Strategic Intelligence in Large Language Models: Evidence from evolutionary Game Theory
作者: Kenneth Payne, Baptiste Alloui-Cros
分类: cs.AI, cs.CL, cs.GT
发布日期: 2025-07-03
备注: 29 pages, 27 tables, 4 figures
💡 一句话要点
利用演化博弈论评估大型语言模型的战略智能水平
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 战略智能 演化博弈论 迭代囚徒困境 决策推理
📋 核心要点
- 现有方法难以评估LLM在复杂竞争环境下的战略决策能力,缺乏有效手段分析其行为模式。
- 论文采用演化博弈论,通过迭代囚徒困境模拟竞争环境,考察LLM的战略选择和适应性。
- 实验结果表明,LLM在演化博弈中表现出不同的战略倾向,并能根据环境调整策略,具备一定的战略智能。
📝 摘要(中文)
本文旨在评估大型语言模型(LLMs)是否具备战略智能,即在竞争环境中进行目标推理的能力。研究者通过演化迭代囚徒困境(IPD)锦标赛,将经典策略(如针锋相对、冷酷到底)与来自OpenAI、Google和Anthropic等领先AI公司的智能体进行对抗。通过改变每次锦标赛的终止概率(即“未来阴影”),引入复杂性和随机性,以避免模型记忆。结果表明,LLMs具有高度竞争力,能够在复杂的生态系统中生存甚至繁荣。它们表现出独特的“战略指纹”:Google的Gemini模型在战略上表现出无情,利用合作对手并报复背叛者,而OpenAI的模型保持高度合作,但在充满敌意的环境中却遭遇灾难。Anthropic的Claude成为最具宽恕心的互惠者,即使在被利用或成功背叛后,也表现出恢复合作的意愿。对模型提供的近32,000条文本理由的分析表明,它们会积极推理时间范围和对手的可能策略,并且这种推理对它们的决策至关重要。这项工作将经典博弈论与机器心理学联系起来,提供了对不确定性下算法决策的丰富而细致的视角。
🔬 方法详解
问题定义:论文旨在评估大型语言模型(LLMs)是否具备战略智能,即在竞争环境中进行目标推理的能力。现有方法难以有效评估LLM在复杂、动态的博弈环境下的决策能力,并且难以区分模型是简单记忆还是真正具备战略推理能力。
核心思路:论文的核心思路是将LLM置于演化博弈论的框架下,通过迭代囚徒困境(IPD)模拟竞争环境,观察LLM在不同策略下的表现和适应性。通过引入终止概率(“未来阴影”),增加博弈的复杂性和不确定性,从而避免模型简单地记忆策略。
技术框架:整体框架包括以下几个主要阶段:1) 构建演化IPD锦标赛环境,其中包含经典博弈策略(如Tit-for-Tat, Grim Trigger)和来自不同AI公司的LLM智能体。2) 设置不同的终止概率,控制“未来阴影”的长度。3) 让LLM智能体进行多轮博弈,记录其决策和提供的文本理由。4) 分析LLM智能体的生存率、策略选择和文本理由,评估其战略智能水平。
关键创新:论文的关键创新在于:1) 将演化博弈论引入LLM的战略智能评估,提供了一种新的评估方法。2) 通过分析LLM提供的文本理由,深入了解其决策过程和推理逻辑。3) 揭示了不同LLM在战略上的差异,例如Google的Gemini模型表现出更强的竞争性,而OpenAI的模型更倾向于合作。
关键设计:关键设计包括:1) 终止概率的设置,用于控制博弈的长度和不确定性。2) 文本理由的收集和分析,用于理解LLM的决策过程。3) 演化锦标赛的设置,用于评估LLM在不同策略下的适应性。具体参数设置未知,论文中可能未详细公开。
🖼️ 关键图片


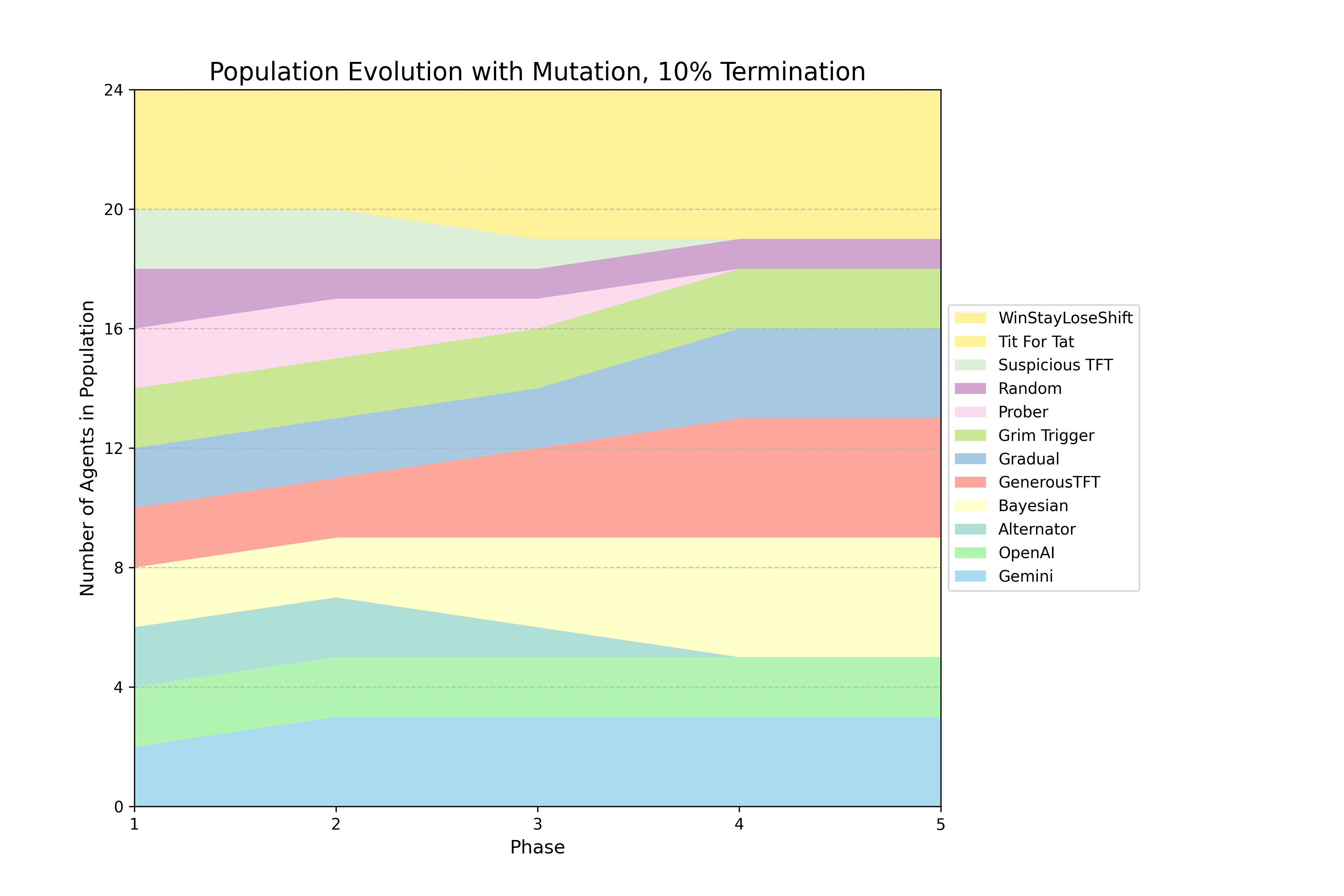
📊 实验亮点
实验结果表明,LLM在演化IPD锦标赛中表现出高度竞争力,能够在复杂的生态系统中生存甚至繁荣。不同LLM表现出不同的战略倾向:Google的Gemini模型更具竞争性,OpenAI的模型更倾向于合作,Anthropic的Claude则表现出更强的互惠性。对近32,000条文本理由的分析表明,LLM能够主动推理时间范围和对手策略,并将其用于决策。
