CREW-WILDFIRE: Benchmarking Agentic Multi-Agent Collaborations at Scale
作者: Jonathan Hyun, Nicholas R Waytowich, Boyuan Chen
分类: cs.MA, cs.AI
发布日期: 2025-07-07 (更新: 2025-12-12)
备注: Our project website is at: http://generalroboticslab.com/CREW-Wildfire
💡 一句话要点
CREW-WILDFIRE:大规模Agentic多智能体协作基准测试环境
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多智能体系统 大型语言模型 基准测试 野火响应 人机协作
📋 核心要点
- 现有基准测试难以评估LLM多智能体系统在复杂动态环境中的可扩展性和协调能力。
- CREW-Wildfire提供了一个大规模、部分可观察、具有随机动态的野火响应模拟环境。
- 通过评估现有LLM框架,揭示了大规模协调、通信和长时程规划方面的挑战。
📝 摘要(中文)
本文提出了CREW-Wildfire,一个开源基准测试环境,旨在评估基于大型语言模型(LLM)的多智能体系统在复杂、动态、真实世界任务中的可扩展性、鲁棒性和协调能力。现有基准测试在评估这些能力方面存在不足,因为它们通常侧重于小规模、完全可观察或低复杂度的领域。CREW-Wildfire构建于人机协作CREW模拟平台之上,提供程序生成的野火响应场景,具有大型地图、异构智能体、部分可观察性、随机动态和长时程规划目标。该环境通过模块化的感知和执行模块支持低级控制和高级自然语言交互。通过对几种最先进的基于LLM的多智能体Agentic AI框架进行评估,揭示了大规模协调、通信、空间推理和不确定性下的长时程规划方面存在的显著性能差距。CREW-Wildfire为推进可扩展多智能体Agentic智能的研究奠定了基础。
🔬 方法详解
问题定义:现有的大型语言模型(LLM)驱动的多智能体系统缺乏在复杂、动态、大规模真实世界场景下的有效评估基准。现有环境通常规模较小,可观测性高,复杂度低,无法充分测试智能体在不确定性下的长期规划和协作能力。因此,需要一个更具挑战性的基准来推动相关研究。
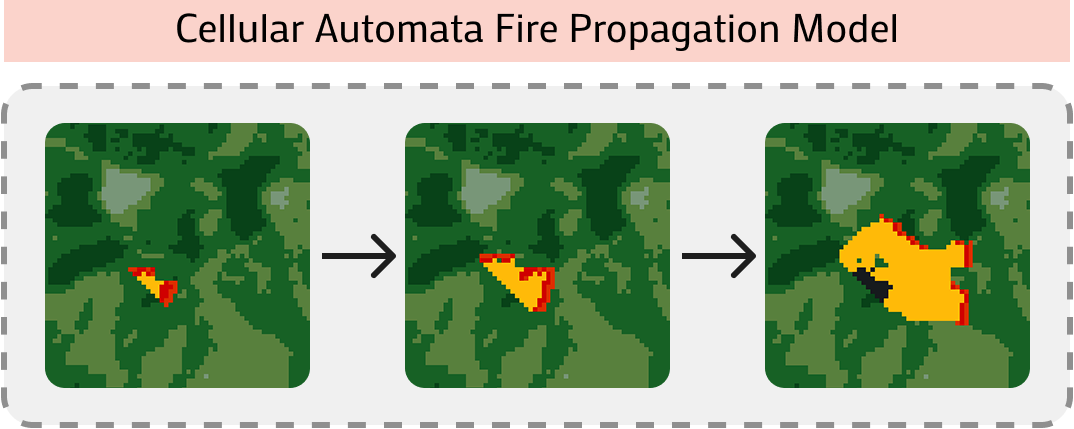
核心思路:CREW-Wildfire的核心思路是构建一个基于野火响应的模拟环境,该环境具有大规模地图、异构智能体、部分可观察性、随机动态和长时程规划目标。通过模拟真实的野火场景,可以更全面地评估多智能体系统在复杂环境中的性能。
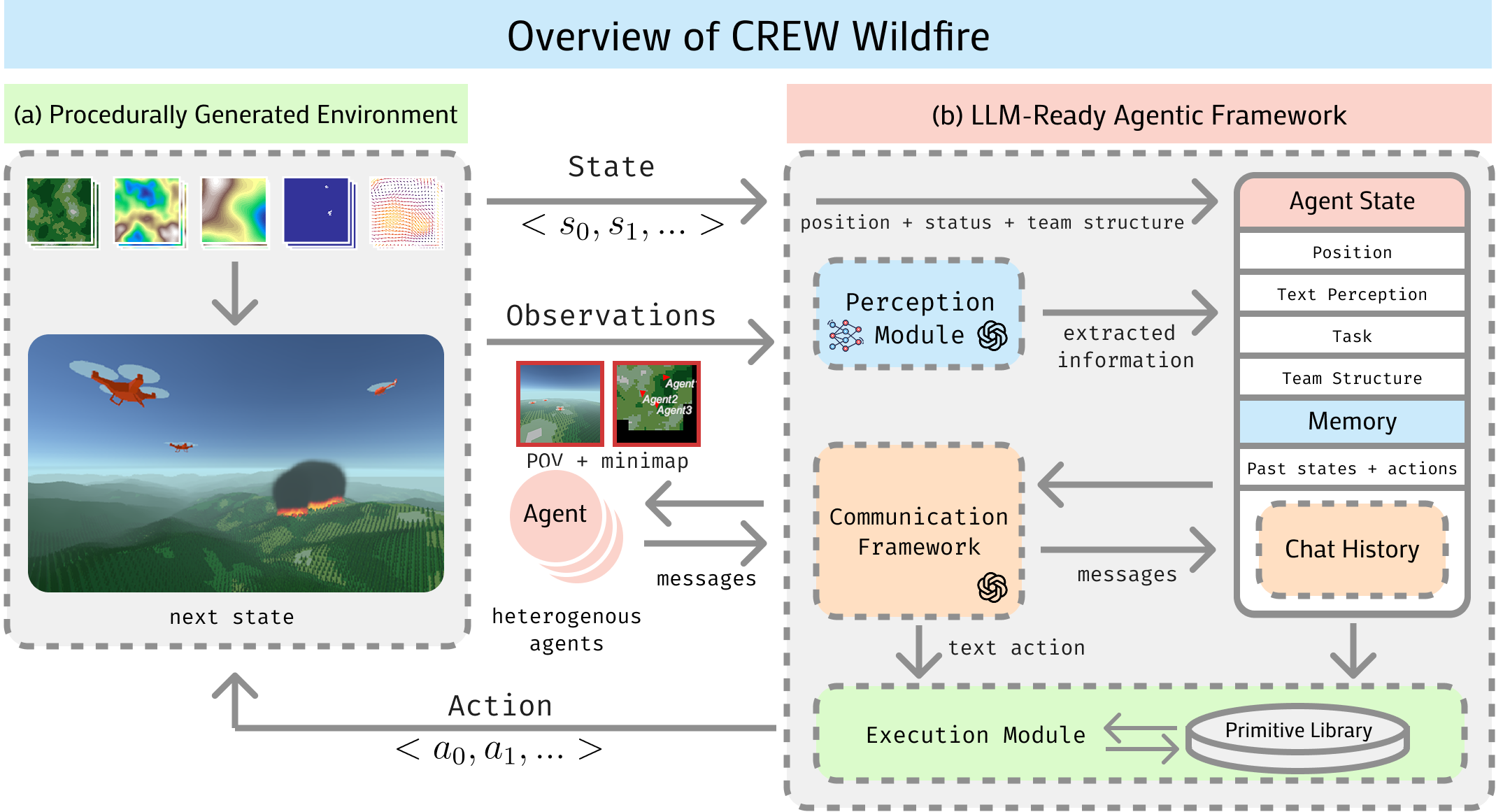
技术框架:CREW-Wildfire构建于CREW模拟平台之上,包含以下主要模块:1) 环境生成器:程序化生成野火场景,包括地图、火势蔓延、资源分布等;2) 智能体接口:提供低级控制和高级自然语言交互接口,允许智能体执行动作和进行通信;3) 感知模块:模拟智能体的感知能力,提供部分可观察的信息;4) 执行模块:将智能体的动作转化为环境中的实际操作;5) 评估指标:用于评估智能体的性能,包括灭火效率、资源利用率、协作程度等。
关键创新:CREW-Wildfire的关键创新在于其环境的复杂性和规模。与现有基准相比,CREW-Wildfire提供了更真实的野火场景,具有更大的地图、更多的智能体、更复杂的动态和更长的规划 horizon。此外,该环境还支持低级控制和高级自然语言交互,允许智能体进行更灵活的协作。
关键设计:CREW-Wildfire的关键设计包括:1) 程序化生成环境,保证了场景的多样性和可扩展性;2) 部分可观察性,模拟了真实世界中智能体只能获取部分信息的限制;3) 随机动态,模拟了野火蔓延的不确定性;4) 长时程规划目标,要求智能体进行长期规划和协作;5) 模块化的感知和执行模块,方便研究人员进行定制和扩展。
🖼️ 关键图片

📊 实验亮点
