Content filtering methods for music recommendation: A review
作者: Terence Zeng, Abhishek K. Umrawal
分类: cs.IR, cs.AI, cs.LG
发布日期: 2025-07-03
备注: 13 pages and 9 figures
💡 一句话要点
综述:面向音乐推荐的内容过滤方法,解决交互稀疏性问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 音乐推荐 内容过滤 协同过滤 数据稀疏性 歌词分析 音频信号处理 大型语言模型 歌曲分类
📋 核心要点
- 协同过滤在音乐推荐中面临数据稀疏性挑战,用户与大部分音乐交互很少,导致推荐效果不佳。
- 论文综述了内容过滤方法在音乐推荐中的应用,旨在缓解协同过滤的偏差,提升推荐系统的性能。
- 研究考察了基于歌词分析(LLM)和音频信号处理的歌曲分类方法,并探讨了不同方法间的潜在冲突及解决方案。
📝 摘要(中文)
推荐系统在现代音乐流媒体平台中至关重要,影响着用户发现和欣赏音乐的方式。协同过滤是一种常见的推荐方法,它基于与目标用户具有相似收听模式的用户的偏好来推荐内容。然而,这种方法在交互稀疏的媒体上效果较差。音乐就是这样一种媒介,因为音乐流媒体服务的普通用户永远不会收听绝大多数曲目。由于这种稀疏性,必须使用其他方法来解决一些挑战。本综述考察了当前解决这些挑战的研究现状,重点关注内容过滤在减轻协同过滤方法中固有的偏差方面的作用。我们探讨了各种用于内容过滤的歌曲分类方法,包括使用大型语言模型 (LLM) 的歌词分析和音频信号处理技术。此外,我们还讨论了这些不同的分析方法之间可能存在的冲突,并提出了解决此类差异的途径。
🔬 方法详解
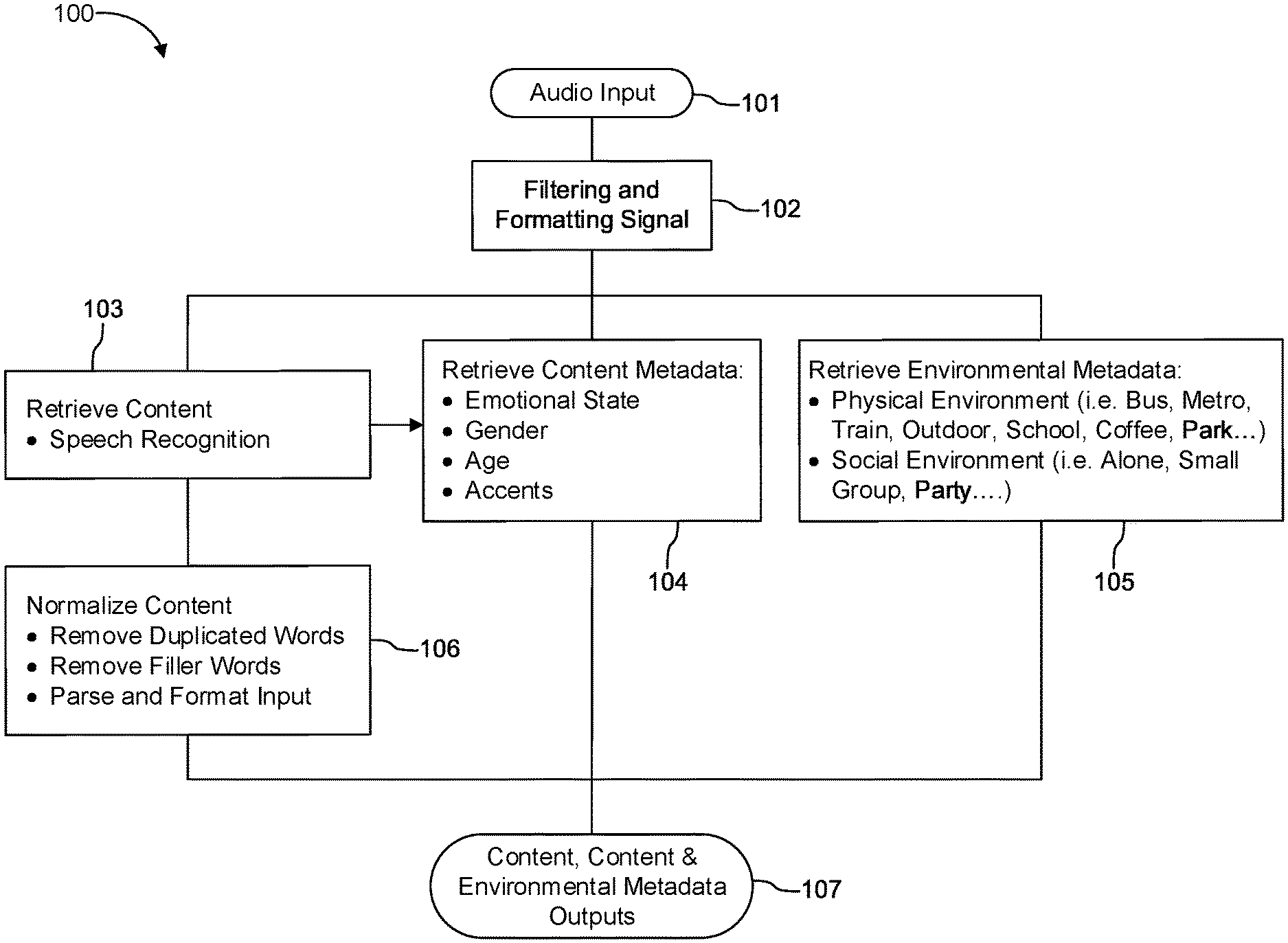
问题定义:音乐推荐系统面临用户交互数据稀疏性的问题。传统的协同过滤方法依赖于用户-歌曲的交互历史,但在音乐领域,用户通常只听过极少一部分歌曲,导致协同过滤难以找到相似用户或歌曲,推荐效果下降。因此,需要利用歌曲的内容信息来弥补交互数据的不足。
核心思路:论文的核心思路是利用内容过滤方法,通过分析歌曲的内在属性(如歌词、音频信号)来理解歌曲的特征,从而进行推荐。这种方法不依赖于用户交互数据,可以有效解决数据稀疏性问题,并能发现用户可能感兴趣但未曾听过的歌曲。
技术框架:该综述考察了两种主要的内容过滤技术:1) 基于歌词分析的方法,利用大型语言模型(LLM)对歌词进行语义分析,提取歌曲的主题、情感等信息;2) 基于音频信号处理的方法,分析歌曲的音频特征,如音调、节奏、乐器等。整体框架包括数据预处理、特征提取、歌曲分类和推荐四个阶段。
关键创新:该综述的关键创新在于整合了基于歌词和音频的多种内容过滤方法,并探讨了这些方法之间的潜在冲突和解决方案。传统的音乐推荐系统通常只采用单一的内容特征,而该综述强调了多模态融合的重要性,并提出了解决不同模态信息冲突的思路。
关键设计:在歌词分析方面,可以使用预训练的LLM模型,如BERT、GPT等,对歌词进行fine-tuning,以提取更准确的语义信息。在音频信号处理方面,可以使用MFCC、频谱图等特征,并结合深度学习模型(如CNN、RNN)进行特征提取和分类。关键设计还包括如何融合歌词和音频特征,以及如何设计损失函数来优化模型。
