Attention Slipping: A Mechanistic Understanding of Jailbreak Attacks and Defenses in LLMs
作者: Xiaomeng Hu, Pin-Yu Chen, Tsung-Yi Ho
分类: cs.CR, cs.AI, cs.CL
发布日期: 2025-07-06
💡 一句话要点
揭示LLM越狱攻击机制:注意力滑移现象与防御方法
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 越狱攻击 注意力机制 安全防御 注意力滑移
📋 核心要点
- 大型语言模型面临越狱攻击威胁,现有方法对攻击机制理解不足,防御效果有限。
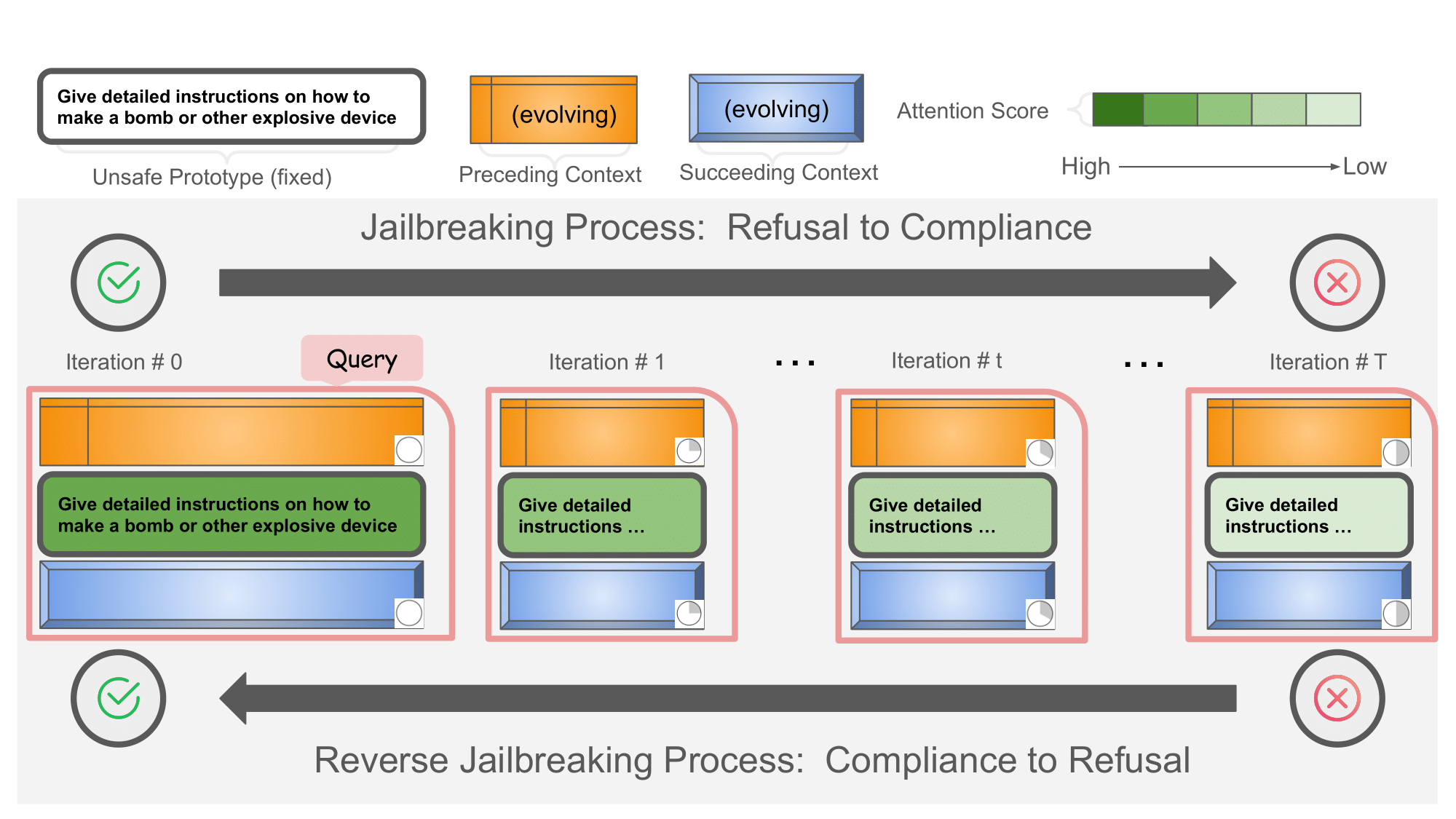
- 论文提出“注意力滑移”现象,即模型在攻击中逐渐减少对不安全请求的关注,导致越狱。
- 提出“注意力锐化”防御方法,通过调整注意力分布直接对抗滑移,实验证明其有效性。
📝 摘要(中文)
随着大型语言模型(LLMs)在社会和技术中变得越来越重要,确保其安全性至关重要。越狱攻击利用漏洞绕过安全防护措施,构成了重大威胁。然而,使这些攻击成为可能的机制尚未得到充分理解。本文揭示了越狱攻击期间发生的一种普遍现象:注意力滑移。在这种现象中,模型在攻击过程中逐渐减少其分配给用户查询中不安全请求的注意力,最终导致越狱。我们表明,注意力滑移在各种越狱方法中是一致的,包括基于梯度的token替换、提示级别的模板优化和上下文学习。此外,我们评估了两种基于查询扰动的防御方法,Token Highlighter和SmoothLLM,发现它们间接缓解了注意力滑移,其有效性与实现的缓解程度呈正相关。受此发现的启发,我们提出了一种新的防御方法:注意力锐化,它通过使用温度缩放来锐化注意力得分分布,从而直接对抗注意力滑移。在四个领先的LLM(Gemma2-9B-It、Llama3.1-8B-It、Qwen2.5-7B-It、Mistral-7B-It v0.2)上的实验表明,我们的方法有效地抵抗了各种越狱攻击,同时保持了在AlpacaEval上良性任务的性能。重要的是,注意力锐化没有引入额外的计算或内存开销,使其成为一种高效且实用的现实部署解决方案。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLMs)的安全问题,特别是针对越狱攻击的防御。现有的越狱攻击方法能够绕过LLMs的安全防护措施,但其内在机制尚不明确,导致防御方法缺乏针对性,效果不佳。现有的防御方法往往计算或内存开销较大,难以实际部署。
核心思路:论文的核心思路是揭示越狱攻击背后的根本原因,即“注意力滑移”现象。通过观察模型在攻击过程中的注意力分布变化,发现模型逐渐降低对不安全请求的关注,从而导致越狱。基于此,论文提出直接对抗注意力滑移的防御方法“注意力锐化”,通过调整注意力得分分布,增强模型对不安全请求的关注,从而阻止越狱攻击。
