LEGO Co-builder: Exploring Fine-Grained Vision-Language Modeling for Multimodal LEGO Assembly Assistants
作者: Haochen Huang, Jiahuan Pei, Mohammad Aliannejadi, Xin Sun, Moonisa Ahsan, Chuang Yu, Zhaochun Ren, Pablo Cesar, Junxiao Wang
分类: cs.AI, cs.CL, cs.CV
发布日期: 2025-07-07 (更新: 2025-07-23)
备注: This version has been anonymized for double-blind review
💡 一句话要点
LEGO Co-builder:探索细粒度视觉语言建模,用于多模态乐高组装助手
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉语言模型 多模态学习 乐高组装 细粒度理解 基准数据集 指令跟随 对象状态检测
📋 核心要点
- 现有视觉语言模型在处理需要细粒度空间推理和精确对象状态检测的多模态组装指令时存在不足。
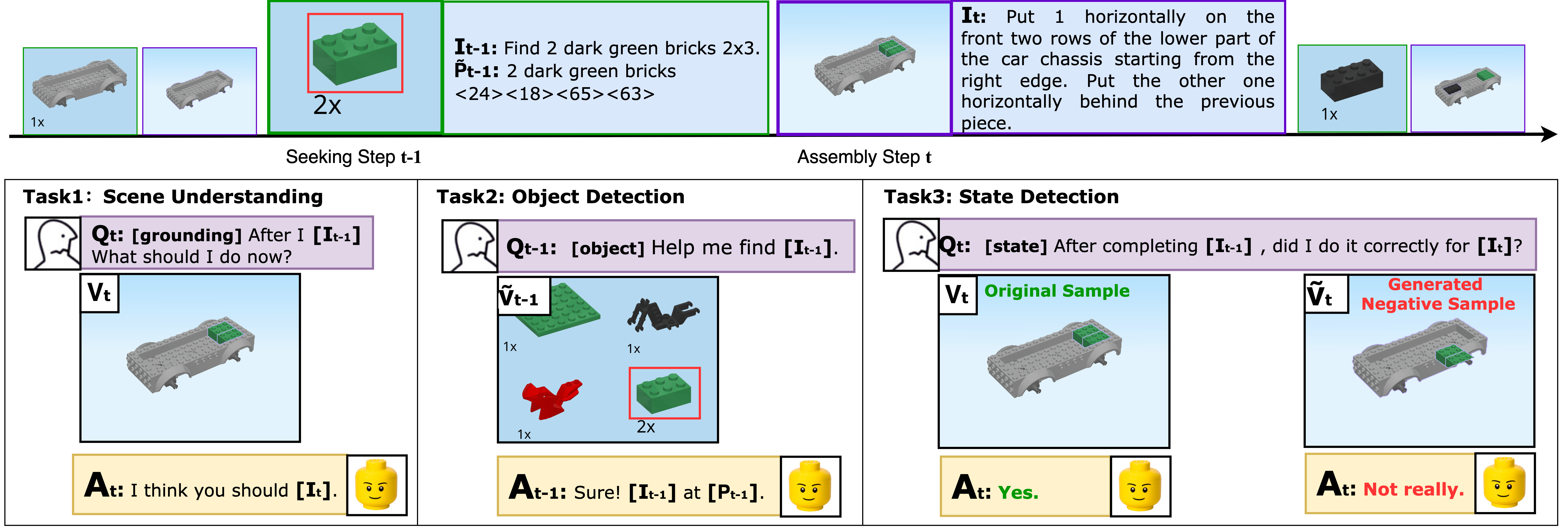
- 论文提出了LEGO Co-builder基准,结合真实乐高组装逻辑和程序化生成场景,用于评估模型在指令跟随、对象检测和状态检测方面的能力。
- 实验结果表明,即使是GPT-4o等先进模型在细粒度组装任务中也表现不佳,状态检测F1得分最高仅为40.54%。
📝 摘要(中文)
视觉语言模型(VLMs)在理解和遵循多模态组装指令方面面临挑战,尤其是在需要细粒度空间推理和精确对象状态检测时。本文探索了LEGO Co-builder,这是一个混合基准,结合了真实的乐高组装逻辑和程序化生成的多模态场景。该数据集捕获了逐步的视觉状态和程序指令,从而可以对指令跟随、对象检测和状态检测进行受控评估。我们引入了一个统一的框架,并在零样本和微调设置下评估了领先的VLM,如GPT-4o、Gemini和Qwen-VL。结果表明,即使是像GPT-4o这样的高级模型也在细粒度的组装任务中表现不佳,在状态检测方面的最高F1得分仅为40.54%,突出了细粒度视觉理解方面的差距。我们发布了基准、代码库和生成流程,以支持未来对基于真实世界工作流程的多模态组装助手的研究。
🔬 方法详解