🎯 应用场景
该研究成果可应用于评估和提升AI系统的战略决策能力,尤其是在涉及竞争、合作和不确定性的场景中,例如自动驾驶、金融交易、资源分配等。通过了解不同AI模型的战略倾向,可以更好地设计和部署AI系统,以实现更优的性能和安全性。此外,该研究也为理解机器心理学和算法决策提供了新的视角。
📄 摘要(原文)
Are Large Language Models (LLMs) a new form of strategic intelligence, able to reason about goals in competitive settings? We present compelling supporting evidence. The Iterated Prisoner's Dilemma (IPD) has long served as a model for studying decision-making. We conduct the first ever series of evolutionary IPD tournaments, pitting canonical strategies (e.g., Tit-for-Tat, Grim Trigger) against agents from the leading frontier AI companies OpenAI, Google, and Anthropic. By varying the termination probability in each tournament (the "shadow of the future"), we introduce complexity and chance, confounding memorisation. Our results show that LLMs are highly competitive, consistently surviving and sometimes even proliferating in these complex ecosystems. Furthermore, they exhibit distinctive and persistent "strategic fingerprints": Google's Gemini models proved strategically ruthless, exploiting cooperative opponents and retaliating against defectors, while OpenAI's models remained highly cooperative, a trait that proved catastrophic in hostile environments. Anthropic's Claude emerged as the most forgiving reciprocator, showing remarkable willingness to restore cooperation even after being exploited or successfully defecting. Analysis of nearly 32,000 prose rationales provided by the models reveals that they actively reason about both the time horizon and their opponent's likely strategy, and we demonstrate that this reasoning is instrumental to their decisions. This work connects classic game theory with machine psychology, offering a rich and granular view of algorithmic decision-making under uncertainty.