Improving Rationality in the Reasoning Process of Language Models through Self-playing Game
作者: Pinzheng Wang, Juntao Li, Zecheng Tang, Haijia Gui, Min zhang
分类: cs.AI
发布日期: 2025-06-28 (更新: 2025-07-06)
备注: Accepted by ICML 2025
💡 一句话要点
提出基于自博弈的Critic-Discernment Game,提升LLM推理过程的合理性。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 自博弈 推理合理性 Critic-Discernment Game 数学推理
📋 核心要点
- 现有大型语言模型在推理任务中表现出色,但缺乏对自身推理过程的真正理解,导致结果不可靠。
- 论文提出Critic-Discernment Game (CDG),通过自博弈的方式,让模型在批评和反批评中学习更合理的推理。
- 实验表明,CDG训练能显著提升LLM在数学推理、错误检测、自我纠正和长链推理等任务中的表现。
📝 摘要(中文)
大型语言模型(LLMs)在数学和编程等各种任务中表现出显著的推理能力。然而,最近的研究表明,即使是最好的模型也缺乏对其推理过程的真正理解。在本文中,我们探索了自博弈如何在没有人或更优模型的监督下,增强模型在推理过程中的合理性。我们设计了一个Critic-Discernment Game(CDG),其中证明者首先为给定的问题提供解决方案,然后受到对其解决方案的批评的挑战。这些批评旨在帮助或误导证明者。证明者的目标是在面对误导性评论时保持正确的答案,同时纠正对建设性反馈的错误。我们在涉及数学推理、逐步错误检测、自我纠正和长链推理的任务上的实验表明,CDG训练可以显著提高良好对齐的LLM理解其推理过程的能力。
🔬 方法详解
问题定义:现有大型语言模型在复杂推理任务中表现出一定的能力,但它们往往缺乏对自身推理过程的理解,导致结果的可靠性和可解释性不足。现有的方法难以在没有人工监督或更优模型指导的情况下,提升模型推理的合理性。
核心思路:论文的核心思路是利用自博弈的方式,让模型扮演证明者(Prover)和批评者(Critic)两种角色,通过相互对抗和学习,提升模型对自身推理过程的理解和控制能力。证明者负责给出问题的解决方案,批评者则负责对解决方案提出质疑,证明者需要根据批评者的反馈来修正或捍卫自己的答案。
技术框架:Critic-Discernment Game (CDG) 的整体框架包含两个主要角色:证明者(Prover)和批评者(Critic)。证明者负责生成问题的解决方案,批评者则负责对解决方案进行评论,评论可以是建设性的(帮助证明者纠正错误)或误导性的(试图让证明者犯错)。证明者需要根据批评者的反馈来更新自己的解决方案。整个过程通过迭代进行,直到达到预定的轮数或满足其他停止条件。
关键创新:该方法最重要的创新点在于利用自博弈的方式,在没有人工监督或更优模型指导的情况下,提升模型推理的合理性。通过让模型扮演证明者和批评者两种角色,可以有效地训练模型理解和评估自己的推理过程,从而提高结果的可靠性和可解释性。
关键设计:CDG的关键设计包括:1) 批评者的生成策略,需要平衡建设性和误导性评论的比例;2) 证明者对批评的响应机制,需要能够区分建设性和误导性评论,并采取相应的行动;3) 奖励函数的设计,需要能够激励证明者在面对误导性评论时保持正确的答案,同时纠正对建设性反馈的错误。具体的参数设置和网络结构在论文中可能未详细说明,属于未知信息。
