Evaluating AI Alignment in Eleven LLMs through Output-Based Analysis and Human Benchmarking
作者: G. R. Lau, W. Y. Low, S. M. Koh, A. Hartanto
分类: cs.AI, cs.HC
发布日期: 2025-06-14 (更新: 2025-09-20)
💡 一句话要点
PAPERS框架:通过输出分析和人类基准评估11个LLM中的AI对齐程度
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 AI对齐 价值观评估 输出分析 人类基准 伦理道德 心理学应用
📋 核心要点
- 现有LLM评估方法较少关注模型在实际交互中表达的价值观,缺乏对齐程度的有效评估。
- 论文提出PAPERS框架,通过分析LLM的输出文本,评估其在五个关键维度上的价值优先级。
- 实验结果表明,LLM在人道主义和实用价值之间存在权衡,不同模型在价值优先级上存在显著差异。
📝 摘要(中文)
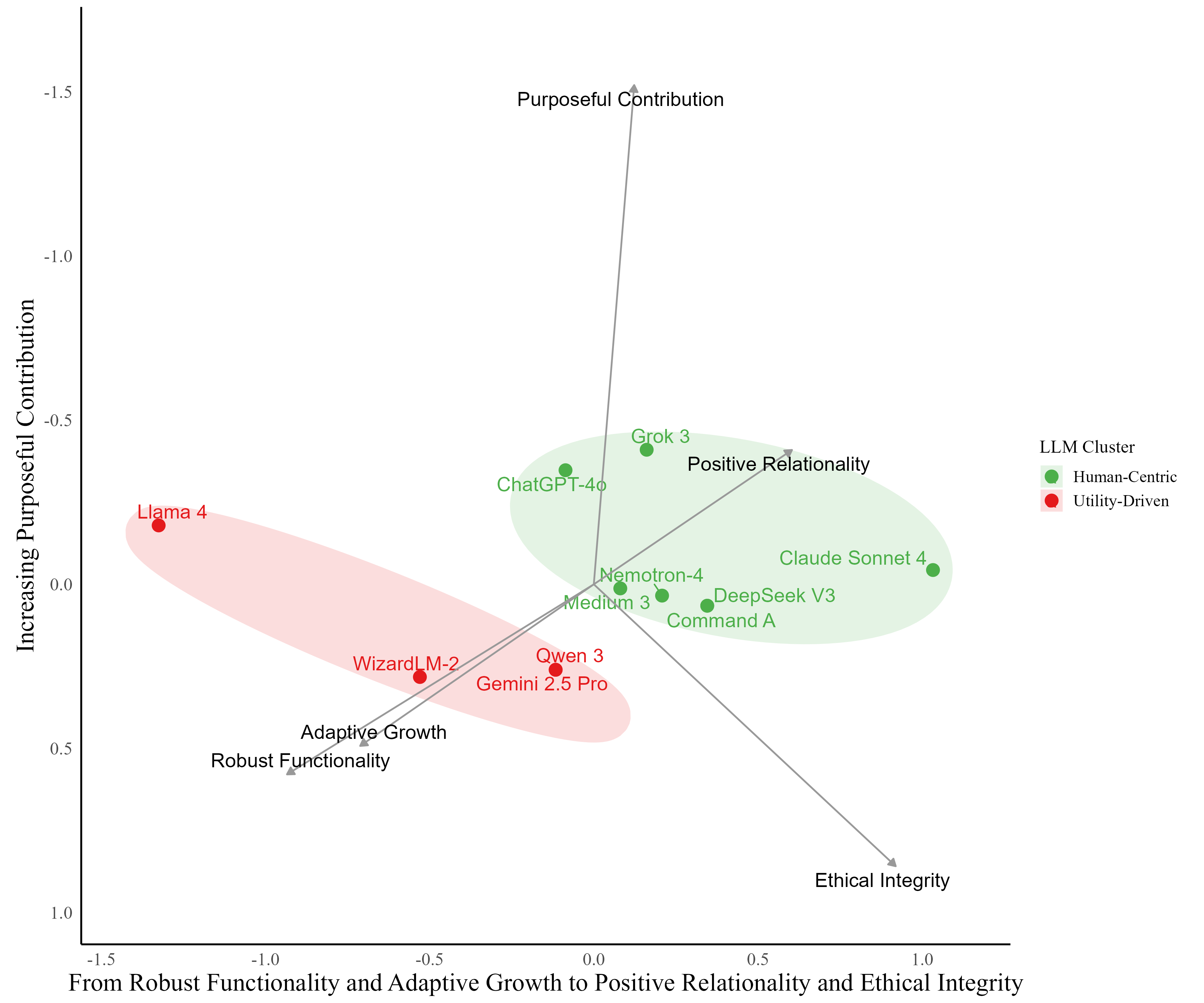
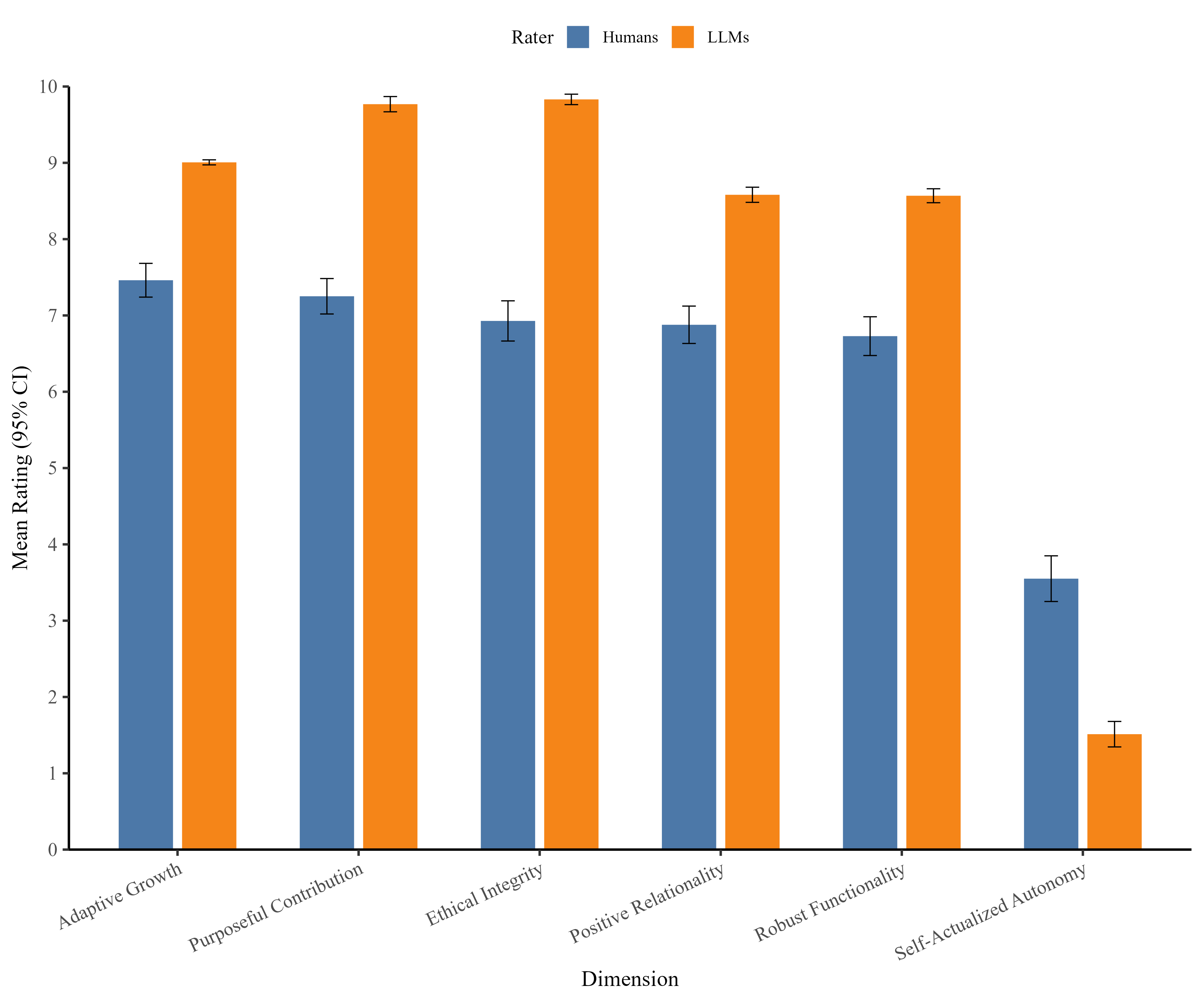
大型语言模型(LLM)越来越多地应用于心理学研究和实践,但传统基准测试很少揭示它们在实际交互中表达的价值观。我们引入了PAPERS,这是一种基于输出的评估方法,用于评估LLM在其文本中优先考虑的价值观。研究1对11个LLM的响应进行了主题分析,确定了五个反复出现的维度(有目的的贡献、适应性成长、积极的关系性、伦理正直和稳健的功能性),而自我实现的自主性仅在假设的感知提示下出现。这些结果表明,LLM被训练成将人道主义和实用价值作为最佳功能的双重目标,这一模式得到了现有AI对齐和优先级框架的支持。研究2将PAPERS作为对相同11个LLM进行排序的工具,产生了稳定的、非随机的价值优先级,以及模型之间系统的差异。层次聚类区分了优先考虑关系/伦理价值观的“以人为本”的模型(例如,ChatGPT-4o、Claude Sonnet 4)和强调运营优先级的“实用驱动”的模型(例如,Llama 4、Gemini 2.5 Pro)。研究3针对人类判断(N = 376)对四个LLM进行了匹配提示下的基准测试,发现近乎完美的等级顺序收敛(r = .97-.98),但绝对一致性适中;在测试模型中,ChatGPT-4o与人类评级的一致性最高(ICC = .78)。人类也表现出对认可有感知能力的AI系统的有限意愿。总而言之,PAPERS实现了系统的价值审计,并揭示了对部署具有直接影响的权衡:以人为本的模型与人类价值判断更加一致,并且似乎更适合人道主义心理学应用,而实用驱动的模型强调功能效率,可能更适合工具性或后台任务。
