Offline Reinforcement Learning for Mobility Robustness Optimization
作者: Pegah Alizadeh, Anastasios Giovanidis, Pradeepa Ramachandra, Vasileios Koutsoukis, Osama Arouk
分类: cs.NI, cs.AI, cs.PF
发布日期: 2025-06-28
备注: 7 pages, double column, 4 figures, 6 tables, conference submission
💡 一句话要点
利用离线强化学习优化移动鲁棒性,提升蜂窝网络性能
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 离线强化学习 移动鲁棒性优化 蜂窝网络 决策Transformer 保守Q学习 无线通信 网络优化
📋 核心要点
- 传统MRO算法依赖人工规则,难以适应复杂多变的网络环境,优化效果有限。
- 论文提出利用离线强化学习,从历史数据中学习最优的小区个体偏移调整策略,无需在线探索。
- 实验表明,离线强化学习方法在真实网络中优于传统MRO,性能提升高达7%,并具备更强的灵活性。
📝 摘要(中文)
本文重新审视了移动鲁棒性优化(MRO)算法,并研究了使用离线强化学习来学习最优小区个体偏移调整的可能性。这些方法利用收集到的离线数据集来学习最优策略,而无需进一步探索。我们采用了一种基于序列的方法,称为决策Transformer,以及一种基于价值的方法,称为保守Q学习,来学习与原始基于规则的MRO相同的目标奖励的最优策略。使用了与故障、乒乓切换和其他切换问题相关的相同输入特征。在具有3500 MHz载波频率的真实新无线电网络上,针对包括各种用户服务类型和特定可调小区对的流量组合进行的评估表明,离线RL方法优于基于规则的MRO,提供了高达7%的改进。此外,离线RL可以使用相同的可用数据集针对不同的目标函数进行训练,从而提供优于基于规则的方法的操作灵活性。
🔬 方法详解
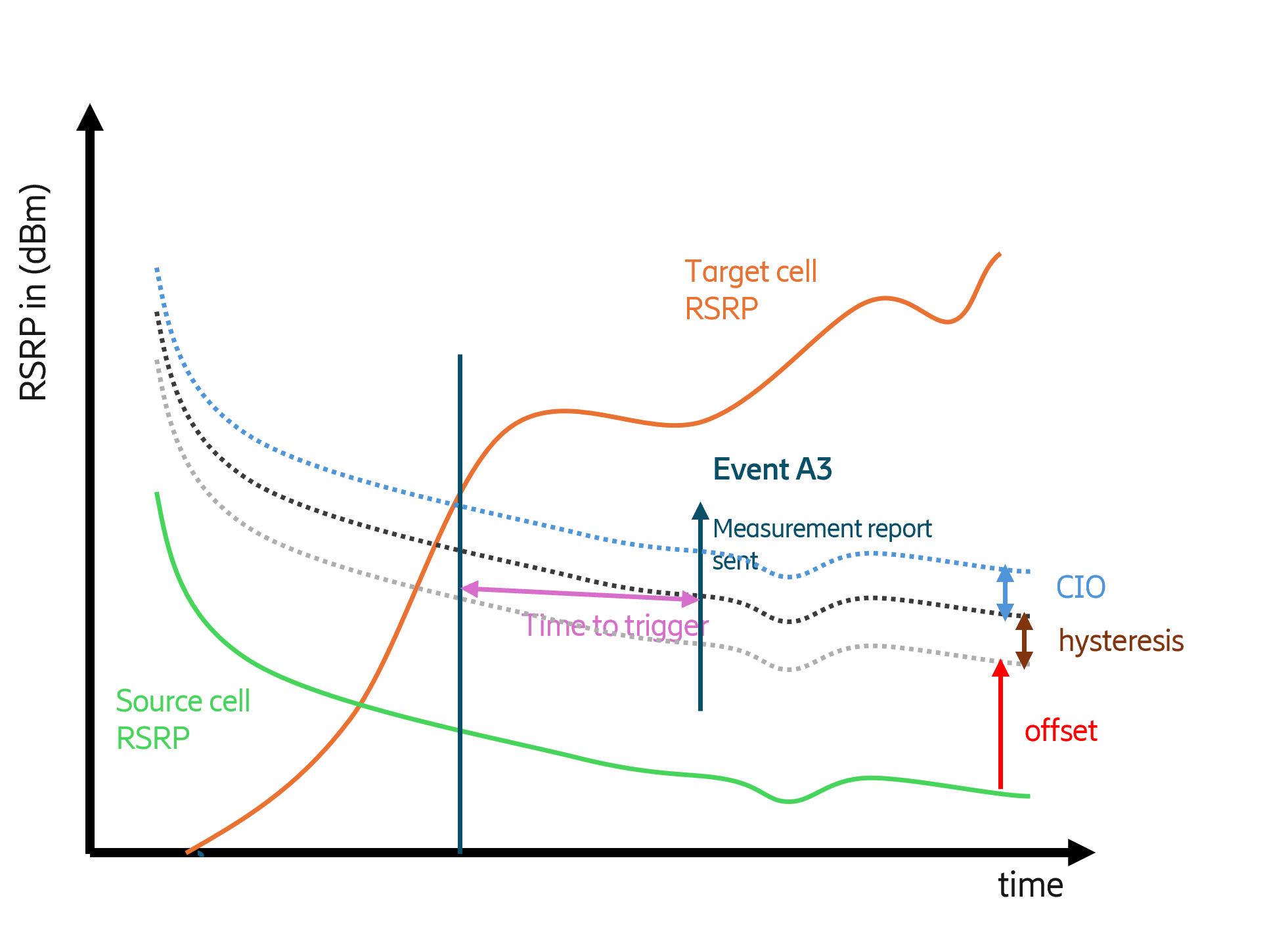
问题定义:论文旨在解决蜂窝网络中移动鲁棒性优化(MRO)问题。传统基于规则的MRO方法依赖于人工设计的启发式规则,难以适应复杂多变的网络环境,导致切换失败、乒乓切换等问题,影响用户体验和网络性能。这些规则通常需要人工调整,耗时且效果有限。
