Symbiosis: Multi-Adapter Inference and Fine-Tuning
作者: Saransh Gupta, Umesh Deshpande, Travis Janssen, Swami Sundararaman
分类: cs.DC, cs.AI, cs.LG
发布日期: 2025-07-03 (更新: 2025-10-23)
💡 一句话要点
Symbiosis:多适配器推理与微调框架,解决资源管理和隐私问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 参数高效微调 多适配器 资源管理 隐私保护 分离执行 大型语言模型 GPU利用率
📋 核心要点
- 现有PEFT框架在多适配器场景下存在GPU资源浪费、缺乏灵活的资源管理和异构加速器支持等问题。
- Symbiosis通过分离执行技术,将基础模型层作为服务共享,客户端独立管理适配器资源和选择微调方法。
- 实验证明Symbiosis能够高效地同时微调多个适配器,例如在8个GPU上同时微调20个Gemma2-27B适配器。
📝 摘要(中文)
参数高效微调(PEFT)允许模型构建者将特定于任务的参数捕获到适配器中,这些适配器的大小仅为原始基础模型的一小部分。PEFT微调技术的普及导致了大量流行的大型语言模型(LLM)适配器的创建。然而,现有的框架在以下方面不足以支持使用多个适配器进行推理或微调:1) 对于微调,每个作业都需要部署其专用的基础模型实例,这导致过度的GPU内存消耗和较差的GPU利用率。2) 虽然流行的推理平台可以服务于多个PEFT适配器,但它们不允许独立的资源管理或混合不同的PEFT方法。3) 它们无法有效利用异构加速器。4) 它们不向可能不希望将其微调参数暴露给服务提供商的用户提供隐私。在Symbiosis中,我们通过启用基础模型的即服务部署来解决上述问题。基础模型层可以在多个推理或微调过程中共享。我们的分离执行技术将客户端特定的适配器和层的执行与冻结的基础模型层分离,从而为他们提供管理其资源、选择其微调方法以及实现其性能目标的灵活性。我们的方法对模型是透明的,并且可以开箱即用地用于transformers库中的大多数模型。我们展示了使用Symbiosis在8个GPU上同时微调20个Gemma2-27B适配器。
🔬 方法详解
问题定义:现有参数高效微调(PEFT)框架在处理多个适配器时,面临着GPU资源利用率低、缺乏灵活的资源管理以及无法有效利用异构加速器等问题。此外,用户可能不希望将其微调后的参数暴露给服务提供商,存在隐私方面的担忧。这些问题限制了PEFT技术在实际应用中的扩展性。
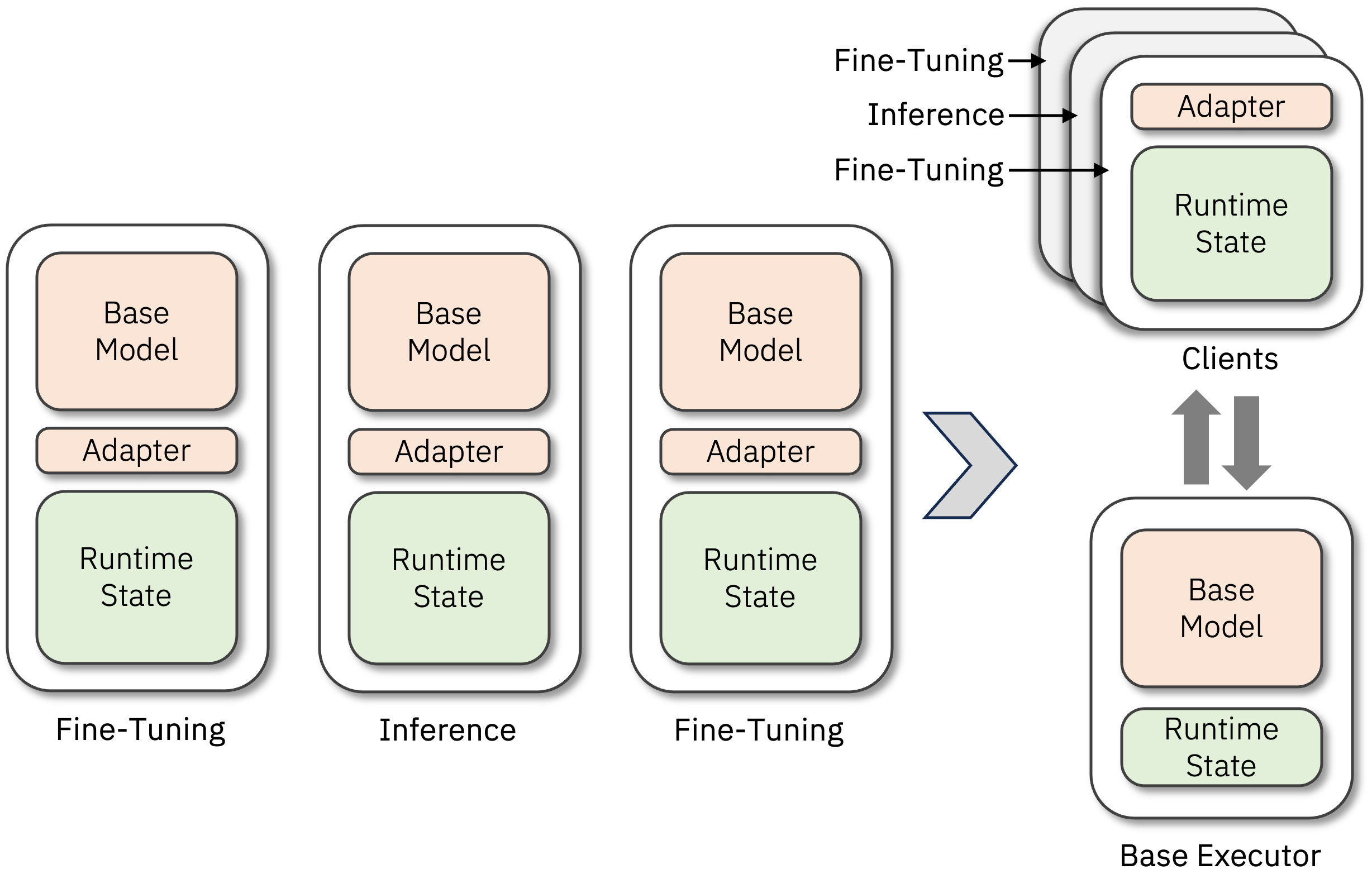
核心思路:Symbiosis的核心思路是将基础模型层作为一种服务进行部署,允许多个推理或微调过程共享这些基础模型层。通过分离执行技术,将客户端特定的适配器和层的执行与冻结的基础模型层解耦,从而实现客户端对资源、微调方法和性能目标的独立管理。
技术框架:Symbiosis采用了一种分离执行的架构。基础模型层被部署为共享服务,而客户端则负责管理和执行其自身的适配器和特定层。这种架构允许客户端根据自身的需求选择合适的微调方法和资源配置。整体流程包括:基础模型服务部署、客户端适配器加载与执行、以及结果的整合。
关键创新:Symbiosis的关键创新在于其分离执行技术,它将基础模型层与客户端特定的适配器层解耦。这种解耦使得资源管理更加灵活,允许客户端独立选择微调方法,并保护了客户端的隐私。此外,该方法对模型是透明的,可以开箱即用地用于transformers库中的大多数模型。
关键设计:Symbiosis的关键设计包括:1) 基础模型服务的部署方式,需要保证高效的共享和访问;2) 适配器层的加载和执行机制,需要与基础模型服务无缝集成;3) 资源管理策略,需要支持客户端的独立资源配置;4) 隐私保护机制,例如差分隐私或联邦学习等(论文中未明确提及,但可以作为未来方向)。具体的参数设置、损失函数、网络结构等技术细节取决于所使用的PEFT方法和基础模型。
🖼️ 关键图片


📊 实验亮点