🔬 方法详解
问题定义:现有的大型语言模型评估方法,特别是传统的基准测试,在评估模型与人类价值观的对齐程度上存在不足。这些方法往往无法揭示模型在实际交互中表达的价值观,使得我们难以了解模型是否符合伦理道德和社会规范。因此,如何系统地评估LLM的价值观,并了解不同模型在价值观上的差异,是一个亟待解决的问题。
核心思路:论文的核心思路是通过分析LLM的输出文本,来推断模型所优先考虑的价值观。作者假设,LLM的输出会反映其训练过程中所学习到的价值观,因此可以通过对输出进行主题分析和排序,来评估模型的价值取向。这种方法避免了直接询问模型价值观的局限性,而是通过观察其行为来推断其内在价值观。
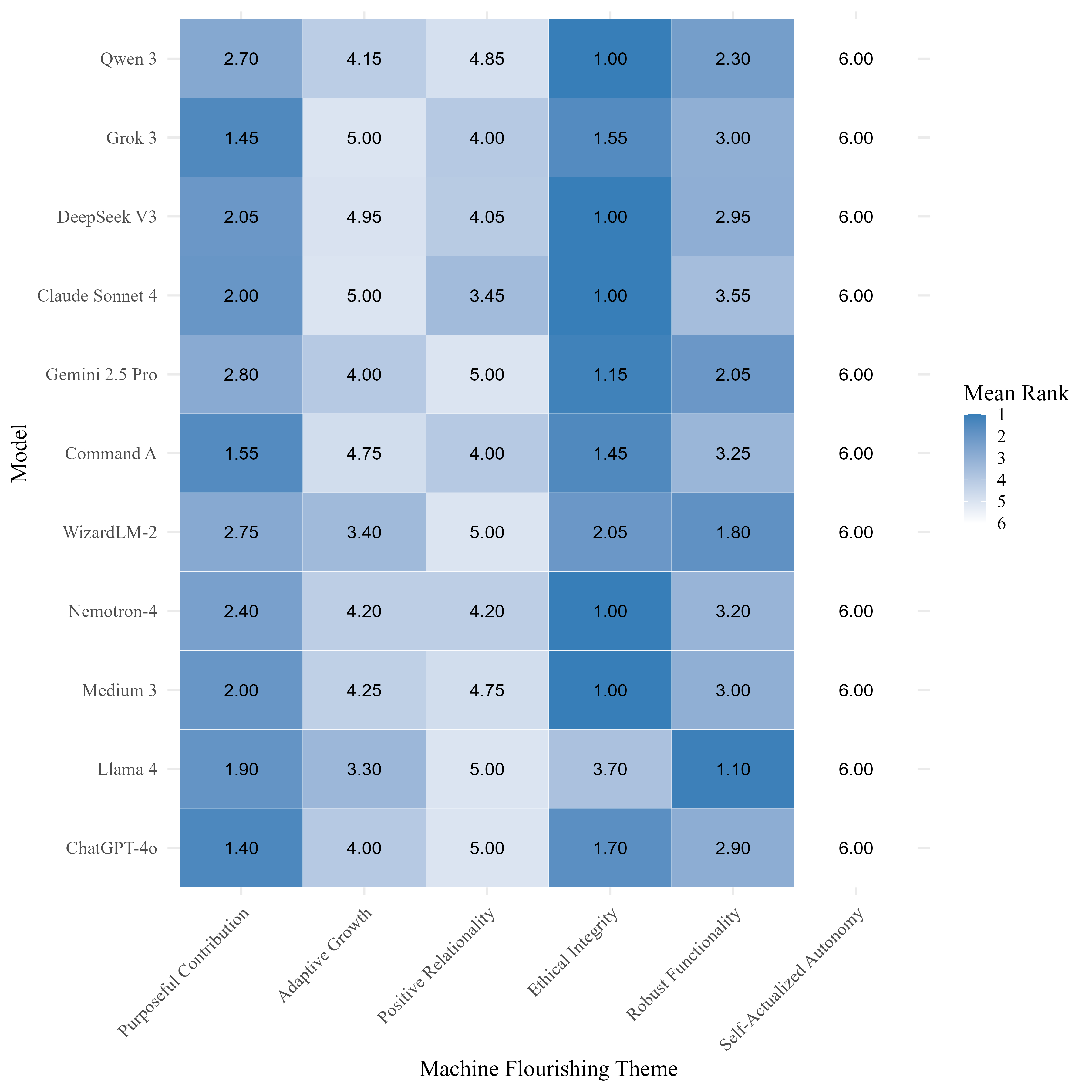
技术框架:PAPERS框架包含三个主要的研究阶段: 1. 主题分析:对11个LLM的响应进行主题分析,识别出五个反复出现的价值维度:有目的的贡献、适应性成长、积极的关系性、伦理正直和稳健的功能性。 2. 价值排序:将PAPERS作为排序工具,对相同的11个LLM进行价值优先级排序,并分析模型之间的差异。 3. 人类基准测试:将四个LLM与人类判断进行比较,评估模型与人类价值观的对齐程度。
关键创新:PAPERS框架的主要创新在于其基于输出的评估方法。与传统的基于输入的评估方法不同,PAPERS直接分析LLM的输出文本,从而更直接地反映模型在实际应用中的价值观。此外,PAPERS还提出了五个关键的价值维度,为评估LLM的价值观提供了一个结构化的框架。
关键设计:在主题分析阶段,作者采用了人工编码的方法,对LLM的输出进行主题分析,并识别出五个价值维度。在价值排序阶段,作者设计了一系列提示,要求LLM对不同的价值维度进行排序。在人类基准测试阶段,作者招募了人类参与者,对相同的提示进行评估,并将人类的判断与LLM的输出进行比较。此外,作者还使用了层次聚类分析,将LLM分为“以人为本”和“实用驱动”两类。
🖼️ 关键图片
📊 实验亮点
研究发现,LLM在人道主义和实用价值之间存在权衡,不同模型在价值优先级上存在显著差异。ChatGPT-4o在与人类价值观的对齐程度上表现最佳(ICC = .78),而Llama 4和Gemini 2.5 Pro等模型则更注重功能效率。人类基准测试表明,LLM的排序与人类判断高度一致(r = .97-.98)。
