Disambiguation-Centric Finetuning Makes Enterprise Tool-Calling LLMs More Realistic and Less Risky
作者: Ashutosh Hathidara, Julien Yu, Sebastian Schreiber
分类: cs.AI, cs.CL, cs.LG
发布日期: 2025-07-04 (更新: 2025-10-09)
💡 一句话要点
DiaFORGE微调框架提升企业工具调用LLM的真实性和安全性
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 工具调用 大型语言模型 微调 企业API 消歧义
📋 核心要点
- 现有LLM在企业API调用中,难以区分相似工具和处理参数不明确的情况,导致调用失败。
- DiaFORGE框架通过合成多轮对话,并进行监督微调,使LLM具备更强的工具消歧能力。
- 实验表明,使用DiaFORGE训练的模型在工具调用成功率上显著优于GPT-4o和Claude-3.5-Sonnet。
📝 摘要(中文)
大型语言模型(LLMs)越来越多地被用于调用企业API,但当近乎重复的工具竞争同一用户意图或所需参数未被充分指定时,它们经常会失败。我们引入了DiaFORGE(Dialogue Framework for Organic Response Generation & Evaluation),这是一个以消除歧义为中心的三阶段流程,它(i)合成角色驱动的多轮对话,其中助手必须区分高度相似的工具,(ii)使用3B-70B参数的推理轨迹对开源模型进行监督微调,以及(iii)通过动态套件评估真实世界的准备情况,该套件在实时代理循环中重新部署每个模型,并报告端到端的目标完成情况以及传统的静态指标。在我们的动态基准DiaBENCH上,使用DiaFORGE训练的模型在优化的提示下,工具调用成功率比GPT-4o提高了27个百分点,比Claude-3.5-Sonnet提高了49个百分点。为了促进进一步的研究,我们发布了一个包含5000个生产级企业API规范的开放语料库,并配有经过严格验证的、以消除歧义为中心的对话,为构建可靠的、企业就绪的工具调用代理提供了一个实用的蓝图。
🔬 方法详解
问题定义:现有的大型语言模型在企业级应用中,尤其是在工具调用方面,面临着歧义性问题。具体来说,当存在多个功能相似的API工具时,模型难以准确判断用户意图并选择正确的工具。此外,当用户提供的参数信息不完整或模糊时,模型也难以进行有效的工具调用。这些问题导致工具调用成功率低,影响了LLM在企业环境中的实际应用价值。
核心思路:论文的核心思路是构建一个以消除歧义为中心的微调框架DiaFORGE。该框架通过生成包含歧义的多轮对话数据,并利用这些数据对LLM进行微调,从而提高模型在复杂场景下的工具调用能力。通过模拟真实世界中可能出现的各种歧义情况,使模型能够更好地理解用户意图,并选择合适的工具和参数。
技术框架:DiaFORGE框架包含三个主要阶段:(1)对话合成阶段:生成包含歧义的多轮对话数据,其中助手需要区分高度相似的工具。(2)监督微调阶段:使用生成的对话数据,对开源LLM进行监督微调,并记录推理过程。(3)动态评估阶段:将微调后的模型部署到实时代理循环中,通过动态基准DiaBENCH评估模型的端到端目标完成情况。
关键创新:该论文的关键创新在于提出了一个以消除歧义为中心的微调框架DiaFORGE,并构建了一个包含5000个生产级企业API规范的开放语料库。与传统的微调方法相比,DiaFORGE更加关注模型在复杂场景下的工具调用能力,通过生成包含歧义的对话数据,使模型能够更好地理解用户意图。
关键设计:在对话合成阶段,论文设计了persona-driven的多轮对话生成方法,模拟真实用户与助手之间的交互过程。在监督微调阶段,论文使用了3B-70B参数的开源模型,并记录了推理过程,以便更好地理解模型的行为。在动态评估阶段,论文构建了DiaBENCH基准,用于评估模型在实时代理循环中的性能。
