Does Math Reasoning Improve General LLM Capabilities? Understanding Transferability of LLM Reasoning
作者: Maggie Huan, Yuetai Li, Tuney Zheng, Xiaoyu Xu, Seungone Kim, Minxin Du, Radha Poovendran, Graham Neubig, Xiang Yue
分类: cs.AI, cs.CL
发布日期: 2025-07-01 (更新: 2025-10-20)
💡 一句话要点
研究表明数学推理能力提升不一定带来通用LLM能力提升,SFT可能导致能力遗忘。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 数学推理 监督微调 强化学习 能力迁移 泛化能力 表征学习 模型调优
📋 核心要点
- 现有LLM在数学推理任务上表现优异,但其通用问题解决能力是否同步提升仍是未知数。
- 论文通过对比不同调优方法(SFT vs. RL)对LLM通用能力的影响,探究数学推理能力的可迁移性。
- 实验表明,SFT可能导致LLM遗忘通用能力,而RL调优的模型在不同领域表现出更好的泛化性。
📝 摘要(中文)
数学推理已成为大型语言模型(LLM)进展的代表,新模型在MATH和AIME等基准测试中迅速超越人类水平。但随着数学排行榜每周都在提高,值得思考的是:这些收益是否反映了更广泛的问题解决能力,还是仅仅是狭隘的过拟合?为了回答这个问题,我们评估了20多个开放权重的推理调优模型,涵盖数学、科学问答、智能体规划、编码和标准指令跟随等广泛的任务。我们惊讶地发现,大多数在数学方面成功的模型未能将其收益转移到其他领域。为了严格研究这种现象,我们使用仅数学数据和不同的调优方法,在Qwen3-14B模型上进行了受控实验。我们发现,强化学习(RL)调优的模型在各个领域都表现出良好的泛化能力,而监督微调(SFT)调优的模型常常忘记通用能力。潜在空间表示和token空间分布偏移分析表明,SFT会引起大量的表示和输出漂移,而RL则保留了通用领域结构。我们的结果表明,需要重新思考标准的后训练方法,特别是依赖SFT蒸馏数据来推进推理模型。
🔬 方法详解
问题定义:论文旨在研究通过数学推理训练提升LLM能力后,这种能力是否能够迁移到其他非数学领域。现有方法,特别是依赖监督微调(SFT)的方法,在提升数学推理能力的同时,可能会导致模型在其他通用任务上的性能下降,即出现“能力遗忘”现象。
核心思路:论文的核心思路是通过对比不同训练方法(SFT和RL)对LLM表征空间和token空间的影响,来解释数学推理能力迁移性的差异。SFT可能导致模型过度拟合数学数据,从而改变其在通用领域的表征,而RL可能更好地保留了通用领域的结构。
技术框架:论文主要采用实验分析的方法。首先,评估了20多个开源LLM在多种任务上的性能,包括数学、科学问答、智能体规划、编码和指令跟随。然后,在Qwen3-14B模型上进行了受控实验,使用仅数学数据,分别采用SFT和RL进行训练。最后,通过分析模型在潜在空间中的表示和token空间中的分布,来解释不同训练方法对模型泛化能力的影响。
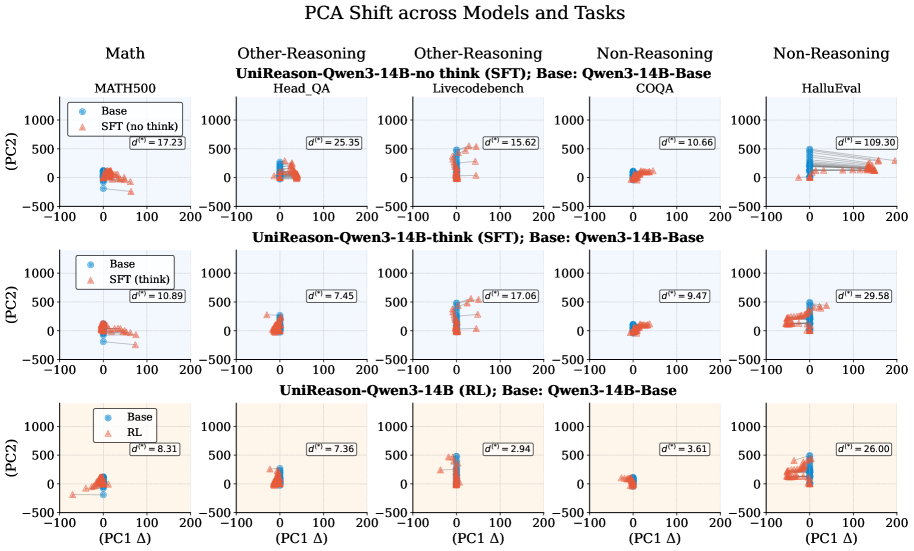
关键创新:论文的关键创新在于揭示了SFT在提升数学推理能力的同时,可能导致LLM遗忘通用能力,而RL调优的模型则表现出更好的泛化性。通过对表征空间和token空间的分析,解释了SFT和RL对模型泛化能力的不同影响。
关键设计:论文的关键设计包括:1) 选择Qwen3-14B作为基础模型,因为它具有较强的通用能力;2) 使用相同的数学数据集,分别采用SFT和RL进行训练,以控制变量;3) 使用多种评估任务,涵盖不同的领域,以全面评估模型的泛化能力;4) 通过分析潜在空间表示和token空间分布,深入理解不同训练方法对模型的影响。
🖼️ 关键图片


📊 实验亮点
实验结果表明,SFT调优的模型在数学任务上表现出色,但在其他任务上的性能显著下降,甚至低于未经训练的模型。相反,RL调优的模型在数学任务上取得了可比的结果,同时保持了在其他任务上的良好性能。表征空间和token空间分析表明,SFT导致了显著的表示和输出漂移,而RL则保留了通用领域结构。
🎯 应用场景
该研究成果对LLM的训练和调优具有重要指导意义。在提升LLM特定领域能力时,应避免过度依赖SFT,并探索更有效的训练方法,如RL,以保持模型的通用能力。这有助于开发更可靠、更通用的AI系统,应用于智能客服、教育辅导、科研助手等领域。
📄 摘要(原文)
Math reasoning has become the poster child of progress in large language models (LLMs), with new models rapidly surpassing human-level performance on benchmarks like MATH and AIME. But as math leaderboards improve week by week, it is worth asking: do these gains reflect broader problem-solving ability or just narrow overfitting? To answer this question, we evaluate over 20 open-weight reasoning-tuned models across a broad suite of tasks, including math, scientific QA, agent planning, coding, and standard instruction-following. We surprisingly find that most models that succeed in math fail to transfer their gains to other domains. To rigorously study this phenomenon, we conduct controlled experiments on Qwen3-14B models using math-only data but different tuning methods. We find that reinforcement learning (RL)-tuned models generalize well across domains, while supervised fine-tuning (SFT)-tuned models often forget general capabilities. Latent-space representation and token-space distribution shift analyses reveal that SFT induces substantial representation and output drift, while RL preserves general-domain structure. Our results suggest a need to rethink standard post-training recipes, particularly the reliance on SFT-distilled data for advancing reasoning models.