Rethinking and Exploring String-Based Malware Family Classification in the Era of LLMs and RAG
作者: Yufan Chen, Daoyuan Wu, Juantao Zhong, Zicheng Zhang, Debin Gao, Shuai Wang, Yingjiu Li, Ning Liu, Jiachi Chen, Rocky K. C. Chang
分类: cs.CR, cs.AI, cs.SE
发布日期: 2025-07-05 (更新: 2025-10-26)
备注: This is a technical report from Lingnan University, Hong Kong. Code is available at https://github.com/AIS2Lab/MalwareGPT
💡 一句话要点
利用LLM和RAG,重新探索基于字符串的恶意软件家族分类方法
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 恶意软件家族分类 大型语言模型 检索增强生成 字符串特征 家族特定字符串
📋 核心要点
- 现有恶意软件家族分类方法在大规模恶意软件分析平台上面临自动化样本标记和理解的挑战。
- 论文提出利用家族特定字符串(FSS)特征,结合大型语言模型(LLM)和检索增强生成(RAG)的思想进行恶意软件家族分类。
- 通过构建包含67个恶意软件家族的评估框架,实验结果表明该方法在家族分类上取得了显著的性能提升。
📝 摘要(中文)
恶意软件家族分类旨在识别恶意软件样本所属的特定家族(例如,GuLoader或BitRAT),这与仅预测是/否结果的恶意软件检测或样本分类不同。准确的家族识别可以极大地促进自动化样本标记,并加深对VirusTotal和MalwareBazaar等众包恶意软件分析平台上数据的理解,这些平台每天产生大量数据。本文探讨并评估了在大型语言模型(LLM)和检索增强生成(RAG)的新时代,使用传统二进制字符串特征进行家族分类的可行性。具体来说,我们研究了如何以类似于RAG的方式利用家族特定字符串(FSS)特征来促进家族分类。为此,我们开发了一个包含来自67个恶意软件家族的4,347个样本的评估框架,提取并分析了超过2500万个字符串,并进行了详细的消融研究,以评估四个主要模块中不同设计选择的影响,每个模块都提供了8.1%到120%的相对改进。
🔬 方法详解
问题定义:恶意软件家族分类旨在确定恶意软件样本所属的特定家族。现有的方法可能无法有效利用海量恶意软件数据中的信息,尤其是在自动化样本标记和理解方面存在挑战。传统方法可能依赖于手工特征工程或浅层机器学习模型,难以捕捉恶意软件家族之间复杂的关联。
核心思路:论文的核心思路是将家族特定字符串(FSS)特征与大型语言模型(LLM)和检索增强生成(RAG)相结合。通过提取恶意软件样本中的字符串,并将其与已知恶意软件家族的字符串特征进行匹配,从而实现家族分类。RAG的思想在于,利用检索到的相关家族信息来增强LLM的分类能力。
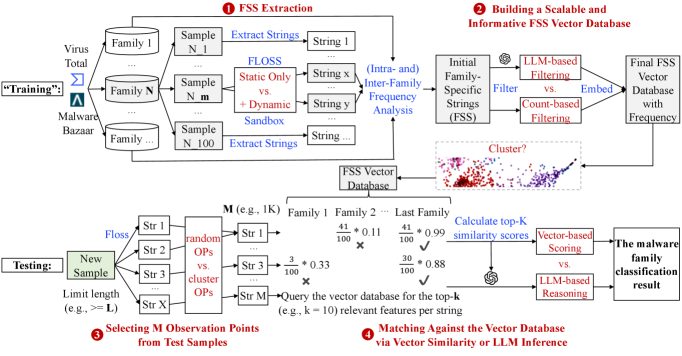
技术框架:该方法包含四个主要模块:1) 字符串提取:从恶意软件样本中提取字符串特征;2) 家族特定字符串(FSS)识别:识别与特定恶意软件家族相关的字符串;3) 检索:根据提取的字符串特征,从恶意软件家族知识库中检索相关家族信息;4) 分类:利用LLM和检索到的信息,对恶意软件样本进行家族分类。
关键创新:该方法的关键创新在于将RAG的思想引入到恶意软件家族分类中。通过检索与样本相关的家族信息,可以有效地增强LLM的分类能力。此外,该方法还提出了一种新的家族特定字符串(FSS)识别方法,可以更准确地识别与特定家族相关的字符串。
关键设计:论文中涉及的关键设计包括:1) 如何有效地提取和表示字符串特征;2) 如何构建恶意软件家族知识库;3) 如何设计检索算法,以快速准确地检索相关家族信息;4) 如何将检索到的信息融入到LLM中,以提高分类性能。具体的参数设置、损失函数、网络结构等技术细节在论文中进行了详细描述(未知)。
🖼️ 关键图片
📊 实验亮点
论文构建了一个包含4,347个样本和67个恶意软件家族的评估框架,并提取和分析了超过2500万个字符串。消融实验结果表明,各个模块的改进分别带来了8.1%到120%的相对性能提升,验证了该方法的有效性。这些结果表明,结合LLM和RAG的字符串特征在恶意软件家族分类中具有巨大的潜力。
🎯 应用场景
该研究成果可应用于自动化恶意软件分析平台,例如VirusTotal和MalwareBazaar,以提高恶意软件样本的自动标记和分类效率。准确的家族分类有助于安全研究人员更好地理解恶意软件的行为和演变趋势,从而开发更有效的防御策略。此外,该方法还可以应用于威胁情报分析和恶意软件溯源等领域。
📄 摘要(原文)
Malware family classification aims to identify the specific family (e.g., GuLoader or BitRAT) a malware sample may belong to, in contrast to malware detection or sample classification, which only predicts a Yes/No outcome. Accurate family identification can greatly facilitate automated sample labeling and understanding on crowdsourced malware analysis platforms such as VirusTotal and MalwareBazaar, which generate vast amounts of data daily. In this paper, we explore and assess the feasibility of using traditional binary string features for family classification in the new era of large language models (LLMs) and Retrieval-Augmented Generation (RAG). Specifically, we investigate howFamily-Specific String (FSS) features can be utilized in a manner similar to RAG to facilitate family classification. To this end, we develop a curated evaluation framework covering 4,347 samples from 67 malware families, extract and analyze over 25 million strings, and conduct detailed ablation studies to assess the impact of different design choices in four major modules, with each providing a relative improvement ranging from 8.1% to 120%.