Towards Practical GraphRAG: Efficient Knowledge Graph Construction and Hybrid Retrieval at Scale
作者: Congmin Min, Sahil Bansal, Joyce Pan, Abbas Keshavarzi, Rhea Mathew, Amar Viswanathan Kannan
分类: cs.AI
发布日期: 2025-07-04 (更新: 2025-12-18)
💡 一句话要点
提出高效GraphRAG框架,通过低成本知识图谱构建和混合检索,提升企业级应用性能。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: GraphRAG 知识图谱 检索增强生成 依赖解析 混合检索 向量检索 企业应用
📋 核心要点
- 现有GraphRAG依赖昂贵的LLM提取和复杂遍历策略,限制了其在企业环境中的应用。
- 提出一种高效知识图谱构建流程,利用依赖解析降低成本,并结合混合检索策略提升性能。
- 实验表明,该框架在企业数据集上优于传统向量检索,验证了GraphRAG在实际应用中的可行性。
📝 摘要(中文)
本文提出了一种可扩展且经济高效的框架,用于在企业环境中部署基于图的检索增强生成(GraphRAG)。尽管GraphRAG在多跳推理和结构化检索方面显示出潜力,但由于依赖昂贵的大型语言模型(LLM)提取和复杂的遍历策略,其应用受到限制。为了解决这些挑战,我们引入了两项核心创新:(1) 一种高效的知识图谱构建流程,利用依赖解析达到LLM性能的94%(61.87% vs. 65.83%),同时显著降低成本并提高可扩展性;(2) 一种混合检索策略,使用倒数排名融合(RRF)将向量相似性与图遍历融合,为实体、块和关系维护单独的嵌入,以实现多粒度匹配。我们在两个专注于遗留代码迁移的企业数据集上评估了我们的框架,并证明使用LLM-as-Judge评估指标,性能比原始向量检索基线提高了高达15%和4.35%。这些结果验证了在生产企业环境中部署GraphRAG的可行性,表明精心设计的经典NLP技术可以与现代基于LLM的方法相媲美,同时实现实用、经济高效且可领域自适应的大规模检索增强推理。
🔬 方法详解
问题定义:现有GraphRAG方法依赖于昂贵的LLM进行知识抽取,并且图遍历策略复杂,导致在企业级应用中成本高昂且难以扩展。传统向量检索方法缺乏结构化知识的利用,难以进行多跳推理。
核心思路:本文的核心思路是利用低成本的依赖解析技术构建知识图谱,并结合混合检索策略,将向量相似度检索和图遍历相结合,从而在保证性能的同时,降低成本并提高可扩展性。通过维护实体、块和关系的不同嵌入,实现多粒度匹配。
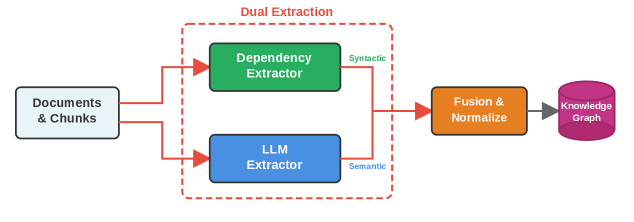
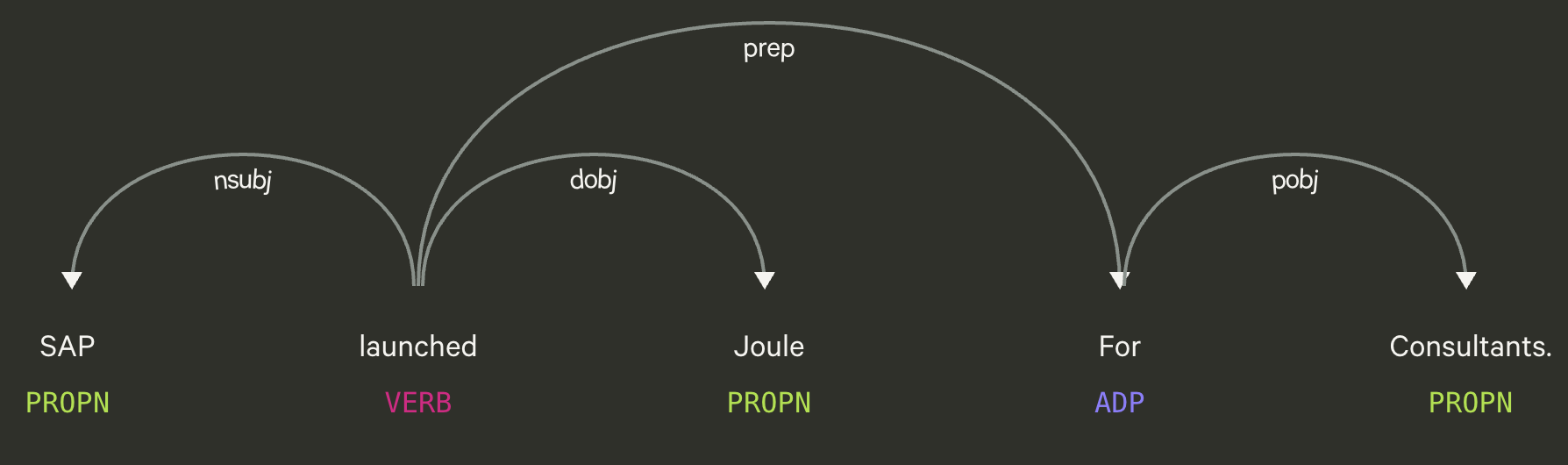
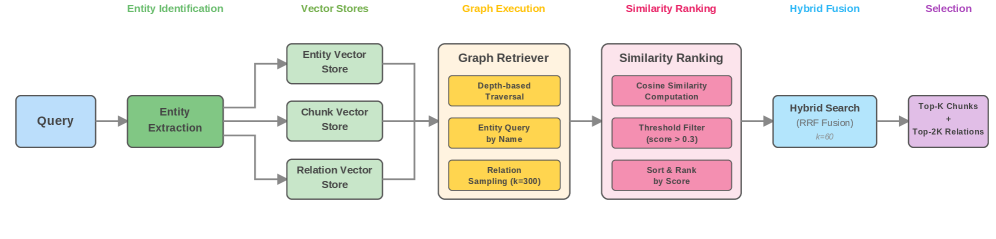
技术框架:该框架包含两个主要阶段:知识图谱构建和混合检索。知识图谱构建阶段,首先使用依赖解析技术从文本中提取实体和关系,构建知识图谱。混合检索阶段,首先使用向量相似度检索召回候选结果,然后利用图遍历在知识图谱中进行多跳推理,最后使用倒数排名融合(RRF)将两种检索结果融合。
关键创新:最重要的技术创新点在于使用依赖解析替代昂贵的LLM进行知识图谱构建,以及提出了一种混合检索策略,将向量检索和图遍历相结合。这种方法在保证性能的同时,显著降低了成本,提高了可扩展性。
关键设计:在知识图谱构建阶段,使用预训练的依赖解析器进行实体和关系抽取。在混合检索阶段,为实体、块和关系分别训练独立的嵌入向量。倒数排名融合(RRF)使用超参数k来控制不同检索结果的权重,需要根据具体数据集进行调整。
