ChipSeek-R1: Generating Human-Surpassing RTL with LLM via Hierarchical Reward-Driven Reinforcement Learning
作者: Zhirong Chen, Kaiyan Chang, Zhuolin Li, Xinyang He, Chujie Chen, Cangyuan Li, Mengdi Wang, Haobo Xu, Yinhe Han, Ying Wang
分类: cs.AI, cs.AR, cs.PL
发布日期: 2025-07-07
💡 一句话要点
ChipSeek-R1:通过层级奖励驱动强化学习,利用LLM生成超越人类水平的RTL代码
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: RTL代码生成 大型语言模型 强化学习 硬件设计 PPA优化
📋 核心要点
- 现有方法难以兼顾RTL代码的功能正确性和硬件质量(PPA),监督学习PPA欠优,后处理方法效率低下。
- ChipSeek-R1采用层级奖励驱动的强化学习,在训练LLM时同时考虑语法、功能正确性和PPA指标。
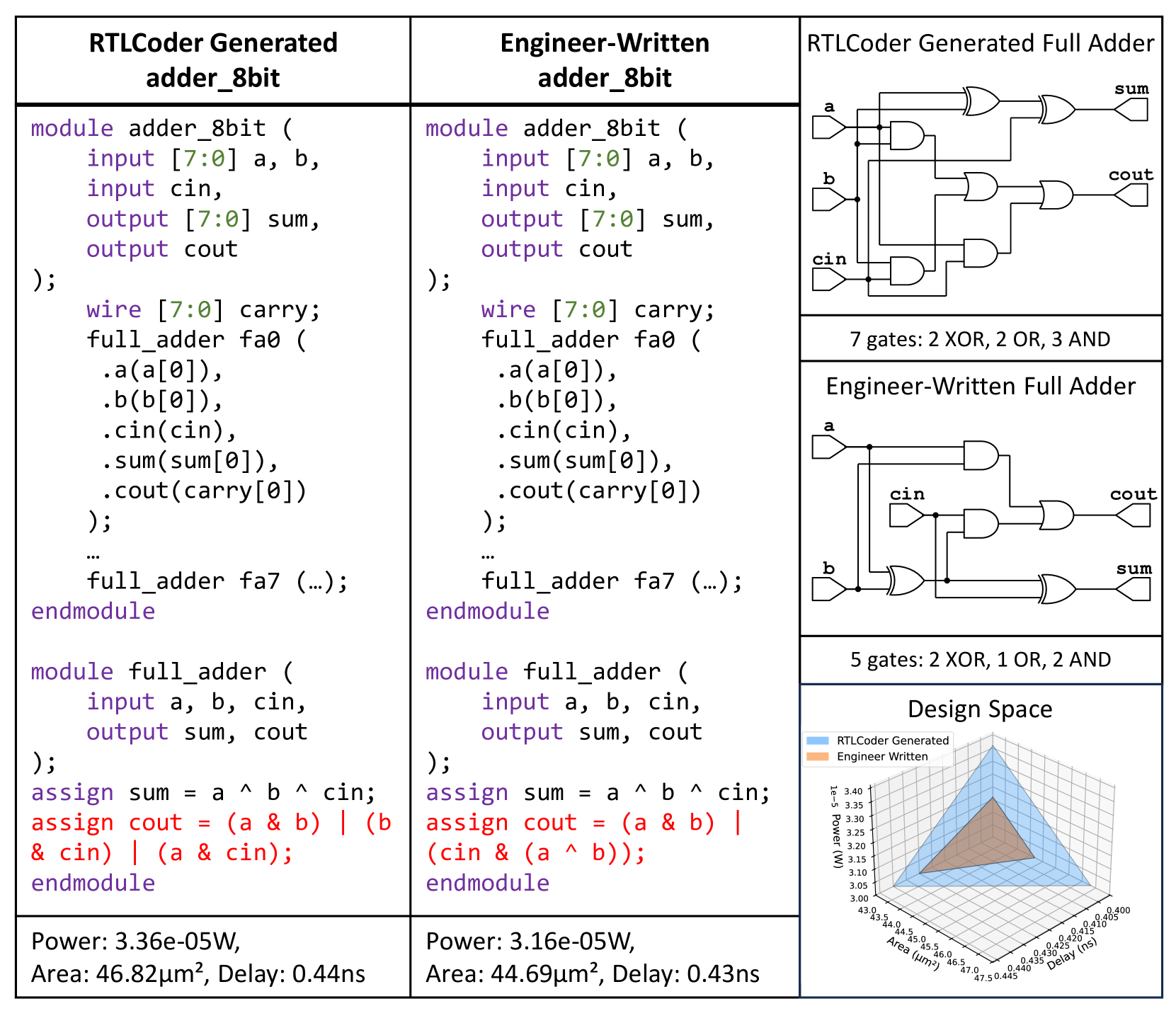
- 实验表明,ChipSeek-R1在功能正确性方面达到SOTA,并在RTLLM基准上生成了超越人类水平的RTL设计。
📝 摘要(中文)
大型语言模型(LLM)在自动化寄存器传输级(RTL)代码生成方面显示出巨大的潜力。然而,当前的方法面临一个关键挑战:它们无法同时优化功能正确性和硬件质量(功耗、性能、面积 - PPA)。基于监督微调的方法通常生成功能正确的代码,但PPA指标欠佳,缺乏学习优化原则的机制。相比之下,在生成后尝试改进PPA指标的后处理技术通常效率低下,因为它们在外部操作而不更新LLM的参数,因此无法提高模型内在的设计能力。为了弥合这一差距,我们引入了ChipSeek-R1,一个层级奖励驱动的强化学习框架,用于训练LLM生成既能实现功能正确性又能优化PPA指标的RTL代码。ChipSeek-R1采用层级奖励系统,在强化学习期间结合了关于语法、功能正确性(来自模拟器)和PPA指标(来自综合工具)的直接反馈。这使得模型能够通过试错学习复杂的硬件设计权衡,生成功能正确且PPA优化的RTL代码。在标准基准(VerilogEval,RTLLM)上评估ChipSeek-R1,我们在功能正确性方面取得了最先进的结果。值得注意的是,在RTLLM基准上,ChipSeek-R1生成的27个RTL设计超越了原始人类编写代码的PPA指标。我们的发现证明了将工具链反馈集成到LLM训练中的有效性,并突出了强化学习在实现自动化生成超越人类水平的RTL代码方面的潜力。我们开源了我们的代码。
🔬 方法详解
问题定义:现有RTL代码生成方法主要存在两个痛点。一是基于监督学习的方法,虽然能保证功能正确性,但生成的代码在功耗、性能和面积(PPA)等硬件指标上表现不佳,缺乏优化。二是采用后处理技术优化PPA,但这种方法无法更新LLM的参数,无法从根本上提升模型的设计能力。因此,如何让LLM在生成RTL代码时,同时保证功能正确性和优异的PPA指标是一个亟待解决的问题。
核心思路:ChipSeek-R1的核心思路是利用强化学习,通过层级奖励机制,让LLM在生成RTL代码的过程中,不断学习和优化,最终生成既功能正确又PPA优化的代码。这种方法将工具链的反馈(包括模拟器和综合工具)直接融入到LLM的训练过程中,使模型能够通过试错学习复杂的硬件设计权衡。
技术框架:ChipSeek-R1采用层级奖励驱动的强化学习框架。该框架包含以下几个主要组成部分:首先,LLM作为智能体,负责生成RTL代码。其次,环境包括模拟器和综合工具,用于评估生成的代码的功能正确性和PPA指标。第三,层级奖励系统,根据代码的语法正确性、功能正确性和PPA指标,给予LLM不同的奖励。最后,强化学习算法,用于更新LLM的参数,使其能够生成更好的RTL代码。整个流程是一个迭代的过程,LLM不断生成代码,环境评估代码,奖励系统反馈奖励,强化学习算法更新LLM,直到生成满足要求的RTL代码。
关键创新:ChipSeek-R1最重要的技术创新点在于其层级奖励驱动的强化学习框架。与传统的监督学习或后处理方法不同,ChipSeek-R1将工具链的反馈直接集成到LLM的训练过程中,使模型能够学习复杂的硬件设计权衡。此外,层级奖励系统能够更精细地指导LLM的学习,使其能够更快地收敛到最优解。
关键设计:ChipSeek-R1的关键设计包括:1)层级奖励函数的设计,需要仔细权衡语法、功能和PPA指标之间的权重,以避免模型过度优化某一指标而忽略其他指标。2)强化学习算法的选择,需要选择适合RTL代码生成任务的算法,例如策略梯度算法或深度Q网络。3)LLM的架构设计,需要选择适合RTL代码生成的LLM架构,例如Transformer或LSTM。
🖼️ 关键图片


📊 实验亮点
