DARIL: When Imitation Learning outperforms Reinforcement Learning in Surgical Action Planning
作者: Maxence Boels, Harry Robertshaw, Thomas C Booth, Prokar Dasgupta, Alejandro Granados, Sebastien Ourselin
分类: cs.AI, cs.CV
发布日期: 2025-07-07 (更新: 2025-10-20)
备注: Paper accepted at the MICCAI2025 workshop proceedings on COLlaborative Intelligence and Autonomy in Image-guided Surgery (COLAS)
💡 一句话要点
DARIL在手术动作规划中超越强化学习,解决实时辅助难题
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 手术动作规划 模仿学习 强化学习 机器人手术 序列决策
📋 核心要点
- 手术动作规划旨在预测手术中的下一步动作,现有方法难以充分利用专家演示数据。
- 提出双任务自回归模仿学习(DARIL)框架,结合动作三元组识别和下一帧预测,提升规划性能。
- 实验表明,DARIL优于多种强化学习变体,揭示了模仿学习在特定手术场景下的优势。
📝 摘要(中文)
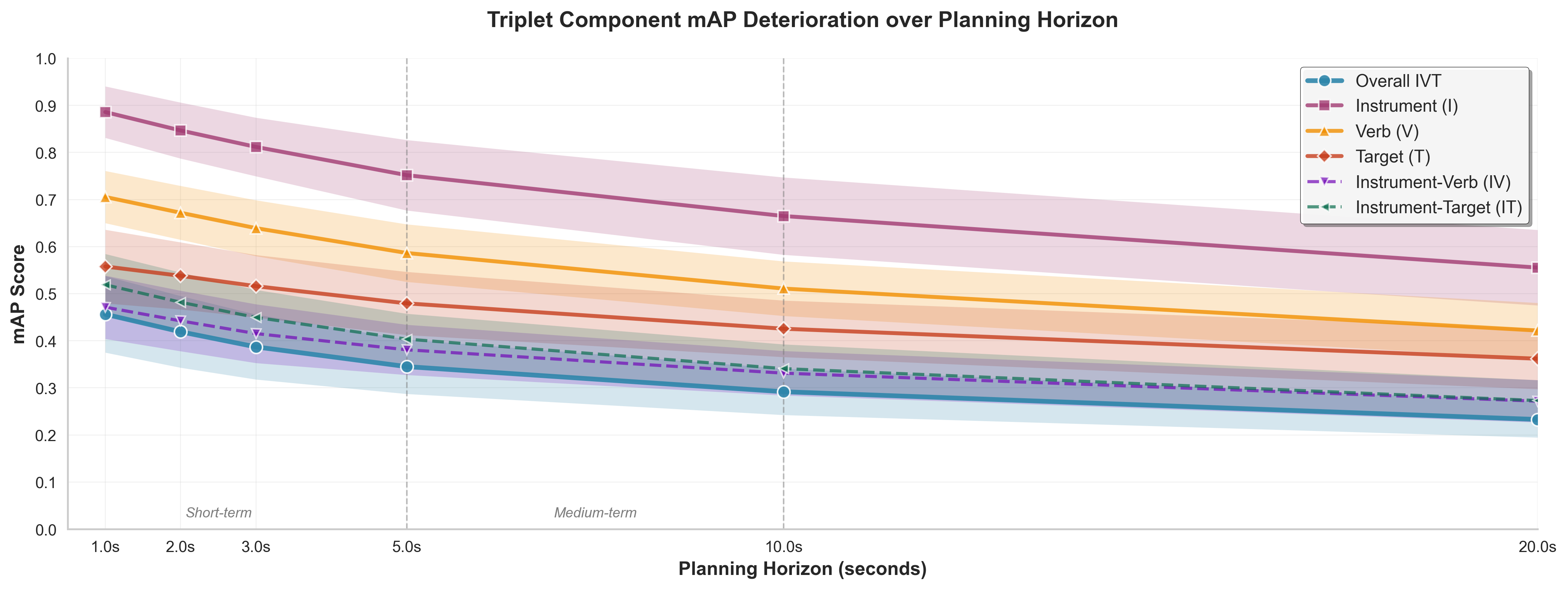
手术动作规划需要预测未来器械-动作-目标三元组,以实现实时辅助。虽然遥操作机器人手术为模仿学习(IL)提供了自然的专家演示,但强化学习(RL)可能通过自我探索发现更优策略。本文首次在CholecT50数据集上全面比较了IL与RL在手术动作规划中的性能。提出的双任务自回归模仿学习(DARIL)基线实现了34.6%的动作三元组识别mAP和33.6%的下一帧预测mAP,在10秒预测范围内的规划性能平滑下降至29.2%。评估了三种RL变体:基于世界模型的RL、直接视频RL和逆向RL增强。令人惊讶的是,所有RL方法都逊于DARIL——基于世界模型的RL在10秒时降至3.1% mAP,而直接视频RL仅达到15.9%。分析表明,在专家标注的测试集上进行分布匹配系统性地偏向于IL,而非可能有效的、但与训练演示不同的RL策略。这挑战了关于RL在序列决策中优越性的假设,并为手术AI开发提供了关键见解。
🔬 方法详解
问题定义:手术动作规划旨在预测手术过程中下一步的器械、动作和目标,为医生提供实时辅助。现有方法,特别是强化学习,虽然理论上可以通过探索找到更优策略,但在实际手术场景中,由于奖励函数设计困难、探索空间巨大等问题,难以超越模仿学习的效果。现有模仿学习方法可能无法充分利用专家演示数据中的时序信息和多任务关联。
核心思路:论文的核心思路是利用模仿学习,特别是双任务自回归模仿学习(DARIL),直接从专家演示数据中学习手术动作规划策略。DARIL通过同时学习动作三元组识别和下一帧预测,从而更好地捕捉手术过程中的时序依赖关系和视觉信息。这种方法避免了强化学习中奖励函数设计的复杂性,并充分利用了专家演示数据。
技术框架:DARIL框架包含两个主要任务:动作三元组识别和下一帧预测。动作三元组识别任务旨在预测当前帧的器械、动作和目标。下一帧预测任务旨在预测下一帧的视觉特征。这两个任务通过一个共享的自回归模型进行学习,该模型可以捕捉手术过程中的时序依赖关系。整体流程是:输入视频帧序列,通过共享的自回归模型,分别预测动作三元组和下一帧特征,然后使用相应的损失函数进行训练。
关键创新:论文的关键创新在于提出了双任务自回归模仿学习(DARIL)框架,将动作三元组识别和下一帧预测结合起来,从而更好地捕捉手术过程中的时序依赖关系和视觉信息。此外,论文还首次全面比较了模仿学习和强化学习在手术动作规划中的性能,并揭示了模仿学习在特定手术场景下的优势。