🖼️ 关键图片
📊 实验亮点
实验结果表明,该框架在遗留代码迁移数据集上,使用LLM-as-Judge评估指标,相比于传统向量检索基线,性能提升高达15%和4.35%。同时,该框架使用依赖解析构建知识图谱,达到了LLM方法94%的性能,显著降低了成本。
🎯 应用场景
该研究成果可广泛应用于企业知识管理、智能客服、代码迁移等领域。通过构建领域知识图谱,可以提升信息检索的准确性和效率,支持复杂问题的推理和决策,降低企业运营成本,并加速数字化转型。
📄 摘要(原文)
We propose a scalable and cost-efficient framework for deploying Graph-based Retrieval-Augmented Generation (GraphRAG) in enterprise environments. While GraphRAG has shown promise for multi- hop reasoning and structured retrieval, its adoption has been limited due to reliance on expensive large language model (LLM)-based extraction and complex traversal strategies. To address these challenges, we introduce two core innovations: (1) an efficient knowledge graph construction pipeline that leverages dependency parsing to achieve 94% of LLM-based performance (61.87% vs. 65.83%) while significantly reducing costs and improving scalability; and (2) a hybrid retrieval strategy that fuses vector similarity with graph traversal using Reciprocal Rank Fusion (RRF), maintaining separate embeddings for entities, chunks, and relations to enable multi-granular matching. We evaluate our framework on two enterprise datasets focused on legacy code migration and demonstrate improvements of up to 15% and 4.35% over vanilla vector retrieval baselines using LLM-as-Judge evaluation metrics. These results validate the feasibility of deploying GraphRAG in production enterprise environments, demonstrating that careful engineering of classical NLP techniques can match modern LLM-based approaches while enabling practical, cost-effective, and domain-adaptable retrieval-augmented reasoning at scale.