ChipSeek-R1在标准基准测试中表现出色。在VerilogEval基准上,ChipSeek-R1在功能正确性方面达到了最先进水平。更重要的是,在RTLLM基准上,ChipSeek-R1生成的27个RTL设计在PPA指标上超越了原始人类编写的代码。这些结果表明,将工具链反馈集成到LLM训练中是有效的,并且强化学习有潜力实现自动化生成超越人类水平的RTL代码。
🎯 应用场景
ChipSeek-R1具有广泛的应用前景,可用于自动化硬件设计、加速芯片开发流程、降低设计成本。通过自动生成高质量的RTL代码,可以显著缩短芯片的上市时间,并提高芯片的性能和效率。此外,该技术还可以应用于定制化硬件设计,根据特定应用的需求,自动生成优化的RTL代码。未来,该技术有望成为硬件设计领域的重要工具,推动硬件设计的自动化和智能化。
📄 摘要(原文)
Large Language Models (LLMs) show significant potential for automating Register-Transfer Level (RTL) code generation. However, current approaches face a critical challenge: they can not simultaneously optimize for functional correctness and hardware quality (Power, Performance, Area - PPA). Methods based on supervised fine-tuning often generate functionally correct but PPA-suboptimal code, lacking mechanisms to learn optimization principles. In contrast, post-processing techniques that attempt to improve PPA metrics after generation are often inefficient because they operate externally without updating the LLM's parameters, thus failing to enhance the model's intrinsic design capabilities. To bridge this gap, we introduce ChipSeek-R1, a hierarchical reward-driven reinforcement learning framework to train LLMs to generate RTL code that achieves both functional correctness and optimized PPA metrics. ChipSeek-R1 employs a hierarchical reward system, which incorporates direct feedback on syntax, functional correctness (from simulators) and PPA metrics (from synthesis tools) during reinforcement learning. This enables the model to learn complex hardware design trade-offs via trial-and-error, generating RTL code that is both functionally correct and PPA-optimized. Evaluating ChipSeek-R1 on standard benchmarks (VerilogEval, RTLLM), we achieve state-of-the-art results in functional correctness. Notably, on the RTLLM benchmark, ChipSeek-R1 generated 27 RTL designs surpassing the PPA metrics of the original human-written code. Our findings demonstrate the effectiveness of integrating toolchain feedback into LLM training and highlight the potential for reinforcement learning to enable automated generation of human-surpassing RTL code. We open-source our code in anonymous github.