关键设计:DARIL使用Transformer作为自回归模型的基础架构。损失函数包括动作三元组识别的交叉熵损失和下一帧预测的均方误差损失。在训练过程中,采用teacher forcing策略,即使用真实标签作为下一步的输入。为了评估规划性能,采用mAP作为评估指标,并考虑不同时间范围的规划性能。
🖼️ 关键图片
📊 实验亮点
实验结果表明,提出的DARIL方法在CholecT50数据集上取得了显著的性能提升。DARIL实现了34.6%的动作三元组识别mAP和33.6%的下一帧预测mAP,优于所有评估的强化学习变体。例如,基于世界模型的RL在10秒时降至3.1% mAP,而直接视频RL仅达到15.9%。这表明在手术动作规划中,模仿学习在利用专家演示数据方面具有优势。
🎯 应用场景
该研究成果可应用于机器人辅助手术系统,为医生提供实时的动作规划建议,提高手术效率和安全性。通过预测下一步动作,系统可以提前准备所需器械,减少手术时间。此外,该研究也为其他需要序列决策的任务提供了借鉴,例如自动驾驶、机器人导航等。
📄 摘要(原文)
Surgical action planning requires predicting future instrument-verb-target triplets for real-time assistance. While teleoperated robotic surgery provides natural expert demonstrations for imitation learning (IL), reinforcement learning (RL) could potentially discover superior strategies through self-exploration. We present the first comprehensive comparison of IL versus RL for surgical action planning on CholecT50. Our Dual-task Autoregressive Imitation Learning (DARIL) baseline achieves 34.6% action triplet recognition mAP and 33.6% next frame prediction mAP with smooth planning degradation to 29.2% at 10-second horizons. We evaluated three RL variants: world model-based RL, direct video RL, and inverse RL enhancement. Surprisingly, all RL approaches underperformed DARIL--world model RL dropped to 3.1% mAP at 10s while direct video RL achieved only 15.9%. Our analysis reveals that distribution matching on expert-annotated test sets systematically favors IL over potentially valid RL policies that differ from training demonstrations. This challenges assumptions about RL superiority in sequential decision making and provides crucial insights for surgical AI development.