Cite Pretrain: Retrieval-Free Knowledge Attribution for Large Language Models
作者: Yukun Huang, Sanxing Chen, Jian Pei, Manzil Zaheer, Bhuwan Dhingra
分类: cs.AI, cs.CL, cs.LG
发布日期: 2025-06-21 (更新: 2025-10-28)
💡 一句话要点
Cite Pretrain:通过持续预训练实现大语言模型的免检索知识归属
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 知识归属 持续预训练 主动索引 免检索 指令微调 可信赖AI
📋 核心要点
- 现有大语言模型生成引用时依赖外部检索,导致延迟高、依赖基础设施且易受检索噪声影响。
- 提出CitePretrain,通过持续预训练将知识绑定到文档标识符,实现免检索的知识归属。
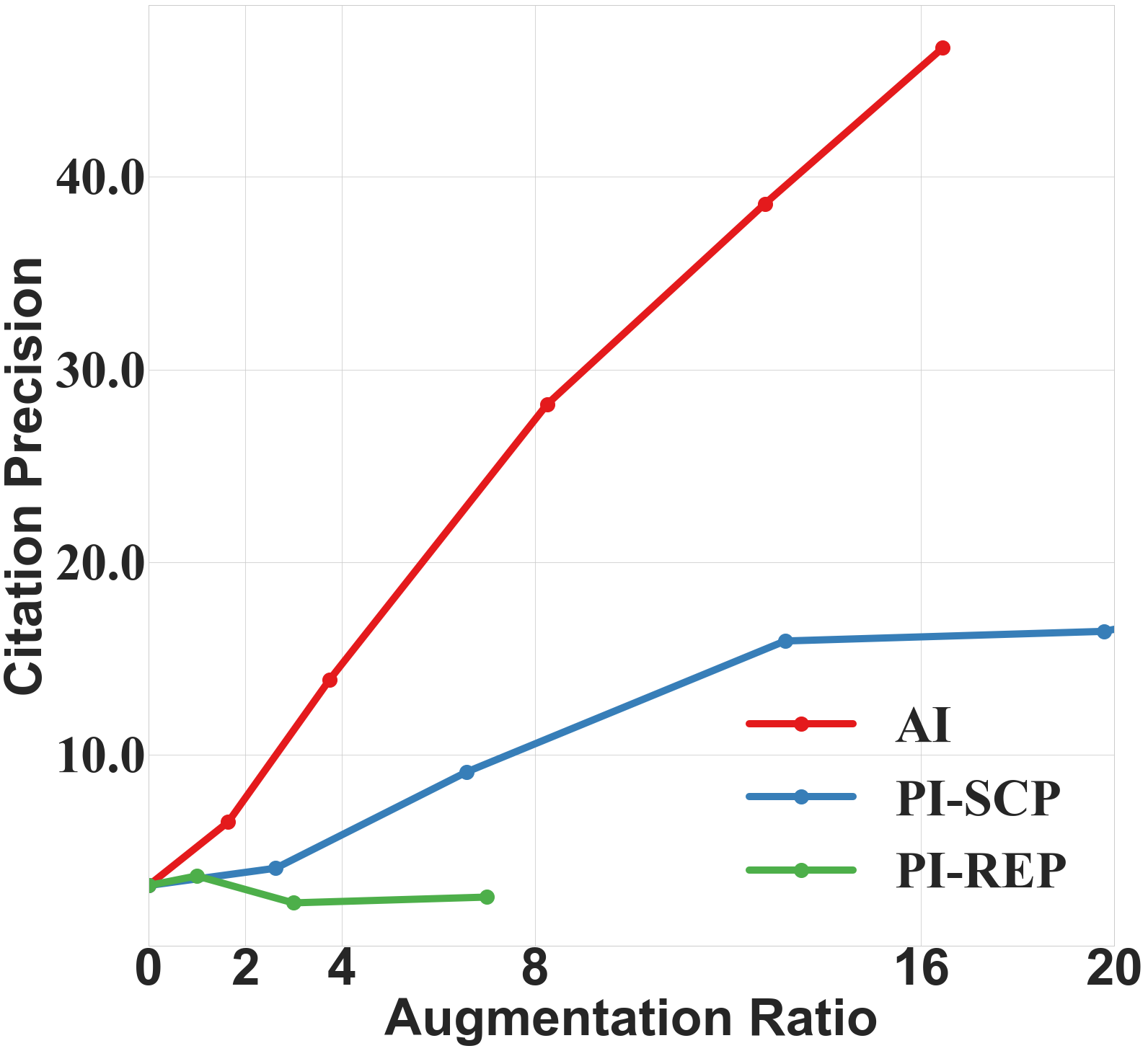
- 实验表明,主动索引方法在引用精度上优于被动索引基线,最高提升达30.2%。
📝 摘要(中文)
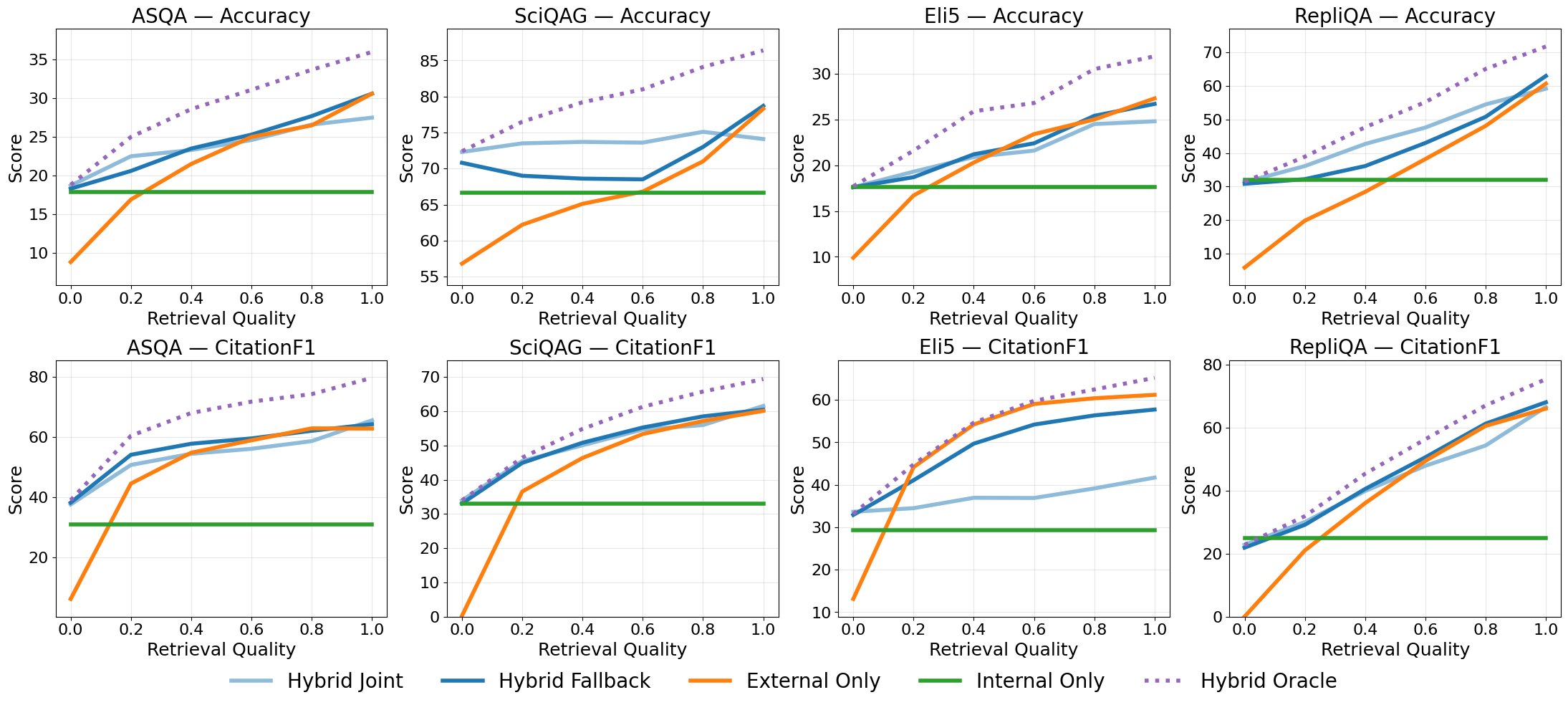
值得信赖的语言模型应该提供正确且可验证的答案。然而,独立LLM直接生成的引用通常不可靠。因此,目前的系统通过在推理时查询外部检索器来插入引用,这引入了延迟、基础设施依赖以及对检索噪声的脆弱性。本文探讨了是否可以通过修改训练过程,使LLM能够可靠地归属于在持续预训练期间看到的文档,而无需测试时检索。为此,构建了CitePretrainBench,该基准混合了真实世界的语料库(维基百科、Common Crawl、arXiv)和新的文档,并探测了短格式(单事实)和长格式(多事实)引用任务。该方法遵循一个两阶段过程:(1)持续预训练,通过将事实知识绑定到持久文档标识符来索引事实知识;(2)指令微调,以引出引用行为。引入了主动索引(Active Indexing)用于第一阶段,通过使用合成数据增强训练来创建可泛化的、源锚定的绑定,这些合成数据(i)以多种组合形式重述每个事实,并且(ii)强制执行双向训练(源到事实和事实到源)。这使得模型能够从引用的来源生成内容并归属其自身的答案,从而提高对释义和组合的鲁棒性。使用Qwen-2.5-7B&3B进行的实验表明,主动索引始终优于被动索引基线(简单地将标识符附加到每个文档),在所有任务和模型中实现了高达30.2%的引用精度提升。消融研究表明,随着增强数据量的增加,性能持续提高,即使在原始token数量的16倍时也显示出明显的上升趋势。最后,表明内部引用通过使模型对检索噪声更具鲁棒性来补充外部引用。
🔬 方法详解
问题定义:现有的大语言模型在生成需要引用的内容时,通常依赖于外部检索器来查找相关文档并生成引用。这种方法的痛点在于:推理速度慢,因为需要额外的检索步骤;依赖外部基础设施,增加了部署和维护成本;容易受到检索噪声的影响,导致引用错误或不相关。
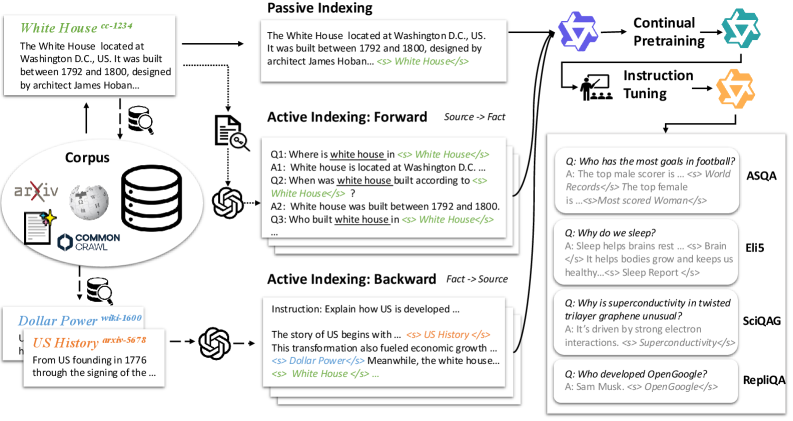