🖼️ 关键图片

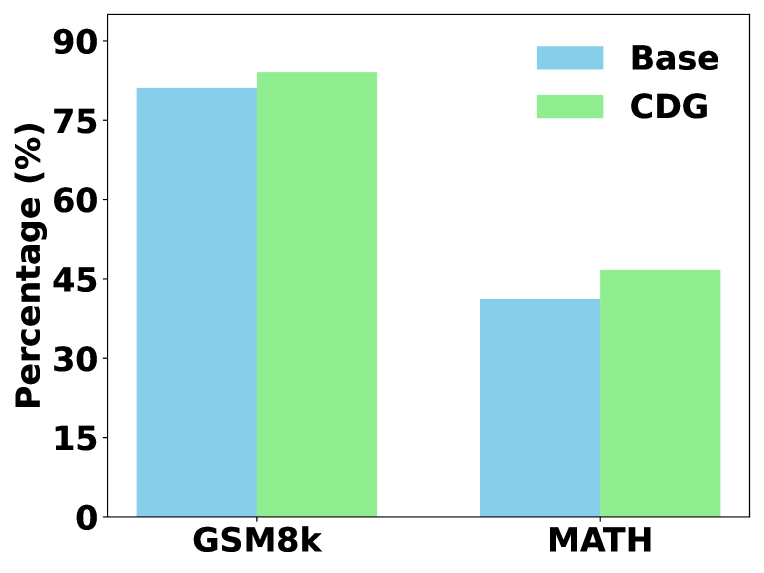
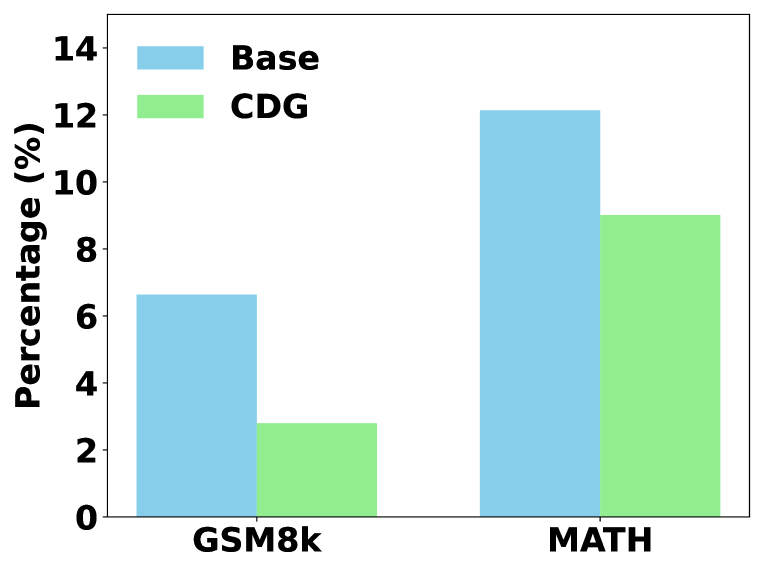
📊 实验亮点
实验结果表明,通过CDG训练,LLM在数学推理、逐步错误检测、自我纠正和长链推理等任务上的性能得到了显著提升。具体的数据提升幅度在论文中给出,证明了CDG训练能够有效提高LLM理解自身推理过程的能力。与未经过CDG训练的模型相比,经过训练的模型在面对误导性评论时,能够更好地保持正确的答案,并能够更准确地纠正自身的错误。
🎯 应用场景
该研究成果可应用于各种需要高可靠性和可解释性的推理任务,例如数学问题求解、代码生成、医疗诊断等。通过提升LLM的推理合理性,可以提高其在这些领域的应用价值,并降低出错的风险。未来,该方法有望扩展到更复杂的推理场景,并与其他技术相结合,进一步提升LLM的性能。
📄 摘要(原文)
Large language models (LLMs) have demonstrated considerable reasoning abilities in various tasks such as mathematics and coding. However, recent studies indicate that even the best models lack true comprehension of their reasoning processes. In this paper, we explore how self-play can enhance the rationality of models in the reasoning process without supervision from humans or superior models. We design a Critic-Discernment Game(CDG) in which a prover first provides a solution to a given problem and is subsequently challenged by critiques of its solution. These critiques either aim to assist or mislead the prover. The objective of the prover is to maintain the correct answer when faced with misleading comments, while correcting errors in response to constructive feedback. Our experiments on tasks involving mathematical reasoning, stepwise error detection, self-correction, and long-chain reasoning demonstrate that CDG training can significantly improve the ability of well-aligned LLMs to comprehend their reasoning process.