FlowSpec: Continuous Pipelined Speculative Decoding for Efficient Distributed LLM Inference
作者: Xing Liu, Lizhuo Luo, Ming Tang, Chao Huang, Xu Chen
分类: cs.DC, cs.AI
发布日期: 2025-07-03 (更新: 2026-01-10)
备注: 11 pages, and the last one is the appendix
🔗 代码/项目: GITHUB
💡 一句话要点
FlowSpec:面向高效分布式LLM推理的连续流水线式推测解码框架
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 分布式推理 大型语言模型 推测解码 流水线并行 边缘计算
📋 核心要点
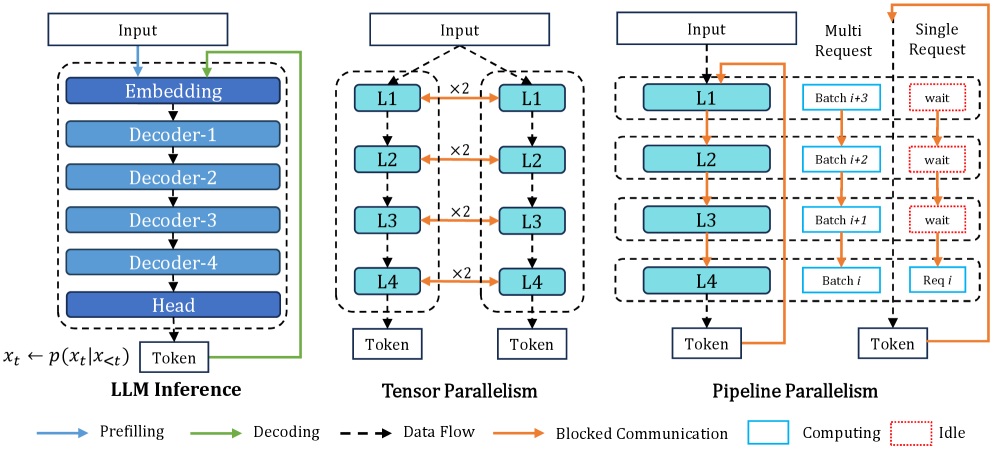
- 现有流水线并行方法在边缘设备上进行分布式LLM推理时,面临请求稀疏导致流水线利用率低的挑战。
- FlowSpec通过基于分数的验证、高效草稿管理和动态草稿扩展,提升流水线利用率和推测解码效率。
- 实验表明,FlowSpec在多种模型和配置下,相比基线方法实现了1.37倍到1.73倍的推理速度提升。
📝 摘要(中文)
本文提出FlowSpec,一个基于流水线并行和树状结构的推测解码框架,旨在提升网络边缘分布式大型语言模型(LLM)推理的效率。FlowSpec包含三个关键机制以提高解码效率:1) 基于分数的逐步验证,优先验证更重要的草稿token,以尽早获得接受的token;2) 高效的草稿管理,在验证期间剪枝无效token,同时保持正确的因果关系;3) 动态草稿扩展策略,提供高质量的推测输入。这些技术协同工作,以提高流水线利用率和推测效率。在真实测试平台上,FlowSpec与其他基线方法进行了评估。实验结果表明,所提出的框架显著提高了各种模型和配置的推理速度,与基线相比,实现了1.37倍-1.73倍的加速。代码已公开。
🔬 方法详解
问题定义:论文旨在解决在网络边缘进行分布式LLM推理时,由于推理请求的稀疏性导致流水线并行利用率低下的问题。现有的流水线方法在请求稀疏时,计算资源无法充分利用,导致推理延迟增加。
核心思路:FlowSpec的核心思路是利用推测解码,通过生成多个草稿token并并行验证,来提高流水线的利用率。同时,通过优化草稿token的选择和管理,提高推测的准确性和效率,从而减少无效计算。
技术框架:FlowSpec采用流水线并行的树状结构。整体流程包括:1) 初始token生成;2) 基于动态草稿扩展策略生成多个草稿token;3) 基于分数的逐步验证,对草稿token进行优先级排序和验证;4) 高效草稿管理,剪枝无效token并维护因果关系;5) 将接受的token加入序列,并重复上述过程。
关键创新:FlowSpec的关键创新在于三个方面:1) 基于分数的逐步验证,优先验证重要的token,加速token接受;2) 高效草稿管理,保证验证过程中的因果关系正确性;3) 动态草稿扩展策略,生成高质量的推测输入,提高推测解码的效率。与传统推测解码方法相比,FlowSpec更注重流水线利用率和草稿token的质量。
关键设计:FlowSpec的关键设计包括:1) 使用token的概率分数作为验证优先级,优先验证高概率token;2) 设计了剪枝策略,在验证过程中移除无效的草稿token,减少计算量;3) 动态草稿扩展策略,根据历史接受率调整草稿token的数量和质量,以适应不同的模型和数据。
🖼️ 关键图片


📊 实验亮点
实验结果表明,FlowSpec在真实测试平台上,相比于基线方法,实现了1.37倍到1.73倍的推理速度提升。这一显著的加速效果验证了FlowSpec在提高分布式LLM推理效率方面的有效性,尤其是在边缘计算场景下具有重要意义。
🎯 应用场景
FlowSpec适用于需要在网络边缘设备上进行低延迟LLM推理的场景,例如智能助手、实时翻译、内容生成等。该研究成果有助于在资源受限的边缘设备上部署大型语言模型,实现更快速、更高效的AI服务,并推动边缘计算和人工智能的融合。
📄 摘要(原文)
Distributed inference serves as a promising approach to enabling the inference of large language models (LLMs) at the network edge. It distributes the inference process to multiple devices to ensure that the LLMs can fit into the device memory. Recent pipeline-based approaches have the potential to parallelize communication and computation, which helps reduce inference latency. However, the benefit diminishes when the inference request at the network edge is sparse, where pipeline is typically at low utilization. To enable efficient distributed LLM inference at the edge, we propose \textbf{FlowSpec}, a pipeline-parallel tree-based speculative decoding framework. FlowSpec incorporates three key mechanisms to improve decoding efficiency: 1) score-based step-wise verification prioritizes more important draft tokens to bring earlier accepted tokens; 2) efficient draft management to prune invalid tokens while maintaining correct causal relationship during verification; 3) dynamic draft expansion strategies to supply high-quality speculative inputs. These techniques work in concert to enhance both pipeline utilization and speculative efficiency. We evaluate FlowSpec on a real-world testbed with other baselines. Experimental results demonstrate that our proposed framework significantly improves inference speed across diverse models and configurations, achieving speedup ratios 1.37$\times$-1.73$\times$ compared to baselines. Our code is publicly available at \href{https://github.com/Leosang-lx/FlowSpec#}{https://github.com/Leosang-lx/FlowSpec#}.