核心思路:CitePretrain的核心思路是通过在预训练阶段将知识与文档标识符绑定,使模型能够直接从自身参数中获取引用信息,而无需在推理时进行检索。这样可以提高推理速度、降低基础设施依赖,并减少检索噪声的影响。
技术框架:CitePretrain采用两阶段训练框架: 1. 持续预训练(Continual Pretraining):使用真实世界语料库和新文档,通过主动索引(Active Indexing)方法,将事实知识绑定到持久文档标识符。 2. 指令微调(Instruction Tuning):使用指令微调技术,引导模型生成带有正确引用的答案。
关键创新:CitePretrain的关键创新在于主动索引(Active Indexing)方法。与简单的被动索引(将标识符附加到文档)相比,主动索引通过合成数据增强训练,创建可泛化的、源锚定的绑定。这些合成数据以多种组合形式重述每个事实,并强制执行双向训练(源到事实和事实到源),从而提高模型对释义和组合的鲁棒性。
关键设计:主动索引的关键设计包括: 1. 合成数据生成:使用多种方式重述每个事实,例如改变句子结构、使用不同的词汇等,以增加数据的多样性。 2. 双向训练:同时训练模型从源文档生成事实,以及从事实生成源文档标识符,以增强知识绑定。 3. 损失函数:使用交叉熵损失函数来训练模型预测正确的文档标识符。
🖼️ 关键图片
📊 实验亮点
实验结果表明,主动索引方法在CitePretrainBench基准上显著优于被动索引基线。使用Qwen-2.5-7B&3B模型,主动索引在所有任务和模型中实现了高达30.2%的引用精度提升。消融研究表明,随着增强数据量的增加,性能持续提高,即使在原始token数量的16倍时也显示出明显的上升趋势。
🎯 应用场景
CitePretrain可应用于需要可靠知识归属的各种场景,例如问答系统、信息检索、内容创作等。该方法可以提高生成内容的准确性和可信度,减少错误信息的传播,并为用户提供可验证的知识来源。未来,该研究可以扩展到处理更复杂的知识结构和关系,并应用于更多领域。
📄 摘要(原文)
Trustworthy language models should provide both correct and verifiable answers. However, citations generated directly by standalone LLMs are often unreliable. As a result, current systems insert citations by querying an external retriever at inference time, introducing latency, infrastructure dependence, and vulnerability to retrieval noise. We explore whether LLMs can be made to reliably attribute to the documents seen during continual pretraining without test-time retrieval, by revising the training process. To study this, we construct CitePretrainBench, a benchmark that mixes real-world corpora (Wikipedia, Common Crawl, arXiv) with novel documents and probes both short-form (single-fact) and long-form (multi-fact) citation tasks. Our approach follows a two-stage process: (1) continual pretraining to index factual knowledge by binding it to persistent document identifiers; and (2) instruction tuning to elicit citation behavior. We introduce Active Indexing for the first stage, which creates generalizable, source-anchored bindings by augmenting training with synthetic data that (i) restate each fact in diverse, compositional forms and (ii) enforce bidirectional training (source-to-fact and fact-to-source). This equips the model to both generate content from a cited source and attribute its own answers, improving robustness to paraphrase and composition. Experiments with Qwen-2.5-7B&3B show that Active Indexing consistently outperforms a Passive Indexing baseline, which simply appends an identifier to each document, achieving citation precision gains of up to 30.2% across all tasks and models. Our ablation studies reveal that performance continues to improve as we scale the amount of augmented data, showing a clear upward trend even at 16x the original token count. Finally, we show that internal citations complement external ones by making the model more robust to retrieval noise.