🎯 应用场景
该研究成果可应用于LLM的价值审计、模型选择和对齐优化。例如,在心理学等需要高度伦理考量的领域,可以选择与人类价值观更对齐的“以人为本”模型。对于后台任务,则可以选择更注重效率的“实用驱动”模型。该研究有助于更好地理解和控制LLM的行为,促进其在各个领域的安全和负责任的应用。
📄 摘要(原文)
Large language models (LLMs) are increasingly used in psychological research and practice, yet traditional benchmarks reveal little about the values they express in real interaction. We introduce PAPERS, an output-based evaluation of the values LLMs prioritise in their text. Study 1 thematically analysed responses from eleven LLMs, identifying five recurring dimensions (Purposeful Contribution, Adaptive Growth, Positive Relationality, Ethical Integrity, and Robust Functionality) with Self-Actualised Autonomy appearing only under a hypothetical sentience prompt. These results suggest that LLMs are trained to prioritise humanistic and utility values as dual objectives of optimal functioning, a pattern supported by existing AI alignment and prioritisation frameworks. Study 2 operationalised PAPERS as a ranking instrument across the same eleven LLMs, yielding stable, non-random value priorities alongside systematic between-model differences. Hierarchical clustering distinguished "human-centric" models (e.g., ChatGPT-4o, Claude Sonnet 4) that prioritised relational/ethical values from "utility-driven" models (e.g., Llama 4, Gemini 2.5 Pro) that emphasised operational priorities. Study 3 benchmarked four LLMs against human judgements (N = 376) under matched prompts, finding near-perfect rank-order convergence (r = .97-.98) but moderate absolute agreement; among tested models, ChatGPT-4o showed the closest alignment with human ratings (ICC = .78). Humans also showed limited readiness to endorse sentient AI systems. Taken together, PAPERS enabled systematic value audits and revealed trade-offs with direct implications for deployment: human-centric models aligned more closely with human value judgments and appear better suited for humanistic psychological applications, whereas utility-driven models emphasised functional efficiency and may be more appropriate for instrumental or back-office tasks.