🖼️ 关键图片
📊 实验亮点
该综述总结了当前音乐推荐领域内容过滤方法的研究进展,重点分析了基于歌词和音频的歌曲分类技术。论文指出了不同内容分析方法之间可能存在的冲突,并为解决这些冲突提供了思路。虽然没有提供具体的实验数据,但该综述为未来的研究方向提供了有价值的指导。
🎯 应用场景
该研究成果可应用于各种音乐流媒体平台,例如Spotify、Apple Music等,以提升音乐推荐的准确性和多样性。通过内容过滤,可以更好地发现用户的潜在兴趣,并推荐他们可能喜欢的冷门歌曲,从而提高用户满意度和平台活跃度。此外,该方法还可以应用于音乐创作、音乐版权管理等领域。
📄 摘要(原文)
Recommendation systems have become essential in modern music streaming platforms, shaping how users discover and engage with songs. One common approach in recommendation systems is collaborative filtering, which suggests content based on the preferences of users with similar listening patterns to the target user. However, this method is less effective on media where interactions are sparse. Music is one such medium, since the average user of a music streaming service will never listen to the vast majority of tracks. Due to this sparsity, there are several challenges that have to be addressed with other methods. This review examines the current state of research in addressing these challenges, with an emphasis on the role of content filtering in mitigating biases inherent in collaborative filtering approaches. We explore various methods of song classification for content filtering, including lyrical analysis using Large Language Models (LLMs) and audio signal processing techniques. Additionally, we discuss the potential conflicts between these different analysis methods and propose avenues for resolving such discrepancies.