A Survey on Proactive Defense Strategies Against Misinformation in Large Language Models
作者: Shuliang Liu, Hongyi Liu, Aiwei Liu, Bingchen Duan, Qi Zheng, Yibo Yan, He Geng, Peijie Jiang, Jia Liu, Xuming Hu
分类: cs.IR, cs.AI, cs.CL
发布日期: 2025-07-05
备注: Accepted by ACL 2025 Findings
💡 一句话要点
提出针对大型语言模型中错误信息的主动防御三支柱框架
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 错误信息 主动防御 知识可信度 推理可靠性
📋 核心要点
- 传统方法难以有效应对LLM生成的可自我强化、高可信度且多语言快速传播的错误信息。
- 论文提出主动防御范式,构建知识可信度、推理可靠性和输入鲁棒性三大支柱。
- 实验表明,主动防御策略在预防错误信息方面比传统方法提升高达63%,但存在计算开销和泛化挑战。
📝 摘要(中文)
大型语言模型(LLMs)在关键领域的广泛部署加剧了算法生成错误信息带来的社会风险。与传统虚假内容不同,LLM生成的错误信息可以自我强化,高度可信,并能在多种语言中快速传播,传统检测方法难以有效缓解。本文提出了一种主动防御范式,从被动的后验检测转向预期的缓解策略。我们提出了一个“三支柱”框架:(1)知识可信度,加强训练和部署数据的完整性;(2)推理可靠性,在推理过程中嵌入自我纠正机制;(3)输入鲁棒性,增强模型接口对对抗性攻击的抵抗力。通过对现有技术的全面调查和比较元分析,我们证明了主动防御策略在错误信息预防方面比传统方法提高了高达63%,尽管存在不可忽略的计算开销和泛化挑战。我们认为,未来的研究应侧重于共同设计稳健的知识基础、推理认证和抗攻击接口,以确保LLM能够有效地应对各种领域的错误信息。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLMs)生成和传播错误信息的问题。现有方法主要集中在事后检测,无法有效应对LLM生成错误信息的自我强化、高可信度和快速传播等特性。这些传统方法在面对对抗性攻击时也显得脆弱,难以保证LLM在各种场景下的可靠性。
核心思路:论文的核心思路是从被动检测转向主动防御,通过在LLM的知识、推理和输入三个关键环节进行干预,从而提前预防和减轻错误信息的产生和传播。这种前瞻性的方法旨在提高LLM的整体鲁棒性和可靠性,使其能够更好地应对各种挑战。
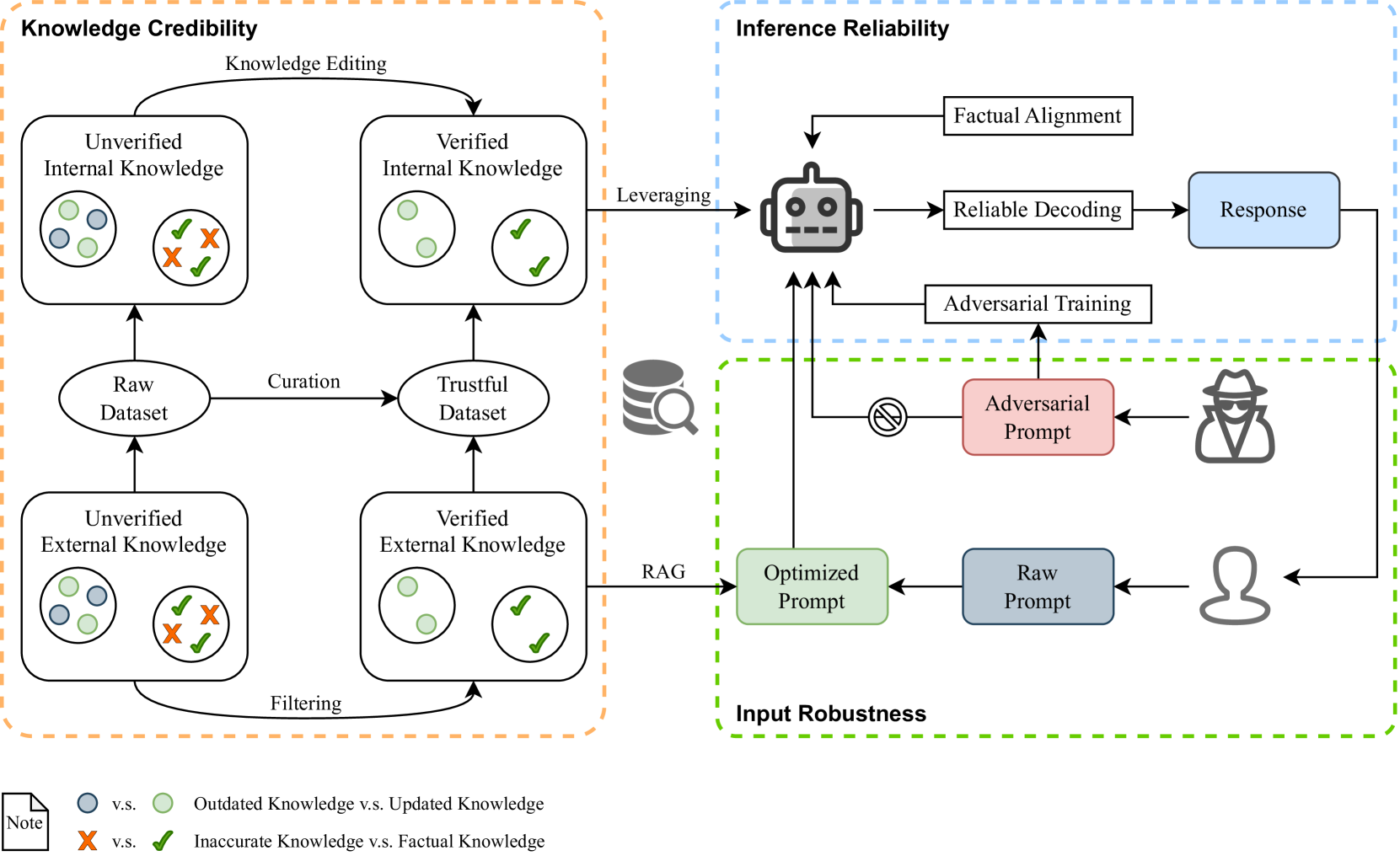
技术框架:论文提出了一个“三支柱”框架,包含以下三个主要模块: 1. 知识可信度:旨在确保LLM使用的训练数据和知识库的准确性和完整性,防止模型学习到错误的或有偏见的信息。 2. 推理可靠性:通过在推理过程中嵌入自我纠正机制,使LLM能够识别和纠正自身的错误,从而提高推理的准确性和可靠性。 3. 输入鲁棒性:增强LLM接口对对抗性攻击的抵抗力,防止恶意用户通过构造特殊的输入来诱导模型生成错误信息。
关键创新:论文的关键创新在于提出了一个系统性的主动防御框架,将错误信息防御从被动的事后检测转变为主动的预防和缓解。这种方法不仅考虑了知识的准确性,还关注了推理过程的可靠性和输入接口的安全性,从而构建了一个更加全面和有效的防御体系。
关键设计:论文中并未详细描述具体的参数设置、损失函数或网络结构等技术细节,而是侧重于框架的整体设计和各个模块的功能。未来的研究可以针对每个模块的具体实现进行深入探讨,例如,可以使用知识图谱来增强知识可信度,使用强化学习来训练自我纠正机制,使用对抗训练来提高输入鲁棒性。这些具体的技术细节将直接影响主动防御策略的性能和效果。