问题定义:论文旨在解决视觉语言模型在理解和执行细粒度多模态组装指令时遇到的困难。现有方法在处理需要精确空间推理和对象状态检测的任务时表现不佳,无法满足实际组装场景的需求。乐高组装任务对模型的细粒度视觉理解和指令执行能力提出了更高的要求。
核心思路:论文的核心思路是构建一个可控、可扩展的基准数据集LEGO Co-builder,用于评估和提升视觉语言模型在细粒度组装任务中的性能。通过程序化生成多模态场景,可以精确控制数据集的复杂度和多样性,从而更好地评估模型的泛化能力。
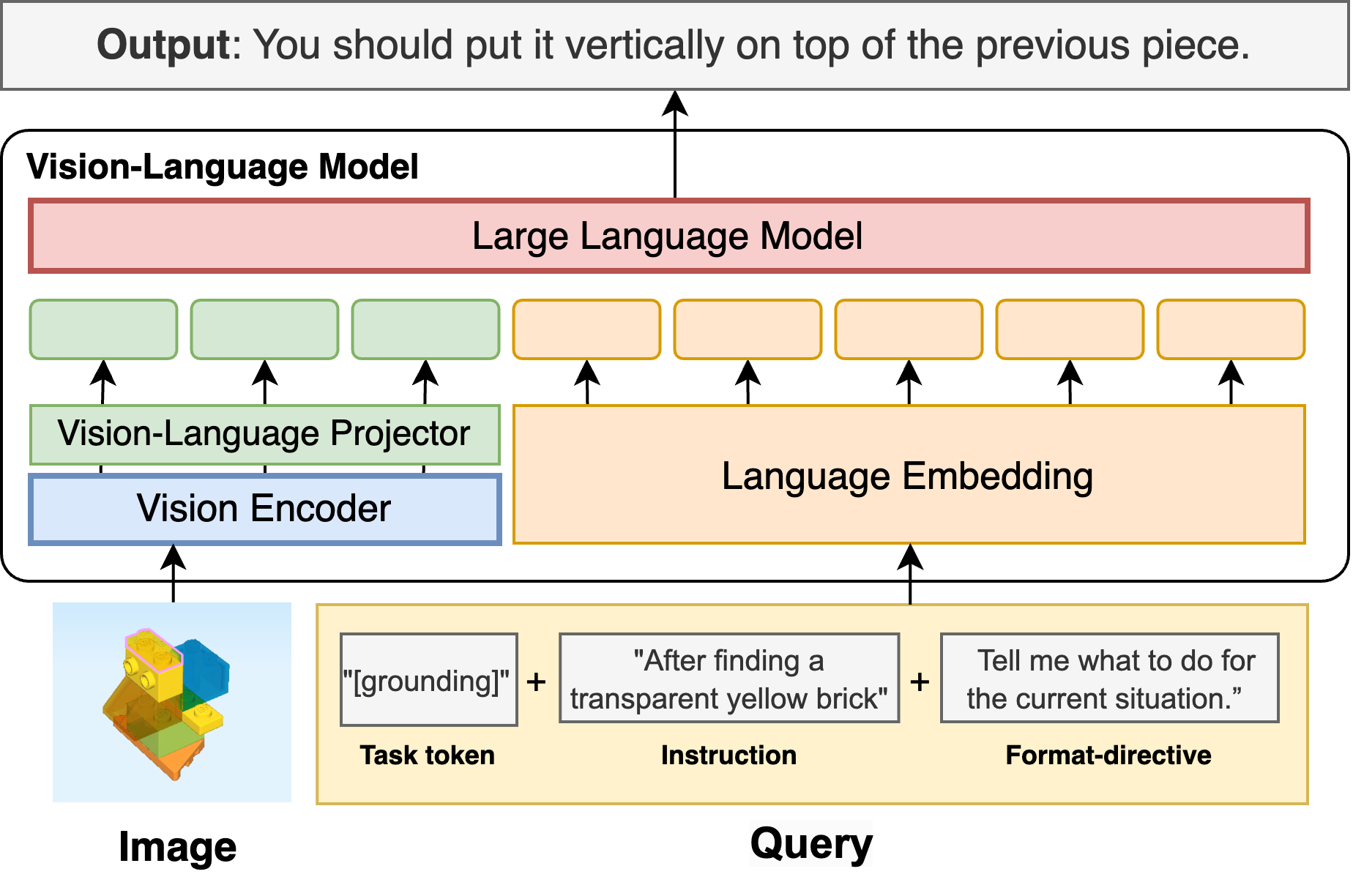
技术框架:论文提出了一个统一的评估框架,该框架包括数据集生成流程、模型评估指标和基线模型。数据集生成流程基于真实的乐高组装逻辑,并结合程序化生成技术,生成包含逐步视觉状态和程序指令的多模态场景。评估指标包括指令跟随准确率、对象检测精度和状态检测F1得分。基线模型包括GPT-4o、Gemini和Qwen-VL等。
关键创新:论文的关键创新在于提出了LEGO Co-builder基准数据集,该数据集具有以下特点:(1) 结合了真实的乐高组装逻辑和程序化生成技术;(2) 提供了细粒度的视觉状态和程序指令;(3) 支持对指令跟随、对象检测和状态检测进行受控评估。与现有数据集相比,LEGO Co-builder更具挑战性和可控性,能够更好地评估模型在细粒度组装任务中的性能。
关键设计:数据集的生成流程包括以下步骤:(1) 定义乐高组装步骤;(2) 程序化生成每个步骤对应的视觉场景;(3) 生成与每个步骤相关的文本指令。在模型评估方面,论文采用了零样本和微调两种设置。在零样本设置下,模型直接在LEGO Co-builder数据集上进行评估。在微调设置下,模型首先在LEGO Co-builder数据集上进行微调,然后再进行评估。
🖼️ 关键图片

📊 实验亮点
实验结果表明,即使是GPT-4o等先进模型在LEGO Co-builder数据集上也表现不佳,在状态检测方面的最高F1得分仅为40.54%。这表明现有视觉语言模型在细粒度视觉理解方面存在明显差距。通过对不同模型的性能进行对比分析,论文揭示了模型在处理不同类型组装任务时的优势和不足,为未来的研究提供了重要的参考。
🎯 应用场景
该研究成果可应用于开发智能组装助手,例如乐高组装机器人、家具组装指导系统等。这些助手可以帮助用户更高效、更准确地完成组装任务,降低出错率,提高用户体验。此外,该研究还可以促进视觉语言模型在其他需要细粒度空间推理和对象状态检测领域的应用,例如医疗诊断、工业检测等。
📄 摘要(原文)
Vision-language models (VLMs) are facing the challenges of understanding and following multimodal assembly instructions, particularly when fine-grained spatial reasoning and precise object state detection are required. In this work, we explore LEGO Co-builder, a hybrid benchmark combining real-world LEGO assembly logic with programmatically generated multimodal scenes. The dataset captures stepwise visual states and procedural instructions, allowing controlled evaluation of instruction-following, object detection, and state detection. We introduce a unified framework and assess leading VLMs such as GPT-4o, Gemini, and Qwen-VL, under zero-shot and fine-tuned settings. Our results reveal that even advanced models like GPT-4o struggle with fine-grained assembly tasks, with a maximum F1 score of just 40.54\% on state detection, highlighting gaps in fine-grained visual understanding. We release the benchmark, codebase, and generation pipeline to support future research on multimodal assembly assistants grounded in real-world workflows.