核心思路:论文的核心思路是利用离线强化学习(Offline Reinforcement Learning)从已有的网络运行数据中学习最优的MRO策略。通过将MRO问题建模为马尔可夫决策过程(MDP),并利用离线数据训练强化学习模型,可以避免在线探索带来的风险和成本,同时学习到更优的策略。
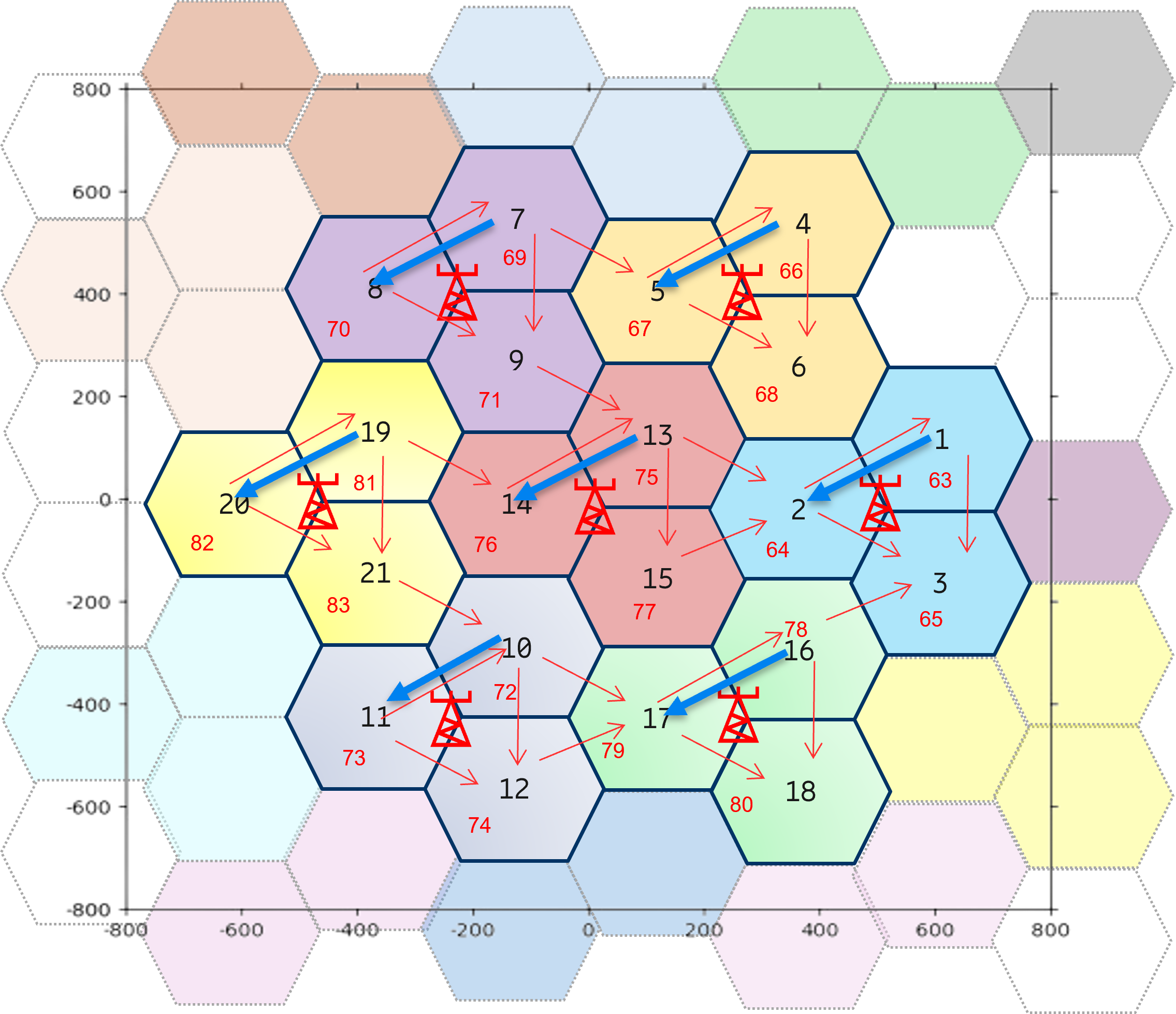
技术框架:整体框架包括数据收集、离线训练和策略部署三个阶段。首先,收集真实网络运行数据,包括切换事件、信道质量、用户位置等信息。然后,利用收集到的离线数据集,分别训练决策Transformer和保守Q学习模型。最后,将训练好的策略部署到网络中,用于指导小区个体偏移的调整。
关键创新:论文的关键创新在于将离线强化学习应用于MRO问题,并验证了其有效性。与传统的基于规则的方法相比,离线强化学习能够自动学习最优策略,无需人工干预,并且能够适应不同的网络环境和目标函数。此外,论文还比较了两种不同的离线强化学习算法(决策Transformer和保守Q学习)在MRO问题上的性能。
关键设计:论文采用了两种离线强化学习算法:决策Transformer和保守Q学习。决策Transformer是一种基于序列建模的算法,能够学习历史状态和动作之间的关系,从而预测未来的最优动作。保守Q学习是一种基于价值函数的算法,通过约束Q函数的估计,避免过度乐观的估计,从而提高策略的鲁棒性。论文使用了与故障、乒乓切换和其他切换问题相关的特征作为输入,并使用奖励函数来衡量MRO策略的性能。
🖼️ 关键图片

📊 实验亮点
实验结果表明,离线强化学习方法在真实的新无线电网络中优于传统的基于规则的MRO方法,性能提升高达7%。具体来说,离线强化学习能够显著减少切换失败和乒乓切换的次数,提高用户吞吐量和网络容量。此外,离线强化学习还能够灵活地适应不同的目标函数,例如最小化切换次数或最大化用户吞吐量。
🎯 应用场景
该研究成果可应用于各种蜂窝网络,包括4G、5G和未来的无线通信系统。通过离线强化学习优化MRO,可以显著提升网络性能,减少切换失败和乒乓切换,改善用户体验,并降低网络运维成本。此外,该方法还可以应用于其他网络优化问题,例如负载均衡、干扰管理等。
📄 摘要(原文)
In this work we revisit the Mobility Robustness Optimisation (MRO) algorithm and study the possibility of learning the optimal Cell Individual Offset tuning using offline Reinforcement Learning. Such methods make use of collected offline datasets to learn the optimal policy, without further exploration. We adapt and apply a sequence-based method called Decision Transformers as well as a value-based method called Conservative Q-Learning to learn the optimal policy for the same target reward as the vanilla rule-based MRO. The same input features related to failures, ping-pongs, and other handover issues are used. Evaluation for realistic New Radio networks with 3500 MHz carrier frequency on a traffic mix including diverse user service types and a specific tunable cell-pair shows that offline-RL methods outperform rule-based MRO, offering up to 7% improvement. Furthermore, offline-RL can be trained for diverse objective functions using the same available dataset, thus offering operational flexibility compared to rule-based methods.