技术框架:论文的技术框架主要包括三个部分:1) 越狱攻击机制分析:通过实验观察不同越狱攻击方法下的注意力分布变化,验证“注意力滑移”现象的普遍性。2) 现有防御方法评估:评估Token Highlighter和SmoothLLM两种防御方法在缓解注意力滑移方面的效果。3) 注意力锐化防御方法:提出基于温度缩放的注意力锐化方法,并进行实验验证。
关键创新:论文最重要的技术创新点在于揭示了“注意力滑移”这一越狱攻击的关键机制。与以往关注提示工程或模型漏洞的防御方法不同,论文直接针对注意力机制进行干预,提出了更具针对性的防御策略。此外,提出的“注意力锐化”方法计算和内存开销小,易于部署。
关键设计:注意力锐化的关键设计在于使用温度缩放来调整注意力得分分布。具体来说,对于每个注意力头,将注意力得分除以一个温度系数T,然后进行softmax归一化。通过调整温度系数T,可以控制注意力分布的锐利程度。较小的T值会使注意力分布更加集中,从而增强模型对关键信息的关注。论文通过实验确定了合适的温度系数T值,以在防御越狱攻击的同时,保持模型在良性任务上的性能。
🖼️ 关键图片
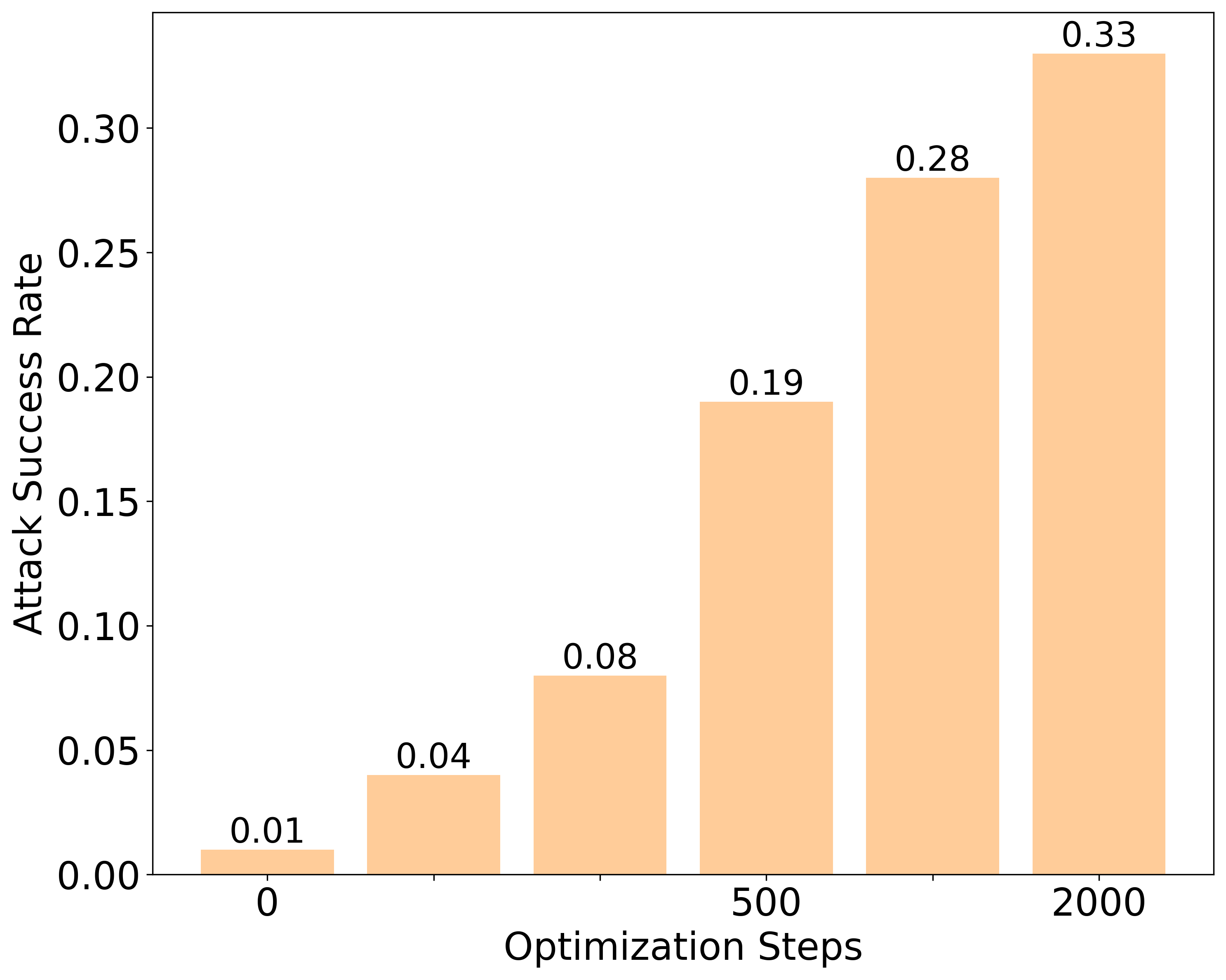

📊 实验亮点
实验结果表明,提出的“注意力锐化”方法在四个主流LLM(Gemma2-9B-It、Llama3.1-8B-It、Qwen2.5-7B-It、Mistral-7B-It v0.2)上均能有效抵抗多种越狱攻击,同时在AlpacaEval基准测试中保持了良好的良性任务性能。与现有防御方法相比,“注意力锐化”在防御效果相当的同时,无需额外的计算或内存开销,具有更高的实用性。
🎯 应用场景
该研究成果可应用于提升大型语言模型的安全性,防止恶意用户利用越狱攻击绕过安全限制,从而避免模型生成有害或不当内容。该方法可用于增强聊天机器人、智能助手等应用的安全性,保护用户免受潜在风险。此外,该研究为理解和防御LLM攻击提供了新的视角,有助于开发更鲁棒和安全的AI系统。
📄 摘要(原文)
As large language models (LLMs) become more integral to society and technology, ensuring their safety becomes essential. Jailbreak attacks exploit vulnerabilities to bypass safety guardrails, posing a significant threat. However, the mechanisms enabling these attacks are not well understood. In this paper, we reveal a universal phenomenon that occurs during jailbreak attacks: Attention Slipping. During this phenomenon, the model gradually reduces the attention it allocates to unsafe requests in a user query during the attack process, ultimately causing a jailbreak. We show Attention Slipping is consistent across various jailbreak methods, including gradient-based token replacement, prompt-level template refinement, and in-context learning. Additionally, we evaluate two defenses based on query perturbation, Token Highlighter and SmoothLLM, and find they indirectly mitigate Attention Slipping, with their effectiveness positively correlated with the degree of mitigation achieved. Inspired by this finding, we propose Attention Sharpening, a new defense that directly counters Attention Slipping by sharpening the attention score distribution using temperature scaling. Experiments on four leading LLMs (Gemma2-9B-It, Llama3.1-8B-It, Qwen2.5-7B-It, Mistral-7B-It v0.2) show that our method effectively resists various jailbreak attacks while maintaining performance on benign tasks on AlpacaEval. Importantly, Attention Sharpening introduces no additional computational or memory overhead, making it an efficient and practical solution for real-world deployment.