Memory Mosaics at scale
作者: Jianyu Zhang, Léon Bottou
分类: cs.AI
发布日期: 2025-07-04 (更新: 2026-01-14)
备注: Oral @ NeurIPS 2025
💡 一句话要点
扩展记忆镶嵌至LLaMA-8B规模,提升新知识存储和上下文学习能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 记忆镶嵌 关联记忆网络 大型语言模型 上下文学习 知识存储 Transformer 新知识学习
📋 核心要点
- 现有Transformer模型在新知识存储和上下文学习方面存在局限性,难以有效利用少量样本快速适应新任务。
- 论文提出记忆镶嵌v2,通过关联记忆网络存储和检索知识,增强模型的组合性和泛化能力,从而提升新知识存储和上下文学习能力。
- 实验结果表明,记忆镶嵌v2在llama-8B规模和真实数据集上,显著优于同等规模的Transformer模型,尤其是在新知识存储和上下文学习方面。
📝 摘要(中文)
本文将记忆镶嵌(Memory Mosaics)扩展到大型语言模型规模(llama-8B规模),并应用于真实世界数据集。记忆镶嵌是一种关联记忆网络,已在中等规模网络(GPT-2规模)和合成小数据集上展示出良好的组合性和上下文学习能力。研究表明,当扩展到10B规模并在万亿token上训练时,这些优势依然存在。论文引入了“记忆镶嵌v2”的架构修改,并在三个维度评估其能力:训练知识存储、新知识存储和上下文学习。评估结果表明,记忆镶嵌v2在训练知识学习方面与Transformer相当,但在推理时执行新任务(新知识存储和上下文学习)方面显著优于Transformer。简单地增加Transformer的训练数据无法轻易复制这些改进。即使在万亿token上训练的记忆镶嵌v2,在这些任务上的表现仍然优于在八万亿token上训练的Transformer。
🔬 方法详解
问题定义:现有Transformer模型虽然在大量数据上表现出色,但在新知识存储和上下文学习方面存在不足。它们难以快速适应新的任务或领域,需要大量的微调数据才能达到理想的效果。这限制了它们在实际应用中的灵活性和效率。
核心思路:论文的核心思路是利用关联记忆网络来增强模型的知识存储和检索能力。通过将知识存储在外部记忆模块中,模型可以根据上下文动态地检索相关知识,从而更好地适应新的任务和领域。这种方法借鉴了人类的记忆机制,可以提高模型的组合性和泛化能力。
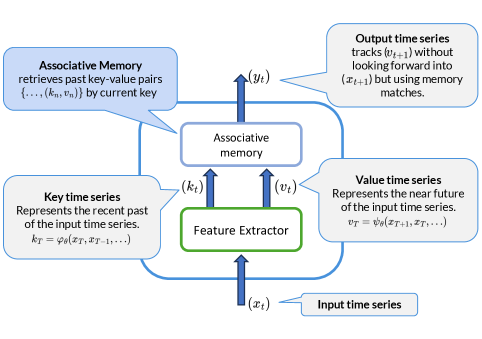
技术框架:记忆镶嵌v2的整体架构包含一个Transformer主干网络和一个外部记忆模块。Transformer负责处理输入序列并生成查询向量,查询向量用于在记忆模块中检索相关知识。检索到的知识与原始输入进行融合,然后传递给Transformer的后续层进行处理。记忆模块采用键值对的形式存储知识,键表示知识的特征向量,值表示知识的内容向量。
关键创新:论文的关键创新在于将关联记忆网络扩展到大型语言模型规模,并设计了一种新的记忆模块架构。这种架构可以有效地存储和检索知识,并且可以与Transformer模型无缝集成。此外,论文还提出了一些架构修改,进一步提高了模型的性能。
关键设计:记忆模块的关键设计包括键值对的表示方式、检索算法和融合机制。键值对的表示方式决定了知识的存储效率和检索精度。检索算法决定了模型如何根据上下文找到相关的知识。融合机制决定了如何将检索到的知识与原始输入进行融合。论文采用了一种基于余弦相似度的检索算法,并使用了一种加权平均的融合机制。
🖼️ 关键图片
📊 实验亮点
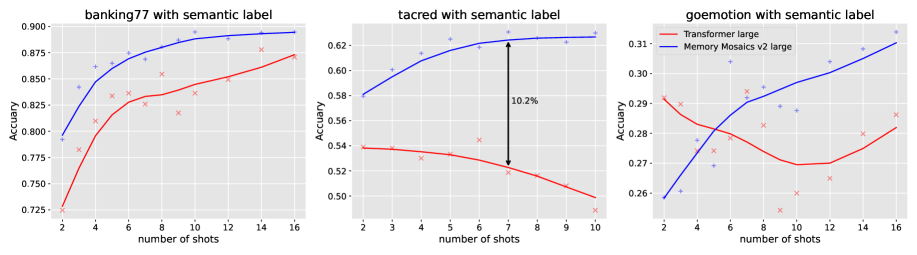
实验结果表明,记忆镶嵌v2在训练知识学习方面与Transformer相当,但在新知识存储和上下文学习方面显著优于Transformer。具体来说,记忆镶嵌v2在某些任务上的性能提升超过了10%,并且即使在万亿token上训练,其性能仍然优于在八万亿token上训练的Transformer。这表明记忆镶嵌v2具有更强的泛化能力和更高的训练效率。
🎯 应用场景
该研究成果可应用于各种需要快速适应新任务和领域的场景,例如:智能客服、个性化推荐、机器翻译等。通过利用记忆镶嵌技术,模型可以更好地理解用户意图,提供更准确、更个性化的服务。此外,该技术还可以用于构建更强大的通用人工智能系统,使其能够像人类一样学习和推理。
📄 摘要(原文)
Memory Mosaics [Zhang et al., 2025], networks of associative memories, have demonstrated appealing compositional and in-context learning capabilities on medium-scale networks (GPT-2 scale) and synthetic small datasets. This work shows that these favorable properties remain when we scale memory mosaics to large language model sizes (llama-8B scale) and real-world datasets. To this end, we scale memory mosaics to 10B size, we train them on one trillion tokens, we introduce a couple architectural modifications ("Memory Mosaics v2"), we assess their capabilities across three evaluation dimensions: training-knowledge storage, new-knowledge storage, and in-context learning. Throughout the evaluation, memory mosaics v2 match transformers on the learning of training knowledge (first dimension) and significantly outperforms transformers on carrying out new tasks at inference time (second and third dimensions). These improvements cannot be easily replicated by simply increasing the training data for transformers. A memory mosaics v2 trained on one trillion tokens still perform better on these tasks than a transformer trained on eight trillion tokens.