实验结果表明,Symbiosis能够在8个GPU上同时微调20个Gemma2-27B适配器,证明了其高效的资源利用率和可扩展性。该框架对模型透明,可以开箱即用地用于transformers库中的大多数模型,降低了使用门槛。
🎯 应用场景
Symbiosis适用于需要同时微调或推理多个适配器的场景,例如多任务学习、个性化推荐、以及需要保护用户隐私的联邦学习等。该框架可以提高GPU资源的利用率,降低部署成本,并为用户提供更灵活的资源管理和隐私保护。
📄 摘要(原文)
Parameter-efficient fine-tuning (PEFT) allows model builders to capture the task-specific parameters into adapters, which are a fraction of the size of the original base model. Popularity of PEFT technique for fine-tuning has led to the creation of a large number of adapters for popular Large Language Models (LLMs). However, existing frameworks fall short in supporting inference or fine-tuning with multiple adapters in the following ways. 1) For fine-tuning, each job needs to deploy its dedicated base model instance, which results in excessive GPU memory consumption and poor GPU utilization. 2) While popular inference platforms can serve multiple PEFT adapters, they do not allow independent resource management or mixing of different PEFT methods. 3) They cannot make effective use of heterogeneous accelerators. 4) They do not provide privacy to users who may not wish to expose their fine-tuned parameters to service providers. In Symbiosis, we address the above problems by enabling the as-a-service deployment of the base model. The base model layers can be shared across multiple inference or fine-tuning processes. Our split-execution technique decouples the execution of client-specific adapters and layers from the frozen base model layers offering them flexibility to manage their resources, to select their fine-tuning method, to achieve their performance goals. Our approach is transparent to models and works out-of-the-box for most models in the transformers library. We demonstrate the use of Symbiosis to simultaneously fine-tune 20 Gemma2-27B adapters on 8 GPUs.