Deep Research Comparator: A Platform For Fine-grained Human Annotations of Deep Research Agents
作者: Prahaladh Chandrahasan, Jiahe Jin, Zhihan Zhang, Tevin Wang, Andy Tang, Lucy Mo, Morteza Ziyadi, Leonardo F. R. Ribeiro, Zimeng Qiu, Markus Dreyer, Akari Asai, Chenyan Xiong
分类: cs.AI
发布日期: 2025-07-07 (更新: 2025-12-23)
💡 一句话要点
提出Deep Research Comparator平台,用于深度研究Agent的细粒度人工标注与评估。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 深度研究Agent 人工标注 平台评估 用户偏好 并排比较
📋 核心要点
- 深度研究Agent的有效评估面临挑战,尤其是在评估长报告和提供中间步骤的详细反馈方面。
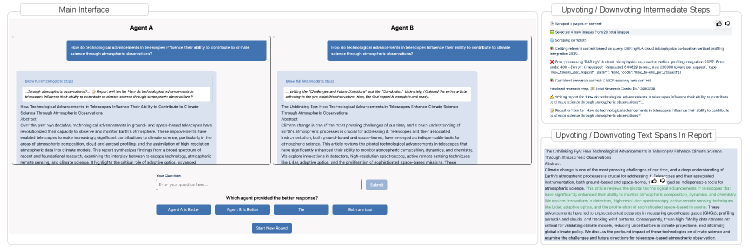
- Deep Research Comparator平台通过并排比较、细粒度反馈和排名计算,提供了一个全面的深度研究Agent评估框架。
- Simple Deepresearch框架简化了大型语言模型到深度研究Agent的转换,并收集了真实用户偏好数据验证平台实用性。
📝 摘要(中文)
本文介绍了一个名为Deep Research Comparator的平台,旨在为深度研究Agent提供一个全面的评估框架。该平台支持深度研究Agent的托管、并排比较、细粒度的人工反馈收集和排名计算。给定用户查询,平台展示两个不同Agent的最终报告以及生成过程中的中间步骤。标注者可以通过并排比较评估最终报告的整体质量,并针对中间步骤或最终报告中的特定文本片段提供详细反馈。此外,本文还开发了一个名为Simple Deepresearch的端到端Agent框架,作为基线,方便集成各种大型语言模型,将其转化为深度研究Agent进行评估。为了展示该平台在深度研究Agent开发中的实用性,作者收集了17位标注者对三个深度研究Agent的真实用户偏好数据。
🔬 方法详解
问题定义:现有深度研究Agent的评估方法难以提供细粒度的反馈,尤其是在长报告和中间步骤的评估上。缺乏有效的工具来比较不同Agent的性能,并收集用户对Agent行为的偏好数据。
核心思路:设计一个平台,允许用户并排比较不同Agent生成的报告,并提供针对报告质量和生成过程的细粒度反馈。通过收集用户偏好数据,为Agent的开发和改进提供指导。
技术框架:Deep Research Comparator平台包含以下几个主要模块:1) Agent托管:允许用户上传和管理不同的深度研究Agent。2) 并排比较:针对给定的用户查询,平台展示两个Agent生成的最终报告以及中间步骤。3) 细粒度反馈:标注者可以评估最终报告的整体质量,并针对中间步骤或特定文本片段提供详细反馈。4) 排名计算:基于收集到的用户反馈,平台可以计算Agent的排名。此外,还提供了一个名为Simple Deepresearch的端到端Agent框架,方便集成各种大型语言模型。
关键创新:该平台的核心创新在于提供了一个统一的框架,将Agent托管、并排比较、细粒度反馈和排名计算整合在一起,从而为深度研究Agent的评估和开发提供了一个全面的解决方案。Simple Deepresearch框架简化了Agent的构建过程,降低了使用门槛。
关键设计:平台允许标注者针对最终报告的多个方面进行评分,例如相关性、准确性和流畅性。同时,标注者还可以对Agent的中间步骤进行评估,例如搜索结果的质量和信息提取的准确性。Simple Deepresearch框架采用模块化设计,允许用户灵活地选择和组合不同的组件,例如搜索引擎、信息提取器和报告生成器。具体参数设置和损失函数等细节在论文中未详细描述,属于未知信息。
🖼️ 关键图片


📊 实验亮点
该平台收集了17位标注者对三个深度研究Agent的真实用户偏好数据,验证了平台在深度研究Agent开发中的实用性。具体性能数据和提升幅度在论文中未详细给出,属于未知信息。但用户偏好数据的收集是该平台的重要贡献。
🎯 应用场景
该研究成果可应用于深度研究Agent的开发和评估,帮助研究人员和开发者更好地理解Agent的优势和不足,并针对性地进行改进。该平台可以促进深度研究Agent的标准化评估,推动该领域的发展。此外,该平台收集的用户偏好数据可以用于训练奖励模型,从而进一步提升Agent的性能。
📄 摘要(原文)
Effectively evaluating deep research agents that autonomously search the web, analyze information, and generate reports remains a major challenge, particularly when it comes to assessing long reports and giving detailed feedback on their intermediate steps. To address these gaps, we introduce Deep Research Comparator, a platform that offers a holistic framework for deep research agent hosting, side-by-side comparison, fine-grained human feedback collection, and ranking calculation. Given a user query, our platform displays the final reports from two different agents along with their intermediate steps during generation. Annotators can evaluate the overall quality of final reports based on side-by-side comparison, and also provide detailed feedback separately by assessing intermediate steps or specific text spans within the final report. Furthermore, we develop Simple Deepresearch, an end-to-end agent scaffold. This scaffold serves as a baseline that facilitates the easy integration of various large language models to transform them into deep research agents for evaluation. To demonstrate the platform's utility for deep research agent development, we have collected real user preference data from 17 annotators on three deep research agents. A demo video of our platform can be found at https://www.youtube.com/watch?v=g4d2dnbdseg.