🖼️ 关键图片
📊 实验亮点
论文通过综合性的实验和元分析表明,所提出的主动防御策略在预防错误信息方面比传统方法提高了高达63%。这一显著的性能提升证明了主动防御范式的有效性。然而,论文也指出,主动防御策略存在计算开销和泛化挑战,需要在未来的研究中进一步优化。
🎯 应用场景
该研究成果可应用于各种依赖大型语言模型的领域,如新闻媒体、金融分析、医疗诊断等。通过主动防御错误信息,可以提高LLM在这些领域的应用可靠性,减少虚假信息带来的负面影响,并为构建可信赖的人工智能系统奠定基础。未来,该研究有望推动LLM在更多敏感领域的应用,例如教育和法律。
📄 摘要(原文)
The widespread deployment of large language models (LLMs) across critical domains has amplified the societal risks posed by algorithmically generated misinformation. Unlike traditional false content, LLM-generated misinformation can be self-reinforcing, highly plausible, and capable of rapid propagation across multiple languages, which traditional detection methods fail to mitigate effectively. This paper introduces a proactive defense paradigm, shifting from passive post hoc detection to anticipatory mitigation strategies. We propose a Three Pillars framework: (1) Knowledge Credibility, fortifying the integrity of training and deployed data; (2) Inference Reliability, embedding self-corrective mechanisms during reasoning; and (3) Input Robustness, enhancing the resilience of model interfaces against adversarial attacks. Through a comprehensive survey of existing techniques and a comparative meta-analysis, we demonstrate that proactive defense strategies offer up to 63\% improvement over conventional methods in misinformation prevention, despite non-trivial computational overhead and generalization challenges. We argue that future research should focus on co-designing robust knowledge foundations, reasoning certification, and attack-resistant interfaces to ensure LLMs can effectively counter misinformation across varied domains.