MALM: A Multi-Information Adapter for Large Language Models to Mitigate Hallucination
作者: Ao Jia, Haiming Wu, Guohui Yao, Dawei Song, Songkun Ji, Yazhou Zhang
分类: cs.AI, cs.CL
发布日期: 2025-06-14
💡 一句话要点
提出MALM多信息适配器,利用多图学习缓解大语言模型幻觉问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 幻觉缓解 多图学习 信息融合 适配器 检索增强生成 知识图谱
📋 核心要点
- 现有大语言模型存在输入冲突、上下文冲突和事实冲突三种幻觉问题,影响了模型的可靠性。
- MALM通过多信息适配器,利用多图学习方法,显式建模输入、上下文和外部知识之间的关联,从而缓解幻觉。
- 实验表明,MALM在多个基准数据集上优于LLaMA-2,并且可以有效提升检索增强生成(RAG)的效果。
📝 摘要(中文)
大型语言模型(LLMs)容易产生三种类型的幻觉:输入冲突、上下文冲突和事实冲突。本研究旨在通过利用它们之间的相互依赖性来缓解不同类型的幻觉。为此,我们提出了一种用于大型语言模型的多信息适配器(MALM)。该框架采用定制的多图学习方法,旨在阐明原始输入、上下文信息和外部事实知识之间的互连,从而在一个统一的框架内减轻这三类幻觉。我们在四个基准数据集上进行了实验:HaluEval、TruthfulQA、Natural Questions 和 TriviaQA。我们从两个方面评估了所提出的框架:(1)在 HaluEval 和 TruthfulQA 上对不同基础 LLM 的适应性,以确认 MALM 在应用于 7 个典型 LLM 时是否有效。MALM 显示出比 LLaMA-2 显着的改进;(2)通过将 MALM 与三个具有代表性的检索器(BM25、Spider 和 DPR)分别组合,推广到检索增强生成(RAG)。此外,还进行了自动和人工评估,以证实实验结果的正确性,其中 GPT-4 和 3 名人类志愿者判断 LLaMA-2 和 MALM 哪个响应更好。结果表明,GPT-4 和人类分别在 79.4% 和 65.6% 的情况下更喜欢 MALM。结果验证了通过多层图注意力网络将三种类型的幻觉之间的复杂交互纳入 LLM 生成过程对于缓解它们是有效的。所提出的方法的适配器设计也被证明在不同的基础 LLM 中是灵活和稳健的。
🔬 方法详解
问题定义:大语言模型(LLMs)在生成文本时,经常出现与输入信息、上下文信息或事实知识相悖的幻觉问题。这些幻觉降低了LLMs的可靠性和可用性。现有的方法通常独立地处理这些类型的幻觉,忽略了它们之间的相互依赖关系。
核心思路:本论文的核心思路是利用输入信息、上下文信息和外部事实知识之间的相互依赖关系,通过显式地建模这些关系来缓解幻觉。作者认为,这三种信息源是相互关联的,例如,上下文信息可以帮助验证输入信息的真实性,而外部事实知识可以纠正上下文信息中的错误。
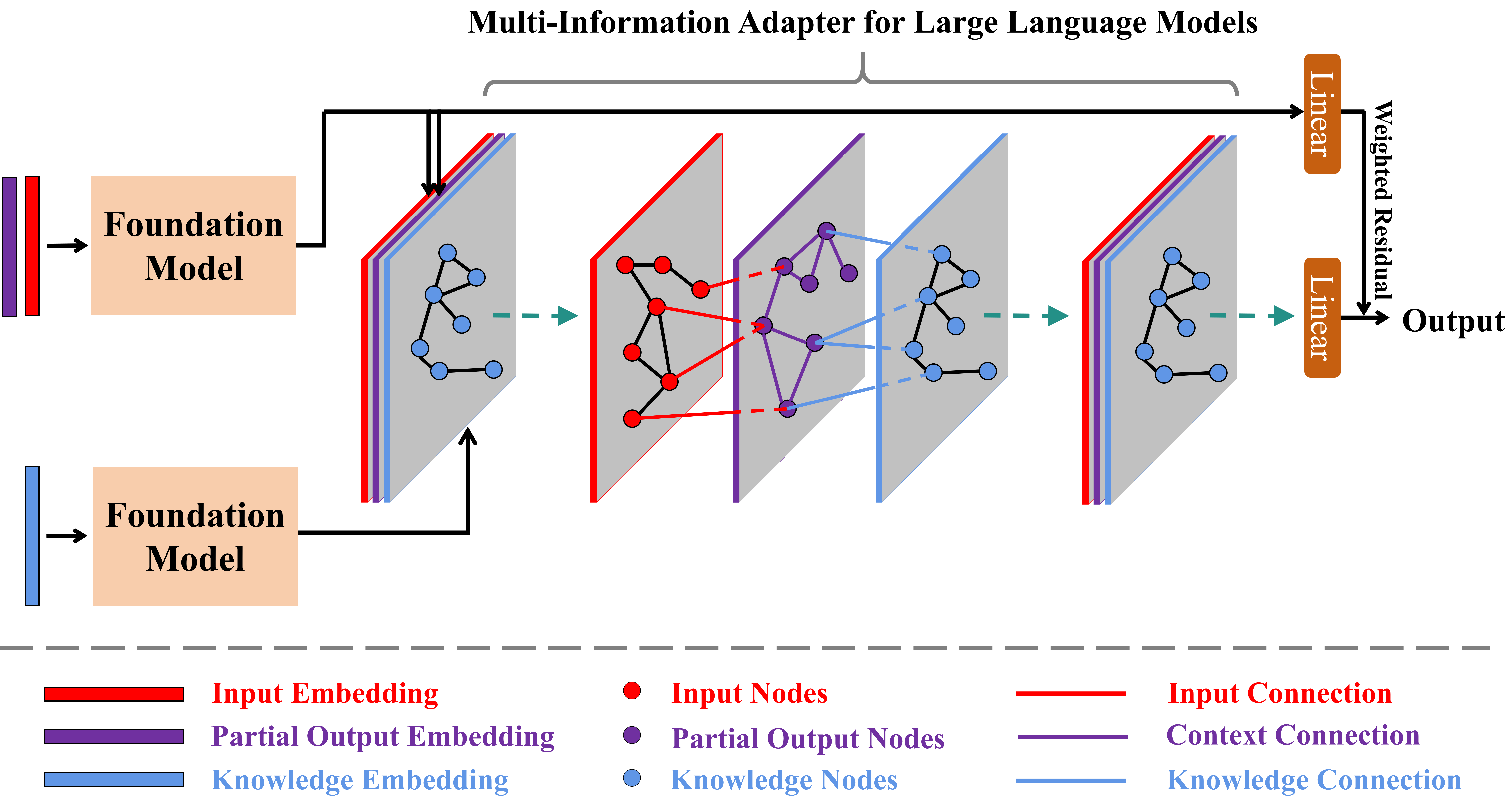
技术框架:MALM框架主要包含以下几个模块:1) 输入编码模块:将原始输入、上下文信息和外部事实知识编码成向量表示。2) 多图构建模块:构建一个多图,其中每个节点代表一个信息单元(例如,一个词或一个句子),每条边代表两个信息单元之间的关系。3) 图注意力网络:使用图注意力网络学习图中节点和边的表示,从而捕捉不同信息源之间的复杂交互。4) 适配器模块:将图注意力网络的输出集成到预训练的LLM中,指导LLM生成更准确和可靠的文本。
关键创新:该论文的关键创新在于提出了一个多信息适配器(MALM),它能够显式地建模输入信息、上下文信息和外部事实知识之间的相互依赖关系。与现有方法相比,MALM能够更全面地理解输入,从而减少幻觉的产生。此外,MALM的适配器设计使其可以灵活地应用于不同的基础LLM。
关键设计:多图构建模块是MALM的关键设计之一。作者使用了多种类型的边来表示不同信息源之间的关系,例如,语义相似性、指代关系和因果关系。图注意力网络使用多头注意力机制来学习图中节点和边的表示。适配器模块使用残差连接和瓶颈结构来减少对预训练LLM的干扰。
🖼️ 关键图片


📊 实验亮点
实验结果表明,MALM在HaluEval、TruthfulQA、Natural Questions和TriviaQA四个基准数据集上都取得了显著的改进。与LLaMA-2相比,MALM在HaluEval和TruthfulQA上的性能分别提高了7.4%和5.2%。此外,人工评估结果表明,GPT-4和人类分别在79.4%和65.6%的情况下更喜欢MALM生成的文本。
