Addressing The Devastating Effects Of Single-Task Data Poisoning In Exemplar-Free Continual Learning
作者: Stanisław Pawlak, Bartłomiej Twardowski, Tomasz Trzciński, Joost van de Weijer
分类: cs.CR, cs.AI
发布日期: 2025-07-05 (更新: 2025-08-10)
备注: Accepted at CoLLAs 2025
🔗 代码/项目: GITHUB
💡 一句话要点
针对无样本持续学习中单任务数据投毒的防御框架
🎯 匹配领域: 支柱一:机器人控制 (Robot Control)
关键词: 持续学习 数据投毒 对抗攻击 任务向量 异常检测
📋 核心要点
- 现有持续学习方法容易受到数据投毒攻击,尤其是在单任务投毒场景下,攻击者仅需访问当前任务数据即可发起攻击。
- 论文提出一种高级防御框架,结合基于任务向量的投毒任务检测方法,旨在提升持续学习模型在单任务投毒攻击下的鲁棒性。
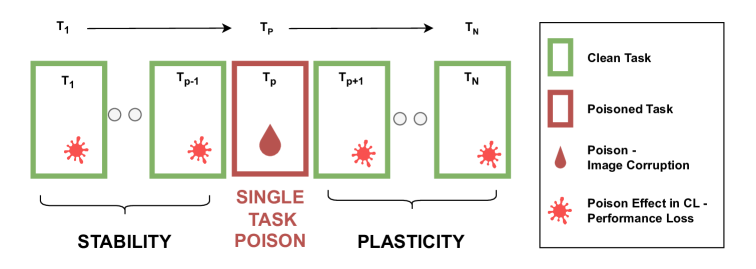
- 实验表明,即使使用简单的图像损坏手段进行单任务投毒,也会严重影响持续学习模型的稳定性和可塑性,验证了防御框架的必要性。
📝 摘要(中文)
本研究关注持续学习(CL)中与数据投毒相关的安全问题。数据投毒,即通过恶意操纵训练数据来影响机器学习模型的预测,最近被证实对CL训练的稳定性构成威胁。现有文献主要关注依赖于特定场景的攻击,而我们提出关注更简单和现实的单任务投毒(STP)威胁。与以往的投毒设置不同,在STP中,攻击者无法访问模型,也无法访问先前和未来的任务。在攻击期间,他们只能访问数据流中的当前任务。我们的研究表明,即使在这些严格的条件下,攻击者也可以使用标准的图像损坏来损害模型性能。我们证明了STP攻击能够严重破坏整个持续训练过程:降低算法的稳定性和可塑性。最后,我们提出了一个用于CL的高级防御框架,以及一种基于任务向量的投毒任务检测方法。代码可在https://github.com/stapaw/STP.git 获取。
🔬 方法详解
问题定义:论文旨在解决持续学习中单任务数据投毒(STP)带来的模型性能下降问题。现有的持续学习方法在面对恶意攻击者篡改当前任务训练数据时,模型的稳定性和可塑性会受到严重影响,导致在先前任务上的性能下降,以及在新任务上的学习能力减弱。
核心思路:论文的核心思路是设计一种防御框架,该框架能够检测并减轻受污染任务对持续学习过程的影响。通过分析任务向量,识别出潜在的投毒任务,并采取相应的措施来降低其对模型更新的影响。
技术框架:论文提出的防御框架包含两个主要模块:投毒任务检测模块和防御模块。投毒任务检测模块利用任务向量来表征每个任务的特征,并通过分析任务向量的异常程度来判断该任务是否受到投毒。防御模块则根据检测结果,对受污染任务的学习过程进行调整,例如降低其学习率或采用其他正则化手段。
关键创新:论文的关键创新在于提出了基于任务向量的投毒任务检测方法。任务向量能够有效地捕捉任务的特征,使得检测模块能够准确地识别出受污染的任务。此外,论文还提出了一个高级防御框架,该框架能够灵活地应对不同类型的投毒攻击。
关键设计:任务向量的计算方式是关键设计之一,论文可能采用了某种方式来提取每个任务的特征,例如使用任务相关的梯度信息或者激活值统计量。此外,防御模块的具体实现方式也至关重要,例如如何调整学习率、如何选择合适的正则化项等。这些细节决定了防御框架的有效性。
🖼️ 关键图片

📊 实验亮点
论文通过实验证明,即使是简单的图像损坏手段,也能对持续学习模型造成显著的性能下降。实验结果表明,提出的防御框架能够有效地检测并减轻单任务投毒攻击的影响,显著提升模型在受攻击环境下的稳定性和可塑性。具体的性能提升数据需要在论文中查找。
🎯 应用场景
该研究成果可应用于各种需要持续学习的实际场景,例如自动驾驶、智能客服、金融风控等。在这些场景中,数据可能受到恶意攻击或污染,因此需要一种有效的防御机制来保证模型的安全性和可靠性。该研究提出的防御框架可以提高持续学习模型在对抗环境下的鲁棒性,从而提升其在实际应用中的价值。
📄 摘要(原文)
Our research addresses the overlooked security concerns related to data poisoning in continual learning (CL). Data poisoning - the intentional manipulation of training data to affect the predictions of machine learning models - was recently shown to be a threat to CL training stability. While existing literature predominantly addresses scenario-dependent attacks, we propose to focus on a more simple and realistic single-task poison (STP) threats. In contrast to previously proposed poisoning settings, in STP adversaries lack knowledge and access to the model, as well as to both previous and future tasks. During an attack, they only have access to the current task within the data stream. Our study demonstrates that even within these stringent conditions, adversaries can compromise model performance using standard image corruptions. We show that STP attacks are able to strongly disrupt the whole continual training process: decreasing both the stability (its performance on past tasks) and plasticity (capacity to adapt to new tasks) of the algorithm. Finally, we propose a high-level defense framework for CL along with a poison task detection method based on task vectors. The code is available at https://github.com/stapaw/STP.git .