论文通过在CREW-Wildfire上评估几种最先进的基于LLM的多智能体Agentic AI框架,揭示了现有方法在处理大规模协调、通信、空间推理和不确定性下的长时程规划方面的不足。实验结果表明,现有方法在复杂环境中的性能与人类专家相比仍有较大差距,这突出了该领域的研究潜力。
🎯 应用场景
CREW-Wildfire可用于评估和改进基于LLM的多智能体系统在复杂、动态环境中的性能,例如灾害响应、资源管理、交通调度等。该基准测试环境可以帮助研究人员开发更智能、更可靠的多智能体系统,从而提高这些应用领域的效率和安全性。未来,该环境可以扩展到其他领域,例如城市规划、供应链管理等。
📄 摘要(原文)
Despite rapid progress in large language model (LLM)-based multi-agent systems, current benchmarks fall short in evaluating their scalability, robustness, and coordination capabilities in complex, dynamic, real-world tasks. Existing environments typically focus on small-scale, fully observable, or low-complexity domains, limiting their utility for developing and assessing next-generation multi-agent Agentic AI frameworks. We introduce CREW-Wildfire, an open-source benchmark designed to close this gap. Built atop the human-AI teaming CREW simulation platform, CREW-Wildfire offers procedurally generated wildfire response scenarios featuring large maps, heterogeneous agents, partial observability, stochastic dynamics, and long-horizon planning objectives. The environment supports both low-level control and high-level natural language interactions through modular Perception and Execution modules. We implement and evaluate several state-of-the-art LLM-based multi-agent Agentic AI frameworks, uncovering significant performance gaps that highlight the unsolved challenges in large-scale coordination, communication, spatial reasoning, and long-horizon planning under uncertainty. By providing more realistic complexity, scalable architecture, and behavioral evaluation metrics, CREW-Wildfire establishes a critical foundation for advancing research in scalable multi-agent Agentic intelligence. All code, environments, data, and baselines will be released to support future research in this emerging domain.