🖼️ 关键图片

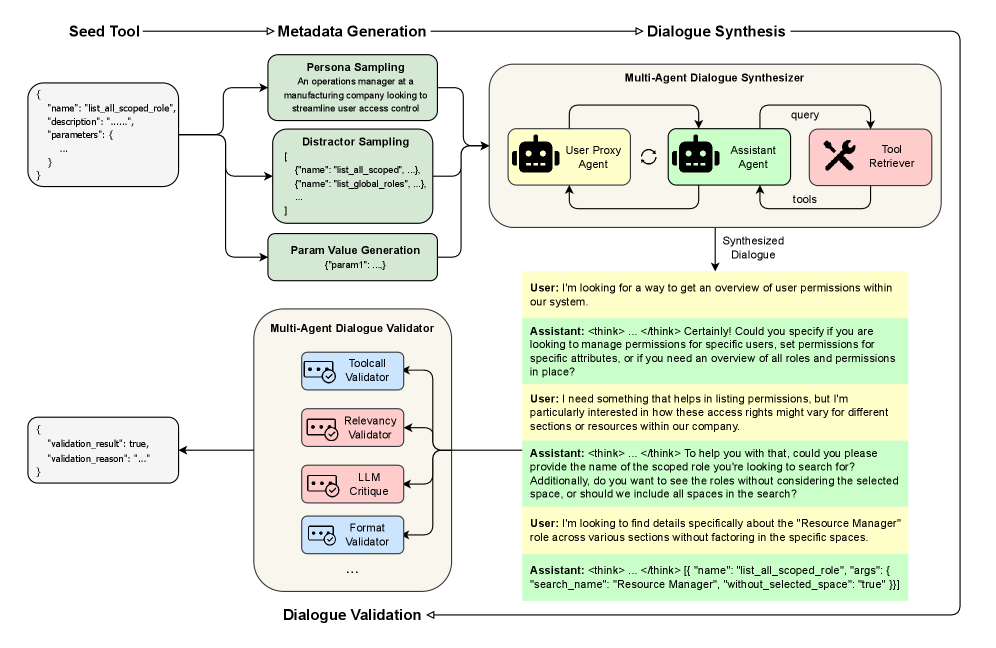

📊 实验亮点
在DiaBENCH动态基准测试中,使用DiaFORGE训练的模型在工具调用成功率上显著优于GPT-4o和Claude-3.5-Sonnet。具体来说,相比于经过优化提示的GPT-4o,成功率提升了27个百分点;相比于Claude-3.5-Sonnet,成功率提升了49个百分点。这些结果表明,DiaFORGE框架能够有效提高LLM在复杂场景下的工具调用能力。
🎯 应用场景
该研究成果可广泛应用于企业级智能助手、自动化流程编排、智能客服等领域。通过提高LLM在工具调用方面的准确性和可靠性,可以显著提升工作效率,降低人工成本,并为用户提供更智能、更便捷的服务。未来,该研究有望推动LLM在企业级应用中的普及和发展。
📄 摘要(原文)
Large language models (LLMs) are increasingly tasked with invoking enterprise APIs, yet they routinely falter when near-duplicate tools vie for the same user intent or when required arguments are left underspecified. We introduce DiaFORGE (Dialogue Framework for Organic Response Generation & Evaluation), a disambiguation-centric, three-stage pipeline that (i) synthesizes persona-driven, multi-turn dialogues in which the assistant must distinguish among highly similar tools, (ii) performs supervised fine-tuning of open-source models with reasoning traces across 3B - 70B parameters, and (iii) evaluates real-world readiness via a dynamic suite that redeploys each model in a live agentic loop and reports end-to-end goal completion alongside conventional static metrics. On our dynamic benchmark DiaBENCH, models trained with DiaFORGE raise tool-invocation success by 27 pp over GPT-4o and by 49 pp over Claude-3.5-Sonnet, both under optimized prompting. To spur further research, we release an open corpus of 5000 production-grade enterprise API specifications paired with rigorously validated, disambiguation-focused dialogues, offering a practical blueprint for building reliable, enterprise-ready tool-calling agents.