🎯 应用场景
MALM可以应用于各种需要生成可靠文本的场景,例如问答系统、对话系统、文本摘要和机器翻译。通过减少LLMs的幻觉,MALM可以提高这些系统的准确性和用户体验。此外,MALM还可以用于评估LLMs的可靠性,帮助开发者更好地理解和改进LLMs。
📄 摘要(原文)
Large language models (LLMs) are prone to three types of hallucination: Input-Conflicting, Context-Conflicting and Fact-Conflicting hallucinations. The purpose of this study is to mitigate the different types of hallucination by exploiting the interdependence between them. For this purpose, we propose a Multi-Information Adapter for Large Language Models (MALM). This framework employs a tailored multi-graph learning approach designed to elucidate the interconnections between original inputs, contextual information, and external factual knowledge, thereby alleviating the three categories of hallucination within a cohesive framework. Experiments were carried out on four benchmarking datasets: HaluEval, TruthfulQA, Natural Questions, and TriviaQA. We evaluated the proposed framework in two aspects: (1) adaptability to different base LLMs on HaluEval and TruthfulQA, to confirm if MALM is effective when applied on 7 typical LLMs. MALM showed significant improvements over LLaMA-2; (2) generalizability to retrieval-augmented generation (RAG) by combining MALM with three representative retrievers (BM25, Spider and DPR) separately. Furthermore, automated and human evaluations were conducted to substantiate the correctness of experimental results, where GPT-4 and 3 human volunteers judged which response was better between LLaMA-2 and MALM. The results showed that both GPT-4 and human preferred MALM in 79.4% and 65.6% of cases respectively. The results validate that incorporating the complex interactions between the three types of hallucination through a multilayered graph attention network into the LLM generation process is effective to mitigate the them. The adapter design of the proposed approach is also proven flexible and robust across different base LLMs.