bridge these gaps with domain-specific fine-tuning, this work hypothesized that mimicking clinical reasoning processes could offer a more effective path forward. This study tested seven vision-language models on medical visual question answering across six configurations: baseline models, fine-tuned variants, and both augmented with either reasoning layers that combine multiple model perspectives, analogous to peer consultation, or retrieval-augmented generation that incorporates medical literature at inference time, serving a role similar to reference-checking. While fine-tuning degraded performance in four of seven models with an average 30% decrease, baseline models collapsed on test data. Clinical-inspired architectures, meanwhile, achieved up to 70% accuracy, maintaining performance on unseen data while generating explainable, literature-grounded outputs critical for clinical adoption. These findings demonstrate that medical AI succeeds by reconstructing the collaborative and evidence-based practices fundamental to clinical diagnosis.